第一代引擎:mapreduce
第二代引擎:impala(DAG)
第三代引擎:spark
第四代引擎:flink
定义
大数据的统一的计算引擎。采用 DAG来进行计算。
Spark是一种快速、通用、可扩展的大数据分析引擎
Spark部署模式
Local 多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
YarnHadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
Mesos资源调度框架。
local部署
下载最新版本:
下载历史版本:
http://archive.apache.org/dist
https://github.com/apache/spark
直接解压即可:
[root@hadoop01 local]# tar -zxvf /home/spark-2.2.0-bin-hadoop2.7.tgz -C /usr/local/
[root@hadoop01 local]# mv ./spark-2.2.0-bin-hadoop2.7/ ./spark-2.2.0
配置环境变量:
[root@hadoop01 spark-2.2.0]# vi /etc/profile
[root@hadoop01 spark-2.2.0]# source /etc/profile
[root@hadoop01 spark-2.2.0]# which spark-shell
spark-shell(命令端操作)、spark-submit(提交作业)、
spark-shell
local模式启动成功。
实现wordcount
scala> val wc=sc.parallelize(List("hello qianfeng hello bigdata hello 1906 qianfeng")).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
wc: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[3] at reduceByKey at <console>:24
scala> wc.collect()
spark的操作脚本
关系:
spark-sql的操作
spark-sql> show databases;
spark-sql> use default;
spark-sql> show tables;
spark-sql> create table if not exists test(id String);
spark-sql>
> show tables;
default test false
Time taken: 0.13 seconds, Fetched 1 row(s)
20/01/07 10:00:50 INFO CliDriver: Time taken: 0.13 seconds, Fetched 1 row(s)
帮助命令:
[root@hadoop01 spark-2.2.0]# spark-shell :help
All commands can be abbreviated, e.g., :he instead of :help.
:edit <id>|<line> edit history
:help [command] print this summary or command-specific help
:history [num] show the history (optional num is commands to show)
:h? <string> search the history
:imports [name name ...] show import history, identifying sources of names
:implicits [-v] show the implicits in scope
:javap <path|class> disassemble a file or class name
:line <id>|<line> place line(s) at the end of history
:load <path> interpret lines in a file
:paste [-raw] [path] enter paste mode or paste a file
:power enable power user mode
:quit exit the interpreter
:replay [options] reset the repl and replay all previous commands
:require <path> add a jar to the classpath
:reset [options] reset the repl to its initial state, forgetting all session entries
:save <path> save replayable session to a file
:sh <command line> run a shell command (result is implicitly => List[String])
:settings <options> update compiler options, if possible; see reset
:silent disable/enable automatic printing of results
:type [-v] <expr> display the type of an expression without evaluating it
:kind [-v] <expr> display the kind of expression's type
:warnings show the suppressed warnings from the most recent line which had any
Standalone部署
| ip | 主机名 | 服务 |
|---|---|---|
| 192.168.216.111 | hadoop01 | master、worker |
| 192.168.216.112 | hadoop02 | worker |
| 192.168.216.113 | hadoop03 | worker |
基本条件:同步时间、免密登录、关闭防火墙、安装JDK1.8
1.上传安装包到hadoop01
2.将文件解压到指定的目录
[root@hadoop01 local]# tar -zxvf /home/spark-2.2.0-bin-hadoop2.7.tgz -C /usr/local/
[root@hadoop01 local]# mv ./spark-2.2.0-bin-hadoop2.7/ ./spark-2.2.0
3.配置环境变量
配置配置文件:
[root@hadoop01 spark-2.2.0]# mv ./conf/spark-env.sh.template ./conf/spark-env.sh [root@hadoop01 spark-2.2.0]# vi ./conf/spark-env.sh 末尾追加: # mysettings JAVA_HOME=/usr/local/jdk1.8.0_152/ SPARK_MASTER_HOST=hadoop01 SPARK_MASTER_PORT=7077
配置 slaves:
[root@hadoop01 spark-2.2.0]# mv ./conf/slaves.template ./conf/slaves [root@hadoop01 spark-2.2.0]# vi ./conf/slaves 添加work的主机: hadoop01 hadoop02 hadoop03
分发:
[root@hadoop01 spark-2.2.0]# scp -r ../spark-2.2.0/ hadoop02:/usr/local/ [root@hadoop01 spark-2.2.0]# scp -r ../spark-2.2.0/ hadoop03:/usr/local/
在分发的节点去配置环境变量:
[root@hadoop01 spark-2.2.0]# scp -r /etc/profile hadoop03:/etc/ [root@hadoop01 spark-2.2.0]# scp -r /etc/profile hadoop02:/etc/ [root@hadoop02 ~]# source /etc/profile [root@hadoop03 ~]# source /etc/profile
启动测试
slaves.sh 启动slaves spark-daemon.sh 单个启动 spark-daemons.sh 多个启动 start-all.sh 全启动 start-history-server.sh 启动历史服务 start-master.sh 启动master start-slave.sh 启动小弟 start-slaves.sh 启动所有小弟 stop-all.sh 停止所有 stop-history-server.sh stop-master.sh stop-slave.sh stop-slaves.sh 测试启动: [root@hadoop01 spark-2.2.0]# ./sbin/start-all.sh 绝对路径 [root@hadoop01 spark-2.2.0]# jps 3032 Worker 3096 Jps 2969 Master 查看web-ui:SPARK_MASTER_WEBUI_PORT=8080 standalone模式看到默认8080 http://hadoop01:8080/
配置Job History Server
将历史信息存储到hdfs 1、启动hdfs 2、hdfs中创建目录 [root@hadoop01 spark-2.2.0]# hdfs dfs -mkdir -p /spark-log 3、配置历史信息 [root@hadoop01 spark-2.2.0]# mv ./conf/spark-defaults.conf.template ./conf/spark-defaults.conf [root@hadoop01 spark-2.2.0]# vi ./conf/spark-defaults.conf 追加: spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop01:9000/spark-log spark.eventLog.compress true 4、配置spark-env.sh中添加 [root@hadoop01 spark-2.2.0]# vi ./conf/spark-env.sh 追加内容: #my jobhistory setttings export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs://hadoop01:9000/spark-log" 5、启动历史服务 [root@hadoop01 spark-2.2.0]# ./sbin/start-history-server.sh [root@hadoop01 spark-2.2.0]# jps 4748 HistoryServer 6、查看历史服务的web-ui http://hadoop01:4000/
spark的架构
spark整体是呈master-slave架构,整个spark通信框架基于netty。
术语
Client:客户端进程,负责提交作业到Master。
Master:Standalone模式中主节点(老大),负责接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
Worker:Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
2.作业相关的名词解释
Stage:一个Spark作业一般包含一到多个Stage。
Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
DAGScheduler: 实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
TaskScheduler:实现Task分配到Executor上执行。
spark的HA
spark借助zk来存储协调数据。
hadoop02当成备用master启动。
#my HA settings export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01,hadoop02,hadoop03 -Dspark.deploy.zookeeper.dir=/spark" #SPARK_MASTER_HOST=hadoop01 #注释 [root@hadoop01 spark-2.2.0]# scp -r ./conf/spark-env.sh hadoop02:/usr/local/spark-2.2.0/conf/ [root@hadoop01 spark-2.2.0]# scp -r ./conf/spark-env.sh hadoop03:/usr/local/spark-2.2.0/conf/ 启动测试: 现在hadoop01启动master 在hadoop02启动master 访问备份的web-ui:
测试是否自动转移:
使用sparkshell:
ps:若使用spark-shell启动集群需要添加配置 spark-shell //使用local spark-shell --master local[*] spark-shell --master spark://hadoop01:7077 #standalone全分布式 spark-shell --master spark://hadoop01:7077,hadoop02:7077 #standalone的HA --executor-memetory --total-executor-cores
submit:
spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop01:7077,hadoop02:7077 ./examples/jars/spark-examples_2.11-2.2.0.jar spark-submit --class org.apache.spark.examples.SparkPi --executor-memory 512m --total-executor-cores 1 --master spark://hadoop01:7077,hadoop02:7077 ./examples/jars/spark-examples_2.11-2.2.0.jar /user/words /out/00 #本地或者hdfs的路径都可以 上面两个路径,在idea中,分别代表args[0]和args[1],代表两个路径
退出sparkShell “:q”
idea编写代码
代码:
package com.qianfeng.day01
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 词频统计并排序并去topN
*/
object Demo01_ScalaWC {
def main(args: Array[String]): Unit = {
//1、获取配置 类似mr中configution
/**
* .setMaster("local[*]") 本地运行设置为local,并且必须设置
* local[n] : 代表模拟n个线程来处理
* local[*] : 匹配作业的线程来处理
* .setMaster("local[*]") 集群上运行,可以不设置.setMaster()
*
* .setAppName() : 设置job名称,不设置将会随机分配
*/
val conf = new SparkConf().setMaster("local[*]").setAppName("wc_scala")
//2、创建sparkcontext对象
val sc = new SparkContext(conf)
//3、根据sc来操作数据源
val lines: RDD[String] = sc.textFile(args(0))
//4、行取扁平化
val words: RDD[String] = lines.flatMap(_.split(" "))
//5、映射元组 (hello,1)
//words.map((_,1))
val tuples: RDD[(String, Int)] = words.map(x => (x, 1))
//6、根据key来聚合
//tuples.reduceByKey(_+_)
val key_words: RDD[(String, Int)] = tuples.reduceByKey((x, y) => x + y)
//7、排序(根据values)
val sort_words: RDD[(String, Int)] = key_words.sortBy(_._2, false) //true代表升序
//8、输出
sort_words.saveAsTextFile(args(1))
println(sort_words.collect().take(2).toBuffer)
}
}
java版本的WC:
package com.qianfeng.day01;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import scala.actors.threadpool.Arrays;
import java.util.Iterator;
/**
* java版本 wc
*/
public class Demo02_JavaWC {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("java_wc");
JavaSparkContext jsc = new JavaSparkContext(conf);
//操作
JavaRDD<String> lines = jsc.textFile(args[0]);
//切分
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//映射
JavaPairRDD<String, Integer> kvs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
//聚合
JavaPairRDD<String, Integer> sum = kvs.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//排序(没有提供sortBy , 先进行kv转换)
JavaPairRDD<Integer, String> vks = sum.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> kv) throws Exception {
return new Tuple2<Integer, String>(kv._2, kv._1);
// kv.swap();
}
});
//排序
JavaPairRDD<String, Integer> sorted_kvs = vks.sortByKey().mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> vk) throws Exception {
return vk.swap();
}
});
//打印
// sorted_kvs.take(2)
// sorted_kvs.saveAsTextFile(args[1]);
System.out.println(sorted_kvs.collect());
}
}
lambda版本WC:
package com.qianfeng.day01;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* Lambda版本
*/
public class Demo03_lambda {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("java_wc");
JavaSparkContext jsc = new JavaSparkContext(conf);
//操作
JavaRDD<String> lines = jsc.textFile(args[0]);
//切分炒作
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
//映射
JavaPairRDD<String, Integer> kvs = words.mapToPair(word -> new Tuple2<String, Integer>(word, 1));
//聚合
JavaPairRDD<String, Integer> sum = kvs.reduceByKey((x, y) -> x + y);
//交换
JavaPairRDD<Integer, String> swap = sum.mapToPair(x -> x.swap());
//排序
JavaPairRDD<Integer, String> sorted = swap.sortByKey(false);
//交换
JavaPairRDD<String, Integer> res = sorted.mapToPair(x -> x.swap());
//输出
// res.saveAsTextFile(args[1]);
// res.take(2)
System.out.println(res.collect());
}
}
提交到集群运行:
1、先打包 2、上传服务器 3、提交命令 spark-submit --class com.qianfeng.day01.Demo01_ScalaWC --executor-memory 512m --total-executor-cores 1 /home/original-spark_1906-1.0.jar /home/words /home/out/03
取消打印日志:
log4j.rootCategory=ERROR, console
RDD
rdd内部不存储数据,是数据的映射,用于执行数据
Resilient Distributed Dataset (RDD) 弹性的分布式数据集。
RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。
在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值。
总结(RDD的五大特征):
1.RDD可以看做是一些列partition所组成的
2.RDD之间的依赖关系
3.算子是作用在partition之上的
4.分区器是作用在kv形式的RDD上
5.partition提供的最佳计算位置,利于数据处理的本地化即计算向数据移动而不是移动数据
Resilient:弹性的
存储的弹性:内存与磁盘的
自动切换容错的弹性:数据丢失可以
自动恢复计算的弹性:计算出错重试机制
分片的弹性:根据需要重新分片
Distribute: 分布式的
DataSets:数据集,数据的表现。
创建RDD
法一: sc.parallelize(集合) sc.makeRDD(集合) 法二: sc.textFile(路径)
基于RDD的编程
RDD支持两种操作:转化操作(Transformation)和行动操作(Action)。
RDD 的转化操作是返回一个新的 RDD的操作,比如 map()和 filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如 count() 和 first()。
转化操作(Transformation):
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。
算子练习:
sc.parallelize(List(2,35,63,1,2)).filter(_>10).collect()
sc.parallelize(List("aaac","cc","acde")).filter(_.length>3).collect()
sc.parallelize(List(1,2,3,4,5,6),2).map(f=>f.filter(_%2==0)).collect
sc.parallelize(List(1,2,3,4,5,6),2).mapPartitions(f=>f.filter(_%2==0)).collect
转换算子
transformation懒加载 。 (转变、改变的意思)
package com.qianfeng.day02
import org.apache.spark.{SparkConf, SparkContext}
/**
* 转换算子
*/
object Demo01_Transformation {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("wc_scala")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7),2)
val rdd2 = sc.parallelize(List("hello hello world","abc","def","hi"),2)
//map : 映射(当前RDD中的所有元素经过函数返回一个新的RDD)
println(rdd1.map(x=>{if(x>3) x}).collect().toBuffer)
//flatMap : 扁平化(当前RDD中的所有元素经过函数返回一个新的RDD)
println(rdd2.flatMap(f=>f.split(" ")).collect().toBuffer)
//mapPartition : 映射(RDD中的每个分区经过函数返回一个新的RDD)
println(rdd1.mapPartitions(x=>x.filter(_>3)).collect().toBuffer)
//mapPartition : 映射(RDD中的每个分区经过函数返回一个新的RDD,并且带索引) 。函数默认index=1
println(rdd2.mapPartitionsWithIndex((index,iter)=>
(iter.map(x=>{s"$index : $x"}))).collect().toBuffer)
//需要index和迭代器 res为list
println(rdd2.mapPartitionsWithIndex((index,iter)=>{
var res = ""
while(iter.hasNext) {
res += index+":"+iter.next() +" "
}
res.iterator
}).collect().toBuffer)
//mapValues : 根据值来做映射,针对key-value数据类型
println(rdd2.map(x=>(x,x.length)).mapValues(_*10).collect().toBuffer)
//glom : 将分区返回成数组,然后封装RDD中
rdd2.glom().collect().foreach(x=>println(x.toBuffer))
//keyBy : 应用函数生成键,针对集合类型.返回元组(应用函数生成键,原来的值)
println(rdd2.keyBy(_.length).collect().toBuffer)
println(rdd2.keyBy(_+".jpg").collect().toBuffer)
//求和
//groupBy : 根据函数返回值进行分组,返回迭代器,针对集合
println(rdd2.groupBy(_.length).collect().toBuffer)
println(rdd2.groupBy(_.length).collect().map(x=>(x._1,x._2.size)))
//groupByKey : 根据key,返回迭代器。针对key-value 。对每个分区进行聚合
println(rdd2.map(x=>(x.length,x)).groupByKey(1).collect().toBuffer)
println(rdd2.map(x=>(x.length,x)).groupByKey(3).collect().toBuffer)
//reduceByKey : 根据key,返回迭代器。针对key-value,可以对相同的key的值进行操作,如相加
println(rdd2.map(x=>(x.length,x)).reduceByKey(_+_).collect().toBuffer)
//foldByKey : 有初始值, 3 (abc,def)
println(rdd1.map(x=>(x,x)).foldByKey(2)(_+_).collect().toBuffer)
println(rdd2.map(x=>(x.length,x)).foldByKey("|")(_+_).collect().toBuffer)
//释放
sc.stop()
}
}
进阶算子:
package com.qianfeng.day02
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* 进阶算子:
*/
object Demo02_HigeFunction {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("wc_scala")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1,2,6,8,5,6,7),2)
val rdd2 = sc.parallelize(List("hello hello world","abc","def","hi"),2)
//排序
//sortBy : 根据函数的值来进行排序
println(rdd1.sortBy(x=>x,true).collect().toBuffer)
println(rdd2.map(x=>(x,x.length)).sortBy(x=>x._2,false).collect().toBuffer)
//sortByKey : 根据key来进行排序,针对key-value类型
println(rdd2.map(x=>(x.length,x)).sortByKey(false).collect().toBuffer)
//重分区
//repartition : 可以有小到大,也可以大道小,发生shuffle
println(rdd1.partitions.length)
println(rdd1.repartition(5).partitions.length)
//coaleacse : 默认不可以小到大,因为不发生shuffle,但是可以设置发生shuffle
println(rdd1.coalesce(5).partitions.length)
println(rdd1.coalesce(5,true).partitions.length)
println(rdd1.coalesce(1).partitions.length)
//重分区并排序
//repartitionAndSortWithinPartitions : 根据指定的分区器进行充分区并排序,shuffle时做排序
println(rdd1.map((_,1)).repartitionAndSortWithinPartitions(
new HashPartitioner(3)).collect().toBuffer)
//聚合aggregateByKey
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5),
("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
println(pairRDD.aggregateByKey(0)(math.max(_,_),_+_).collect().toBuffer)
/**
* 对每个分区作用于函数:math.max(_,_)
* 第一个分区:
* cat 0,2=2 2,5=5 =5
* mouse 0,4=4
*
* 第二个:
* cat 0,12=12
* dog 0,12=12
* mouse 0,2=2
*
* 对所有的分区作用函数:_+_
*
* cat 5+12
* mouse 4+2
* dog 12
*/
val pairRDD1 = sc.parallelize(List(("cat",2), ("cat", 5),
("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 1)
println(pairRDD1.aggregateByKey(5)(math.max(_,_),_+_).collect().toBuffer)
val pairRDD2 = sc.parallelize(List( ("cat",2), ("cat", 5),
("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 6)
println(pairRDD2.aggregateByKey(0)(math.max(_,_),_+_).collect().toBuffer)
//combinByKey
//求各个学科平均成绩
val inputrdd = sc.parallelize(Seq(
("maths", 50), ("maths", 60),
("english", 65),
("physics", 66), ("physics", 61), ("physics", 87)),
1)
//法一:注:groupbykey里面放初始值
println(inputrdd.groupByKey().map(x=>(x._1,x._2.sum*1.0/x._2.size)).collect().toBuffer)
//法二:
val rddscores= inputrdd.combineByKey(
(score)=>{
println(s"the first come value:$score")
(score,1)
},
(acc:(Int,Int),v)=>{
println(s"the next value:$v")
(acc._1+v,acc._2+1)
},
(acc1:(Int,Int),acc2:(Int,Int))=>{
//println(s"the next value:$v")
(acc1._1+acc2._1,acc1._2+acc2._2)
}
).map(x=>(x._1,x._2._1*1.0/x._2._2)).collect().toBuffer
println(rddscores)
//交集、差集、并集
val u1 = sc.parallelize(1 to 5,2)
val u2 = sc.parallelize(3 to 7,2)
println(u1.intersection(u2).collect().toBuffer) //3,4,5
println(u1.subtract(u2).collect().toBuffer) //1,2
println(u1.union(u2).collect().toBuffer) //++ 1,2,3,4,5,6,7
//distinct : 去重
println(u1.union(u2).distinct().collect().toBuffer)
//jion : 连接多个,leftOuterJoin 、 RightOuterJoin 这些用法,里面必须是以下这种形式,否则不能使用
val j1 = sc.parallelize(List((1,"zs"),(2,"ls")))
val j2 = sc.parallelize(List((1,"ww"),(1,"haoge"),(3,"cuihua")))
println(j1.join(j2).collect().toBuffer)
println(j2.leftOuterJoin(j1).collect().toBuffer)
结果:ArrayBuffer((1,(ww,Some(zs))), (1,(haoge,Some(zs))), (3,(cuihua,None)))
//cogroup : 对3个以内的rdd进行key的聚合
println(j1.cogroup(j2).collect().toBuffer)
结果:ArrayBuffer((1,(CompactBuffer(zs),CompactBuffer(ww, haoge))), (2,(CompactBuffer(ls),CompactBuffer())), (3,(CompactBuffer(),CompactBuffer(cuihua))))
//sample : 抽样 false代表取得的数据是否再放入,0.01代表取百分之多少
val s1 = sc.parallelize(1 to 1000)
println(s1.sample(false,0.01,0).collect().toBuffer)
}
}
行动算子
Action算子:向驱动器程序返回结果,并把结果写入外部系统的操作
package com.qianfeng.day02
import org.apache.spark.{SparkConf, SparkContext}
/**
* Action:
*/
object Demo03_Action {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("wc_scala")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7),2)
//统计
println(rdd1)
println(rdd1.count())
//count
println(rdd1.count())
//sum
println(rdd1.sum())
//reduce
println(rdd1.reduce(_+_))
//fold
println(rdd1.fold(0)(_+_))
//aggregate
println(rdd1.aggregate(0)(math.max(_,_),_+_))
//countByKey
val rdd2 = sc.parallelize(List("ac","abc","ac","dddd"))
println(rdd2.map(x=>(x.length,x)).countByKey())
//countByValues
println(rdd2.map(x=>(x.length,x)).countByValue())
//取值类
//first
println(rdd1.first())
//take
println(rdd1.take(2))
//takeOrder 按从小到大的顺序排好
println(rdd1.takeOrdered(2))
//takeSample
// 1、withReplacement:元素可以多次抽样(在抽样时替换)
//2、num:返回的样本的大小
//3、seed:随机数生成器的种子(建议默认,不容易控制)
println(rdd1.takeSample(true,2,))
//top
println(rdd1.top(2))
//循环
//collect
println(rdd1.collect())
//foreach
println(rdd1.foreach(print))
//保存文件
rdd1.saveAsTextFile("E:\sparkdata\out\action")
//请问如下有多少给转换和action?
println(rdd2.flatMap(_.split(" "))
.map((_,1)).reduceByKey(_+_).collect().foreach(print))
}
}
Driver和Executor
1.看了很多网上的图,大多是dirver和executor之间的图,都不涉及物理机器
如下图,本人觉得这些始终有些抽象
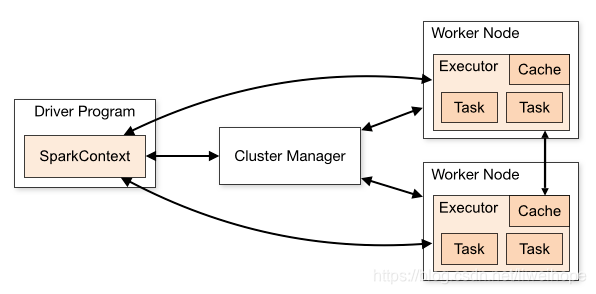
看到这样的图,我很想知道driver program在哪里啊,鬼知道?为此我自己研究了一下,网友大多都说是对的有不同想法的请评论
2.现在我有三台电脑 分别是
192.168.10.82 –>bigdata01.hzjs.co
192.168.10.83 –>bigdata02.hzjs.co
192.168.10.84 –>bigdata03.hzjs.co
- 1
- 2
- 3
集群的slaves文件配置如下:
bigdata01.hzjs.co
bigdata02.hzjs.co
bigdata03.hzjs.co
- 1
- 2
- 3
那么这三台机器都是worker节点,本集群是一个完全分布式的集群经过测试,我使用# ./start-all.sh ,那么你在哪台机器上执行的哪台机器就是7071 Master主节点进程的位置,我现在在192.168.10.84使用./start-all.sh
那么就会这样

3.那么我们来看看local模式下

现在假设我在192.168.10.84上执行了 bin]# spark-shell 那么就会在192.168.10.84产生一个SparkContext,此时84就是driver,其他woker节点(三台都是)就是产生executor的机器。如图
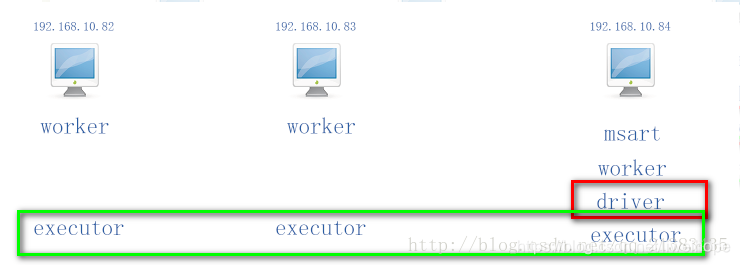
现在假设我在192.168.10.83上执行了 bin]# spark-shell 那么就会在192.168.10.83产生一个 SparkContext,此时83就是driver,其他woker节点(三台都是)就是产生executor的机器。如图

总结:在local模式下 驱动程序driver就是执行了一个Spark Application的main函数和创建Spark Context的进程,它包含了这个application的全部代码。(在那台机器运行了应用的全部代码创建了sparkContext就是drive,以可以说是你提交代码运行的那台机器)
4.那么看看cluster模式下

现在假设我在192.168.10.83上执行了 bin]# spark-shell 192.168.10.84:7077 那么就会在192.168.10.84
产生一个SparkContext,此时84就是driver,其他woker节点(三台都是)就是产生executor的机器。这
里直接指定了主节点driver是哪台机器:如图

5. 如果driver有多个,那么按照上面的规则,去判断具体在哪里
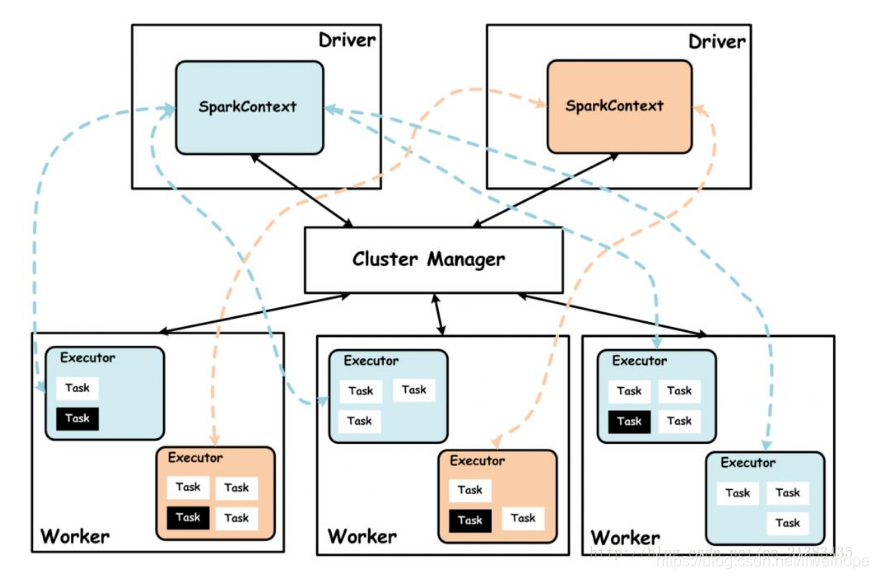
Driver:使用Driver这一概念的分布式框架有很多,比如hive,Spark中的Driver即运行Application的main()函数,并且创建SparkContext,创建SparkContext的目的是为了准了Spark应用程序的运行环境,在Spark中由SparkContext负责与ClusterManager通讯,进行资源的申请,任务的分配和监控等。当Executor部分运行完毕后,Driver同时负责将SaprkContext关闭,通常SparkContext代表Driver.
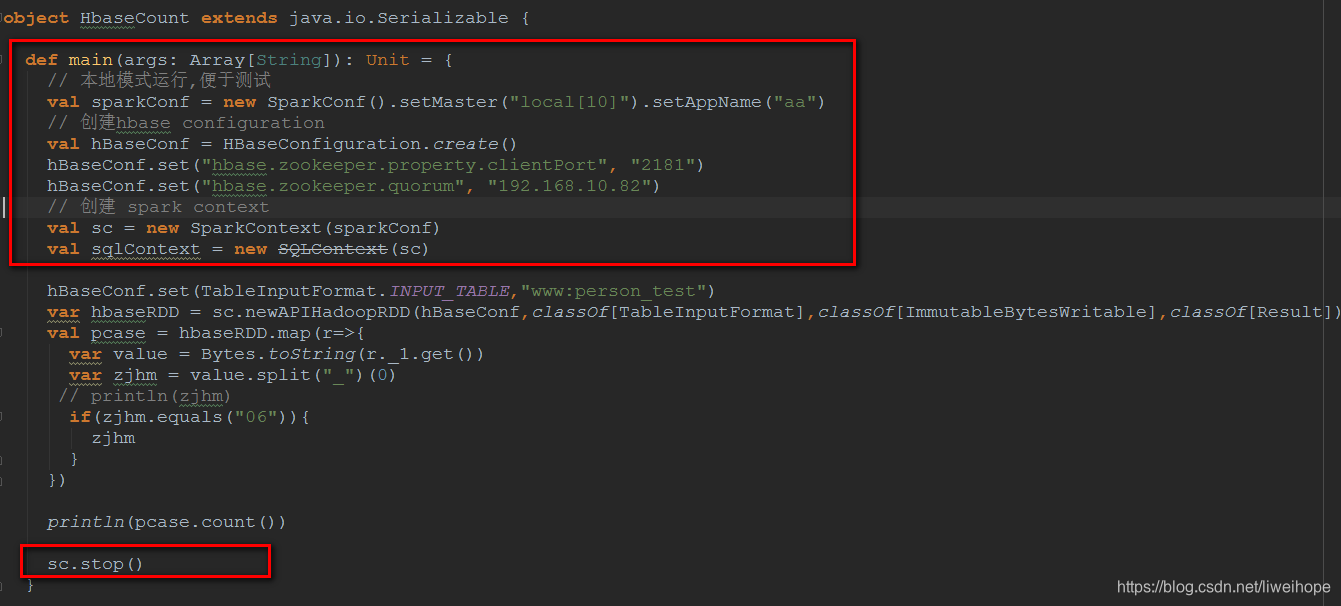
上面红色框框都属于Driver,运行在Driver端,中间没有框住的部分属于Executor,运行的每个ExecutorBackend进程中。
println(pcase.count())collect方法是Spark中Action操作,负责job的触发,因为这里有个sc.runJob()方法
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
- 1
hbaseRDD.map()属于Transformation操作。
总结:Spark Application的main方法(于SparkContext相关的代码)运行在Driver上,当用于计算的RDD触发Action动作之后,会提交Job,那么RDD就会向前追溯每一个transformation操作,直到初始的RDD开始,这之间的代码运行在Executor。