摘要:Go 能很好的在用户空间支持并发模型,这也是 Go 如此火热的原因,那今天我们来学习 Go 的调度机制。
数据结构
G 结构体
G 是 goroutine 的缩写,相当于操作系统中的进程控制块,在这里就是 goroutine 的控制结构,是对 goroutine 的抽象,下面是 G 的结构(只列出了部分与调度有关的):


//用于保存上下文的 gobuf 结构体 type gobuf struct { sp uintptr //栈指针,上下文中的 sp 指针 pc uintptr //程序计数器,上下文中的 pc 指针 g guintptr //指向当前 g 的指针 ... } //用于表示一个等待链表上的 goroutine type sudog struct { g *g //阻塞列表上的 G next *sudog //双向链表后指针 prev *sudog //双向链表前指针 elem unsafe.Pointer //该 goroutine 的数据指针 c *hchan ... }
下面是 G 结构体:
type g struct { stack stack // offset known to runtime/cgo m *m // current m; offset known to arm liblink sched gobuf //进程切换时,利用 sched 来保存上下文 param unsafe.Pointer // 用于传递参数,睡眠时其它 goroutine 设置 param, 唤醒时此 goroutine 可以获取到 goid int64 //goroutine 的 ID号 lockedm muintptr //G 被锁定只能在这个 m 上运行 gopc uintptr //创建这个goroutine 的go 表达式的 pc waiting *sudog //这个 g 当前正在阻塞的 sudog 结构体 }
M 结构体
M 是 machine 的缩写,是对机器的抽象,每个 m 都是对应到一条操作系统的物理线程。M 必须关联了 P 才可以执行 Go 代码,但是当它处理阻塞或者系统调用中时,可以不需要关联 P。
type m struct { g0 *g // 带有调度栈的 goroutine(默认开启一个进程的时候会开启一个线程,又称主线程(g0)) mstartfn func() //执行函数体的 curg *g //当前运行的 goroutine p puintptr //为了执行 Go 代码而获取的 p(如果不需要执行 Go 代码(syscall...),可为 nil) id int64 //M 的 ID locks int32 park note alllink *m //用于链接 allm(一个全局变量) schedlink muintptr lockedg guintptr //某些情况下,goroutine 锁定到当前 m, 而不会到切换到其它 m 中去 createstack [32]uintptr // stack that created this thread. nextwaitm muintptr //期望获取锁的下一个 m syscall libcall //存储系统调用的参数 }
P 结构体
P 是 Processor 的缩写。结构体 P 的加入是为了提高 Go 程序的并发度。一共有 GOMAXPROCS(一般为 CPU 的核数) 个 P, 所有的 P 被组织成一个数组(allp), 在 P 上实现了工作流窃取的调度器。
type p struct { id int32 status uint32 //P 状态 pidle/prunning/... link puintptr schedtick uint32 // 每次执行 goroutine 调度 +1 syscalltick uint32 // 每次执行系统调用 +1 sysmontick sysmontick // last tick observed by sysmon m muintptr // 链接到它的 m (nil if idle) mcache *mcache pcache pageCache // Queue of runnable goroutines. Accessed without lock. // P 执行 Go 代码时,优先从自己这个局部队列中取,这时可以不用加锁,提高了并发度 // 如果发现这个队列是空,则去其它 P 的队列中拿一半过来,实现工作流窃取的调度,这种情况需要给调度器加锁 runqhead uint32 //本地 G 队列头 runqtail uint32 //本地 G 队列尾 runq [256]guintptr //本地 G 队列 runnext guintptr //下一个准备好运行的 goroutine sudogcache []*sudog sudogbuf [128]*sudog ... }
Schedt 结构体
type schedt struct { lock mutex //获取调度器的锁,是全局性的锁(比如从全局队列获取 G, 此时必须要加锁) midle muintptr // 当前闲置的 m nmidle int32 // 闲置的 m 的个数 nmidlelocked int32 // 被锁的闲置的 m 的数量 mnext int64 // 下一个 M 的 ID maxmcount int32 // 最大允许的 M 的数量 nmsys int32 // 系统中除了死锁剩余的 M 的数量 nmfreed int64 // 将要释放的 m 的数量 ngsys uint32 // 系统中的 goroutine 的数量 pidle puintptr // 闲置的 P npidle uint32 // 闲置的 P 的数量 nmspinning uint32 // 自旋状态的 M 的个数 // Global runnable queue. runq gQueue // 全局的 goroutine 队列 runqsize int32 // 当前队列大小 }
调度策略
Go 进行并发的基本流程图:
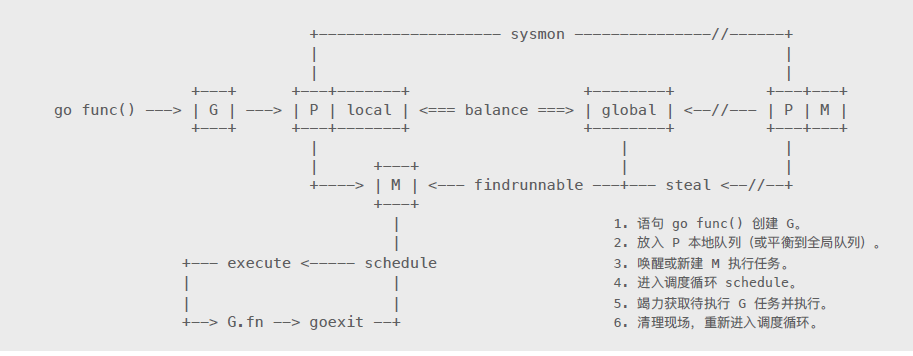
我们通过对调度源码进行分析,来定位上图中的 6 个步骤,看下具体体现:
程序入口
// from asm_amd64.s CALL runtime·args(SB) //处理参数 CALL runtime·osinit(SB) //获取 cpu 核数 CALL runtime·schedinit(SB) //调度器的初始化 // create a new goroutine to start program MOVQ $runtime·mainPC(SB), AX // entry PUSHQ AX PUSHQ $0 // arg size CALL runtime·newproc(SB) //创建一个 main goroutine POPQ AX POPQ AX // start this M CALL runtime·mstart(SB) //启动这个 main goroutine 调度系统 CALL runtime·abort(SB) // mstart should never return RET
调度入口
func mstart() { _g_ := getg() //获取当前执行的 goroutine mstart1() //主要调度在 mstart1() 中 } func mstart1() { _g_ := getg() //只有声明,没有函数实体,被编译器写入,目前只有通过注释来知道该函数的作用 if _g_ != _g_.m.g0 { throw("bad runtime·mstart") } //... if fn := _g_.m.mstartfn; fn != nil { //此处可以看到 M 中的 mstartfn 域为要执行的函数实体 fn() } if _g_.m != &m0 { acquirep(_g_.m.nextp.ptr()) _g_.m.nextp = 0 } schedule() //进行调度,是一个不会结束的函数 }
调度过程
// One round of scheduler: find a runnable goroutine and execute it. // Never returns. func schedule() { _g_ := getg() top: //... if gp == nil { // Check the global runnable queue once in a while to ensure fairness. // Otherwise two goroutines can completely occupy the local runqueue // by constantly respawning each other. if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { //每61次调度检查一下全局队列,从全局队列中取 G lock(&sched.lock) gp = globrunqget(_g_.m.p.ptr(), 1) unlock(&sched.lock) } } if gp == nil { // 从本地队列中取 G, 优先级最高 gp, inheritTime = runqget(_g_.m.p.ptr()) // We can see gp != nil here even if the M is spinning, // if checkTimers added a local goroutine via goready. } if gp == nil { // 从别的地方去获取可运行的 G,阻塞操作,直到找到可运行的 G gp, inheritTime = findrunnable() // blocks until work is available } // This thread is going to run a goroutine and is not spinning anymore, // so if it was marked as spinning we need to reset it now and potentially // start a new spinning M. if _g_.m.spinning { //如果当前 M 是自旋状态,我们需要重置它,或者开启一个新的 M resetspinning() } execute(gp, inheritTime) //开始执行 G }
寻找可运行G 的过程
// Finds a runnable goroutine to execute. // Tries to steal from other P's, get g from local or global queue, poll network. func findrunnable() (gp *g, inheritTime bool) { _g_ := getg() top: // local runq if gp, inheritTime := runqget(_p_); gp != nil { //从本地队列中获取G return gp, inheritTime } // global runq if sched.runqsize != 0 { //从全局队列中获取G lock(&sched.lock) gp := globrunqget(_p_, 0) unlock(&sched.lock) if gp != nil { return gp, false } } // 从 网络I/O 中获取 G if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { if list := netpoll(0); !list.empty() { // non-blocking gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false } } // Steal work from other P's. procs := uint32(gomaxprocs) ranTimer := false for i := 0; i < 4; i++ { for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() { if sched.gcwaiting != 0 { goto top } stealRunNextG := i > 2 // first look for ready queues with more than 1 g p2 := allp[enum.position()] //从全局变量 allp 中随机获取一个 P // 从 p2 中偷取一半的 G,返回其中一个G if gp := runqsteal(_p_, p2, stealRunNextG); gp != nil { return gp, false } } } }
执行 G 过程
// Schedules gp to run on the current M. func execute(gp *g, inheritTime bool) { _g_ := getg() // Assign gp.m before entering _Grunning so running Gs have an // M. _g_.m.curg = gp gp.m = _g_.m //绑定 M 准备运行 casgstatus(gp, _Grunnable, _Grunning) //修改 G 状态为 Grunning // 给 G 一些变量赋值 gp.waitsince = 0 gp.preempt = false gp.stackguard0 = gp.stack.lo + _StackGuard gogo(&gp.sched) // 真正执行调用的函数,sched 保存了上下文,只需要传递这个就可以执行了 } //gogo 函数用汇编实现,主要是 从 g0 stack 切换到 g stack, JMP 到任务函数执行 //from asm_amd64.s // func gogo(buf *gobuf) // restore state from Gobuf; longjmp TEXT runtime·gogo(SB), NOSPLIT, $16-8 MOVQ buf+0(FP), BX // gobuf MOVQ gobuf_g(BX), DX MOVQ 0(DX), CX // make sure g != nil get_tls(CX) MOVQ DX, g(CX) MOVQ gobuf_sp(BX), SP // restore SP MOVQ gobuf_ret(BX), AX MOVQ gobuf_ctxt(BX), DX MOVQ gobuf_bp(BX), BP MOVQ $0, gobuf_sp(BX) // clear to help garbage collector MOVQ $0, gobuf_ret(BX) MOVQ $0, gobuf_ctxt(BX) MOVQ $0, gobuf_bp(BX) MOVQ gobuf_pc(BX), BX JMP BX // longjmp 到任务函数执行
退出过程
// Finishes execution of the current goroutine. // 切换到 g0 执行退出操作 func goexit1() { //... mcall(goexit0) } // goexit continuation on g0. func goexit0(gp *g) { _g_ := getg() casgstatus(gp, _Grunning, _Gdead) // 修改 G 状态为 Gdead if isSystemGoroutine(gp, false) { atomic.Xadd(&sched.ngsys, -1) } // 重置 G 的一些域 gp.m = nil locked := gp.lockedm != 0 gp.lockedm = 0 _g_.m.lockedg = 0 gp.preemptStop = false gp.paniconfault = false gp._defer = nil // should be true already but just in case. gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data. gp.writebuf = nil gp.waitreason = 0 gp.param = nil gp.labels = nil gp.timer = nil dropg() //与 M 解绑 if GOARCH == "wasm" { // no threads yet on wasm gfput(_g_.m.p.ptr(), gp) schedule() // never returns } if _g_.m.lockedInt != 0 { print("invalid m->lockedInt = ", _g_.m.lockedInt, " ") throw("internal lockOSThread error") } gfput(_g_.m.p.ptr(), gp) // 将 G 放入本地 freelist, 如果太长,就放入全局 freelist schedule() //继续进行调度 }
小结
通过上面的过程分析,可以知道 schedule() 是一个不会结束的函数,循环的过程是:schedule() 找到可运行的 G ------> execute() 执行------>goexit() 退出------>schedule() 的循环过程,和上图中的过程一致。
源码分析
对 M 进行分析
//from go/src/runtime/proc.go func newm(fn func(), _p_ *p) { mp := allocm(_p_, fn) mp.nextp.set(_p_) mp.sigmask = initSigmask ... newm1(mp) // 调用 newm1() 创建 M } func newm1(mp *m) { ... execLock.rlock() // Prevent process clone. newosproc(mp) // 创建一个系统线程,所以我们可以把 M 看作系统线程 execLock.runlock() }
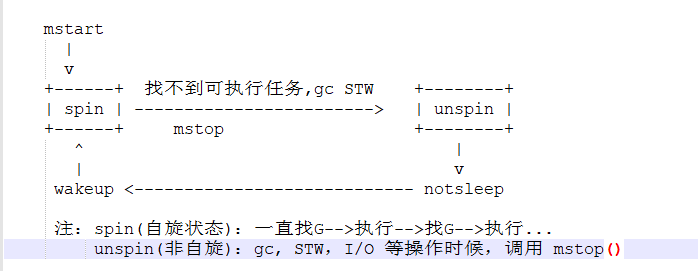
M 的状态转换:
对 P 进行分析
func procresize(nprocs int32) *p { // Grow allp if necessary. if nprocs > int32(len(allp)) { // Synchronize with retake, which could be running // concurrently since it doesn't run on a P. lock(&allpLock) if nprocs <= int32(cap(allp)) { allp = allp[:nprocs] } else { nallp := make([]*p, nprocs) //remark1: 创建 nprocs 个 p // Copy everything up to allp's cap so we // never lose old allocated Ps. copy(nallp, allp[:cap(allp)]) allp = nallp } unlock(&allpLock) } // initialize new P's //remark2: 对所有 P 进行初始化 for i := old; i < nprocs; i++ { pp := allp[i] if pp == nil { pp = new(p) } pp.init(i) atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) } //... var runnablePs *p for i := nprocs - 1; i >= 0; i-- { p := allp[i] if _g_.m.p.ptr() == p { continue } p.status = _Pidle //把当前 P 置 pidle 状态 if runqempty(p) { pidleput(p) //放入 schdet 的 pidle 空闲链表中 } else { p.m.set(mget()) //如果有可运行的 P,得到 M 进行绑定, 放入可运行链表 p.link.set(runnablePs) runnablePs = p } } return runnablePs }
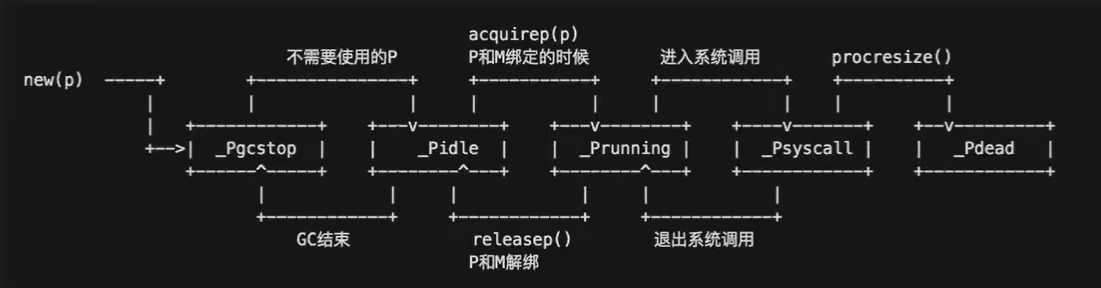
P 的状态转换:
对 G 进行分析
首先我们知道:执行 go func() ,编译器会调用 newproc() 创建一个新 goroutine, 我们看一下具体步骤:
func newproc(siz int32, fn *funcval) { argp := add(unsafe.Pointer(&fn), sys.PtrSize) gp := getg() //remark1: 获取当前的 g pc := getcallerpc() systemstack(func() { newg := newproc1(fn, argp, siz, gp, pc) // 调用 newproc1 进行生成 g _p_ := getg().m.p.ptr() runqput(_p_, newg, true) //将 G 放入 P 所在的 M 的本地队列中(也可能是全局队列) if mainStarted { wakep() } }) } //go:systemstack func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g { _g_ := getg() //获取当前运行的 goroutine, 当前 G 生成下个 G(继生代) siz := narg siz = (siz + 7) &^ 7 if siz >= _StackMin-4*sys.RegSize-sys.RegSize { //检查入参大小 throw("newproc: function arguments too large for new goroutine") } _p_ := _g_.m.p.ptr() newg := gfget(_p_) //尝试从 p 的 freelist 中获取一个 G if newg == nil { newg = malg(_StackMin) //如果获取不到,新建一个 casgstatus(newg, _Gidle, _Gdead) //置状态为 Gdead allgadd(newg) // 将新生成的 G 放入 allg } //... // 对 newG 进行初始化 newg.sched.sp = sp newg.stktopsp = sp newg.sched.pc = funcPC(goexit) + sys.PCQuantum //保存 goexit 的地址到 pc,执行完成 fn 之后,可以直接跳到 goexit 函数执行 newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn) //设置函数实体 newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) newg.startpc = fn.fn casgstatus(newg, _Gdead, _Grunnable) //更改 G 状态从 Gdead 到 Grunnable //... newg.goid = int64(_p_.goidcache) //自增 ID return newg }
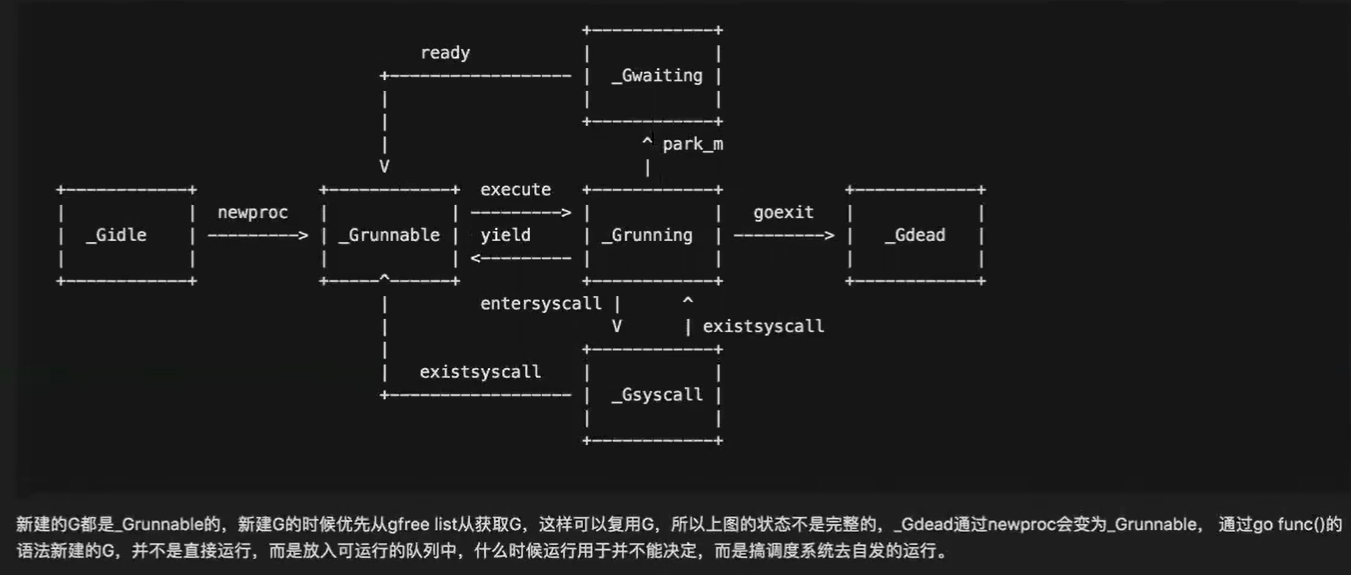
G 的状态转换:
Go为何快?
Go 非常轻量
Go 非常轻量,主要体现在如下两个方面:
1:上下文切换代价小。Goroutine 可以理解为用户空间的调度,用 sched 保存 Goroutine 的 上下文状态;而对比 OS 线程的上下文切换则需要涉及模式切换(从用户态到内核态) 更轻量;
2:内存占用少。线程栈空间通常是 2M, Goroutine 栈空间最小 2K; Golang 程序中可以轻松支持 10W 级别的 Goroutine 运行,而线程数量达到 1K 时, 内存占用就已经达到 2G。
充分利用线程的计算资源
1:任务窃取。由于现实情况是有的 Goroutine 运行的快,有的满,那么势必肯定会带来的问题就是,忙的忙死,闲的闲死,为调高整体处理效率,当每个 P 之间的 G 任务不均衡时,调度器允许从 GRQ, 或者其它 P 的 LRQ 中获取 G 运行。
2:减少阻塞。如果正在执行的 Goroutine 阻塞了线程 M 怎么办?P 上的 LRQ 中的 Goroutine 会获取不到调度么?
在 Go 里面阻塞主要分为以下四种场景:
A: 由于原子、互斥操作或通道操作导致 Goroutine 阻塞。调度器将把当前阻塞的 Goroutine 切换出去,重新调度 LRQ 上的其它 Goroutine;
B:由于网络请求和 I/O 操作导致 Goroutine 阻塞。Go 程序提供了网络轮询器(NetPoller) 来处理网络请求和 I/O 操作的问题,其后台通过 kqueue(MacOS), epoll(Linux) 或 iocp(Windows) 来实现多路复用。
C: 当调用一些系统方法的时候,如果系统方法调用的时候发生阻塞,这种情况下,NetPoller 将无法使用,进行系统调用的 Goroutine 将阻塞当前 M。调度器(Sched)将会介入, 分离 M 和 P, 同时也将 G 带走(G, M 在一起), 然后调度器引入新的 M1 来服务 P, 此时,可以从 LRQ 中选择另外的 G1 并在 M1 上进行上下文切换。
D: 如果在 Goroutine 去执行一个 sleep 操作, 导致 M 被阻塞了。Go 程序后台有一个监控线程 sysmon, 它监控哪些长时间运行的 G任务,然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行。
总结
runtime 准备好 G, M, P, 然后 M 绑定 P, M 从各种队列中获取 G, 切换到 G 的执行栈上并执行 G 上的任务函数,调用 goexit 做清理工作并回到 M, 如此反复。
参考文献
https://cloud.tencent.com/developer/article/1069239
[1] goroutine 的调度 【Go 夜读】
[2] Go1.5 源码剖析.pdf 雨痕