最近在生产环境遇到一个问题,正常情况下,ECS CPU始终保持在10%以下,内存也只占用40%左右,但是连续2天出现了CPU占用100%的情况,然后系统卡住。看阿里云的ECS监控,能看到CPU飙到了100%。
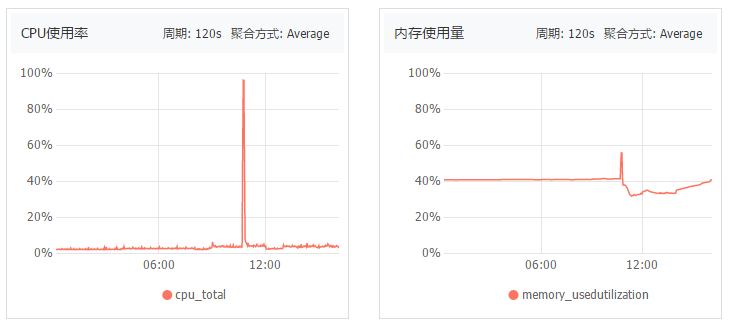
再去查日志,发现了有内存溢出的错误GC overhead limit exceeded

这个异常是GC在尝试多次回收后,都回收了不到2%才抛出。一直尝试回收,却一直回收不到2%形成了恶性循环,导致CPU也飙到100%。可以肯定的是一定触发了什么操作才导致这种情况的发生。但是日志当中又看不到具体哪一段代码有问题。所以只能去分析一下堆栈信息。利用如下命令生成heap dump:
jmap -dump:format=b,file=/data/xxxxx.bin pid
得到了一个1.8G左右的dump文件,尝试用eclipse堆内存分析插件MAT(Eclipse Memory Analyzer)打开这个dump文件,但是这个dump文件实在太大,在windows下面用eclipse打开这个文件就会报OOM错误。所以最后只能选择在linux下面用MAT去分析dump文件。去官网下载linux对应版本,地址:http://www.eclipse.org/mat/downloads.php,解压之后
![]()
MemoryAnalyzer.ini 配置文件可以修改最大的内存,稳妥一点改大点,我分配了6G,其实应该不需要这么多。执行命令:
./ParseHeapDump.sh 862.bin org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
之后会在目录下面生成分析报告
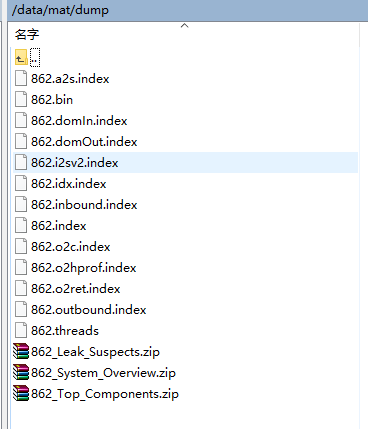
zip压缩文件里就是分析报告,除了862.bin全部下载到windows本地,然后把三个zip包解压。打开Leak_Suspects文件夹下面的index.html,结果一目了然
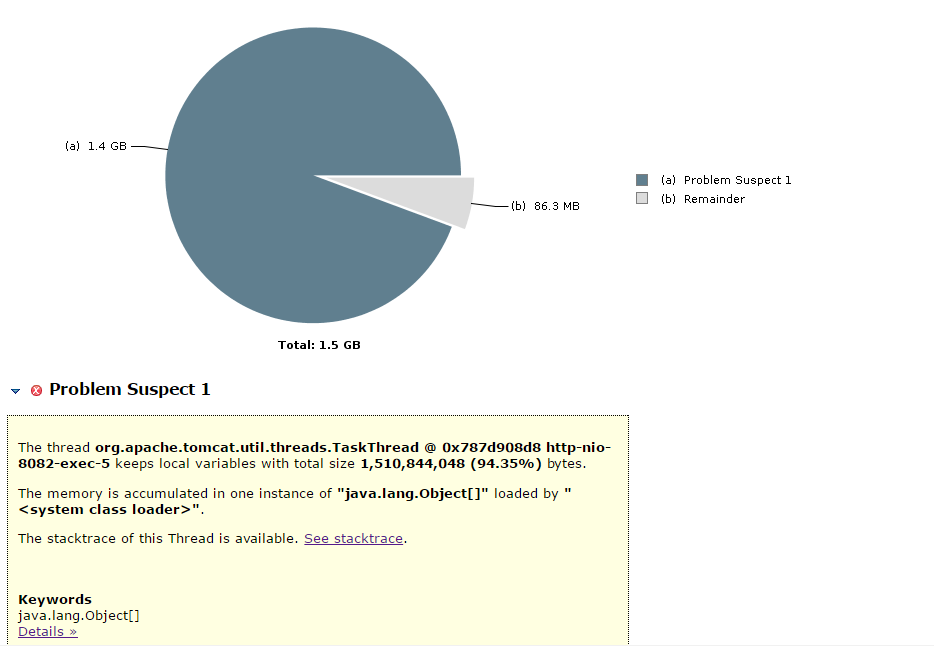
有一个线程中的对象占用了1.4G的内存,触发GC,却不能有效回收,形成恶性循环,导致CPU100%,系统崩溃。点击See stacktrace 可以看到异常日志

点击Details »可以看到对象信息
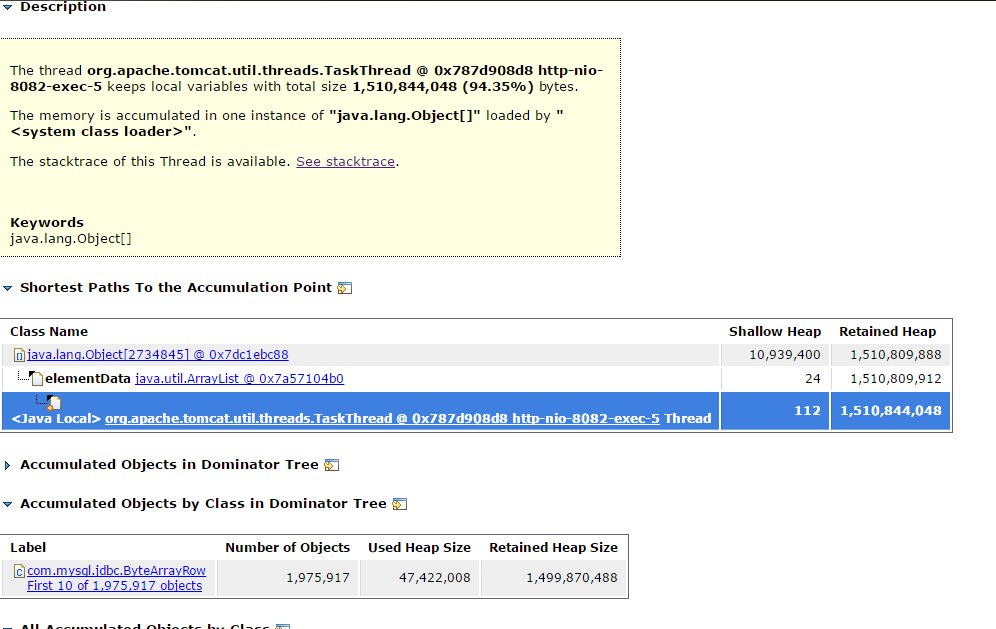
再结合代码很容易就能发现是一个查询数据库的语句把一个有几百万数据的表整个查出来了,导致内存占满引发了各种各样的问题,修改代码升级,问题解决。