一、大型互联网系统数据的存储处理



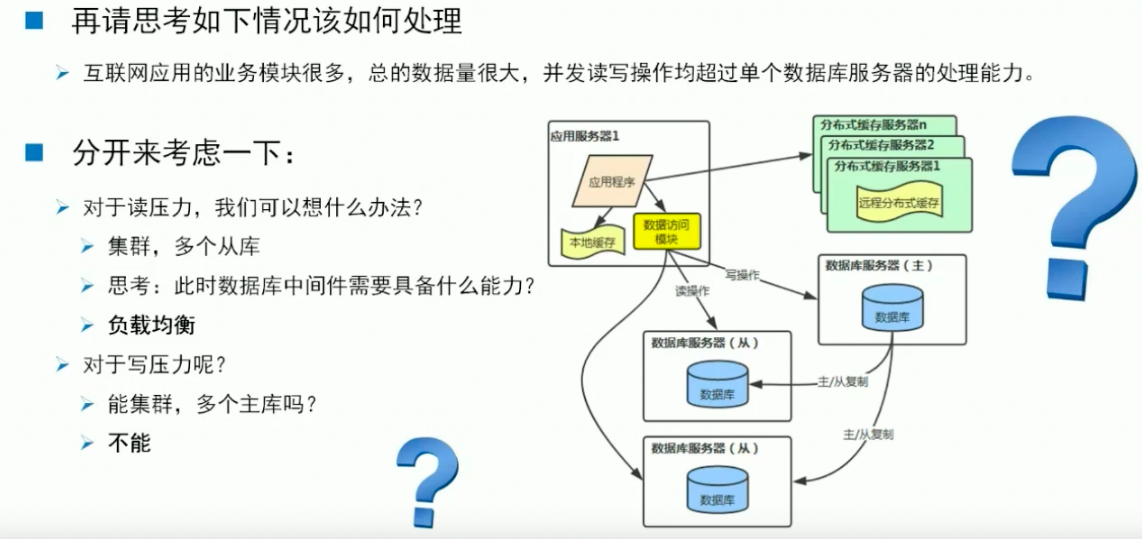
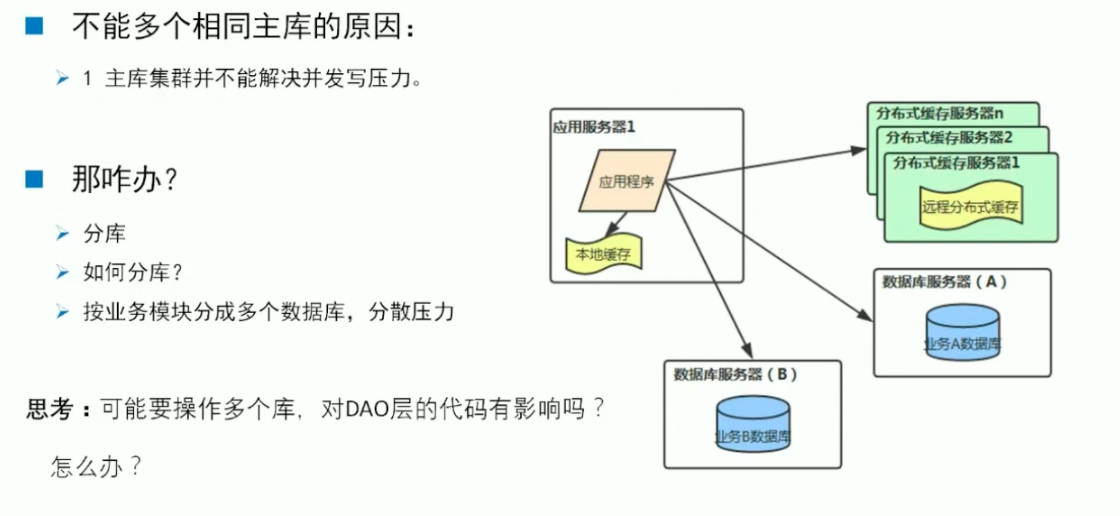
解释:主库集群并不能解决并发写的压力
因为是一个集群,集群上的每一个节点上面存的数据是要保证是一样的。在任何一台节点上去插入一条数据,最终这些数据都要同步到集群的各个节点上面去的,也就是说个个节点上面的也会进行一次写操作,所以并没有起到缓解的作用。
带来负面的影响:1.数据库的一致性,2.主键唯一性的问题

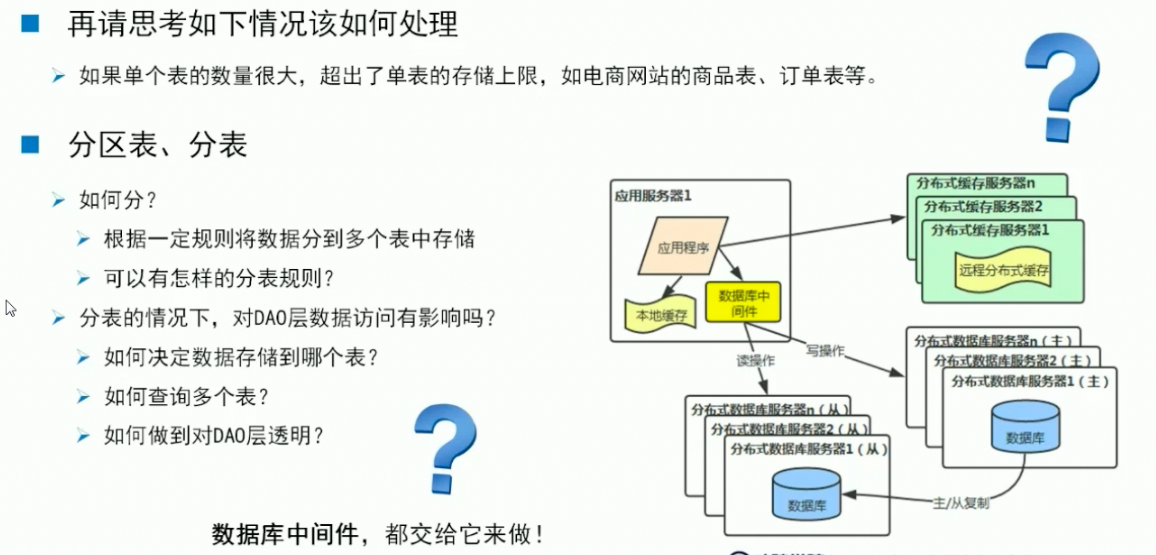
分区表和分表:
优先选择的是分区表,评估一下数据的量,有没有超出单个库的处理能力,如果没有,完全可以采用分区表的这种方式来做,因为使用分区表呢,就把处理数据的难度就交给了数据库自身来处理了。
分区表是只能在单个库里,对一个表进行分区的,那么如果并发的压力超过了单个库的处理能力,就要考虑使用分表策略了,
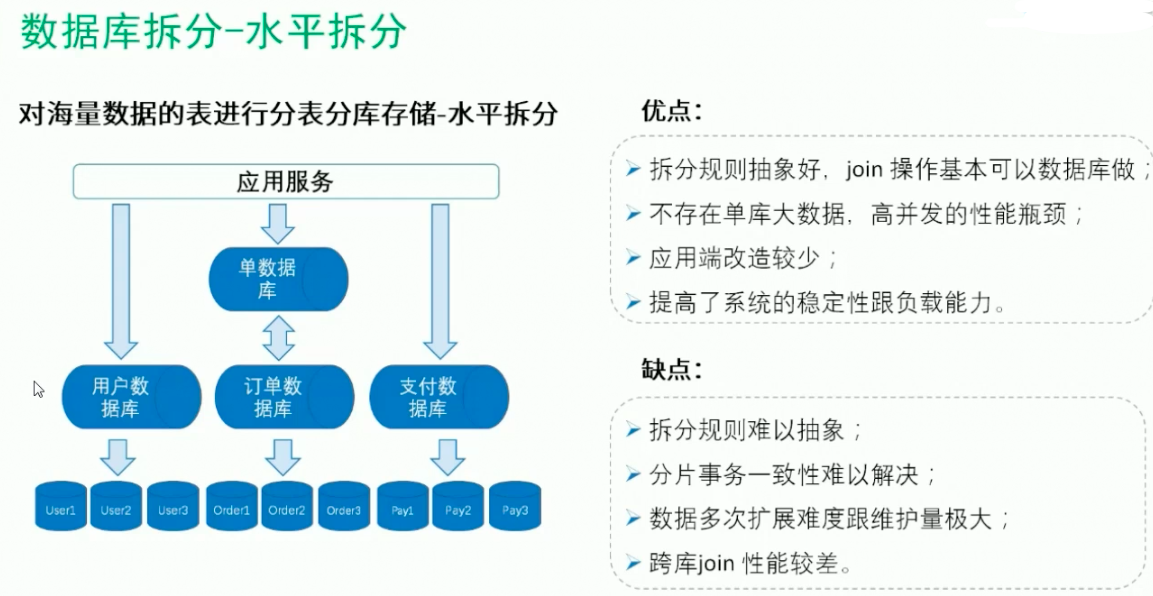
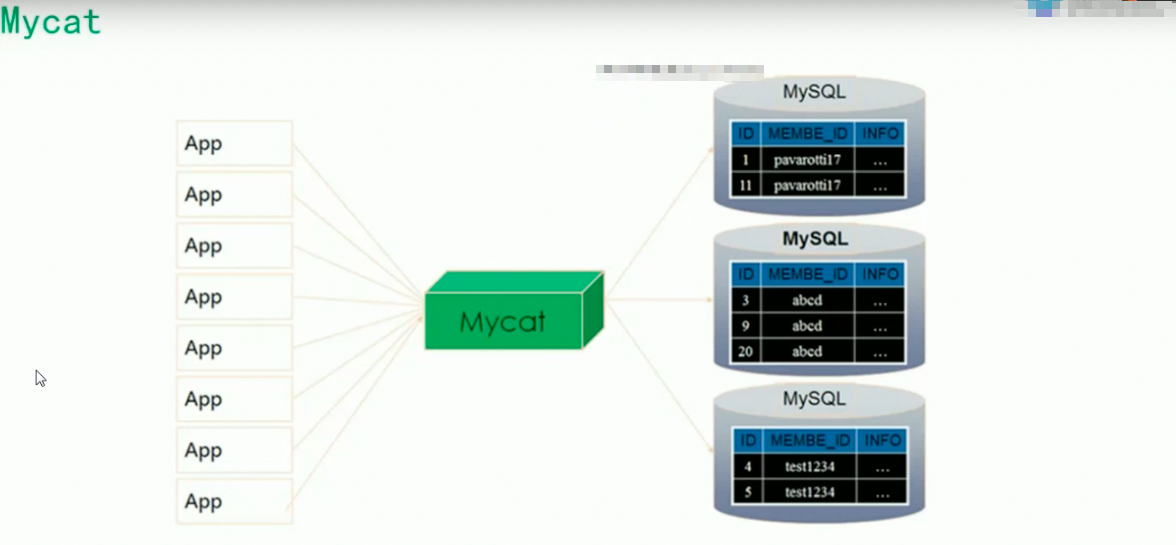
分表:指一个数据库中的某个表数据量特别大,把它拆成多个表,放到多个库上面去,分散他们的压力。
分表的规则:
1.范围分区:适合于数值型的/时间型的就可以使用范围分区
2.列表分区:比如:类型为字符串,有限个枚举这类的,如城市 就可以使用列表分区
3.散列分区:不具备 1.2特点的,考虑用散列分区,对这个值求哈希值,然后用这个值去求余或其他等操作选择合适的表
4.复合分区:是对1,2,3的综合使用
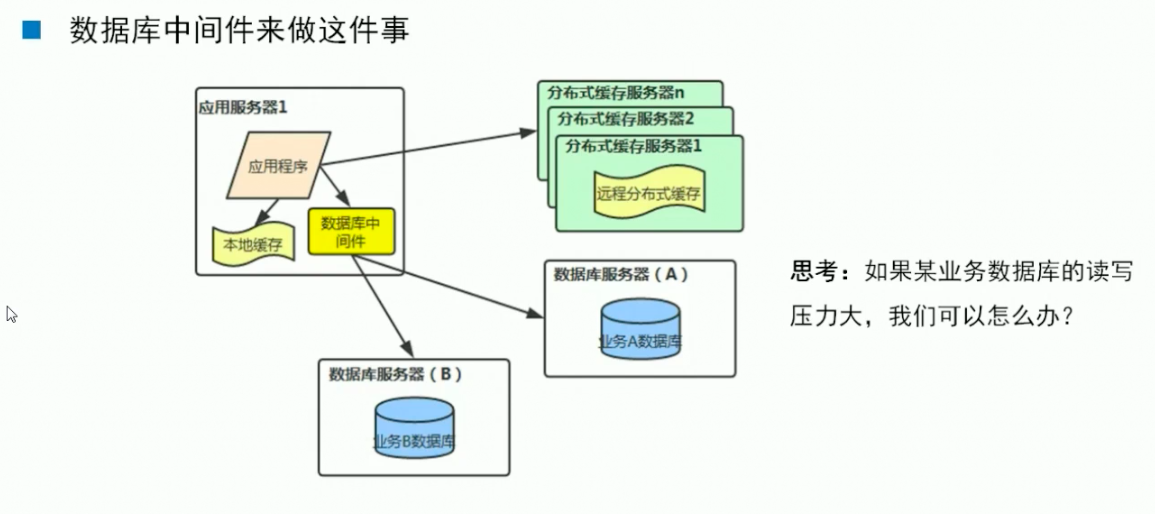
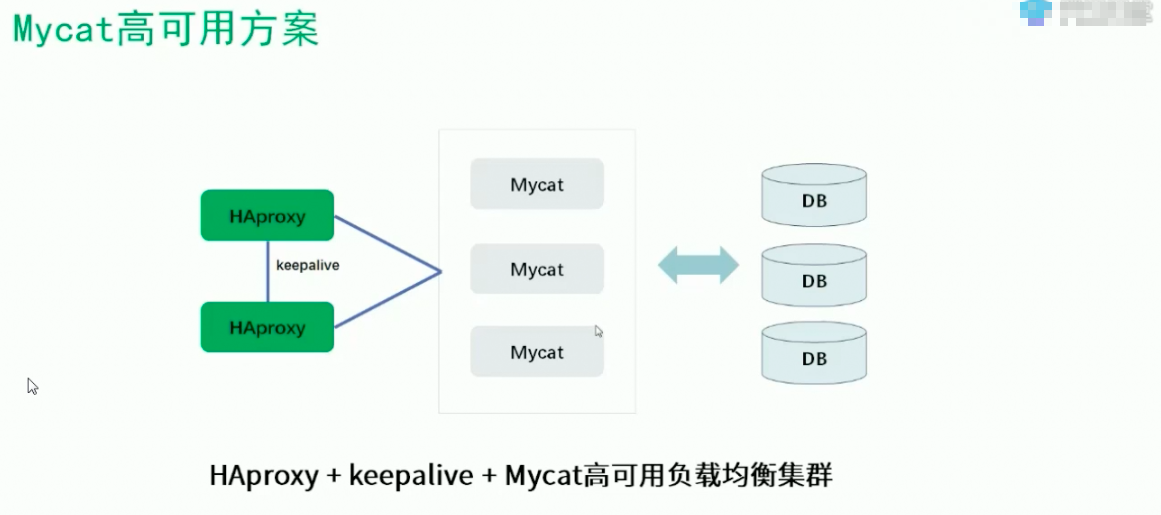
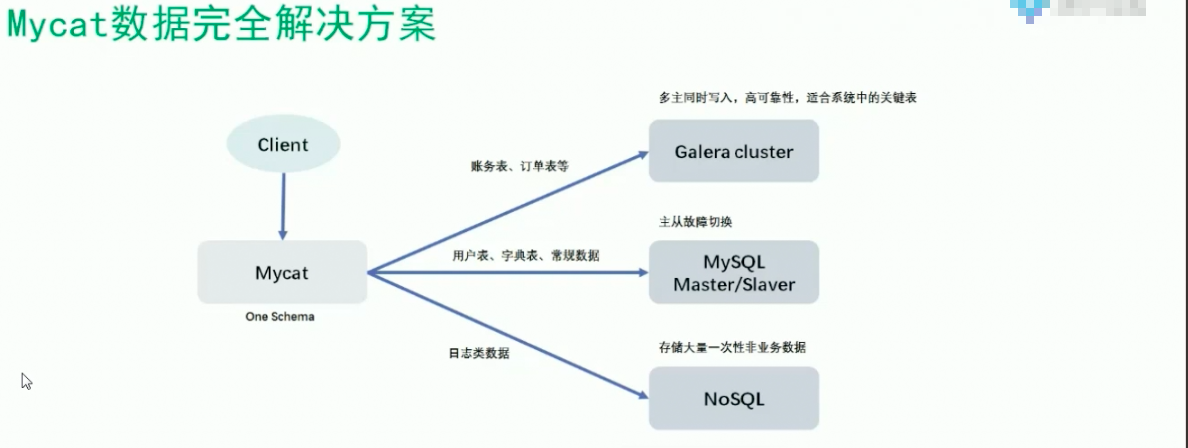
数据库中间件:能够帮我们屏蔽掉后段数据存储的变化带来对上层代码的影响,
总结:

[注]:分布式数据库:就是Mysql数据库构成的,分库,分表的,读写分离的集群
二、方案选型
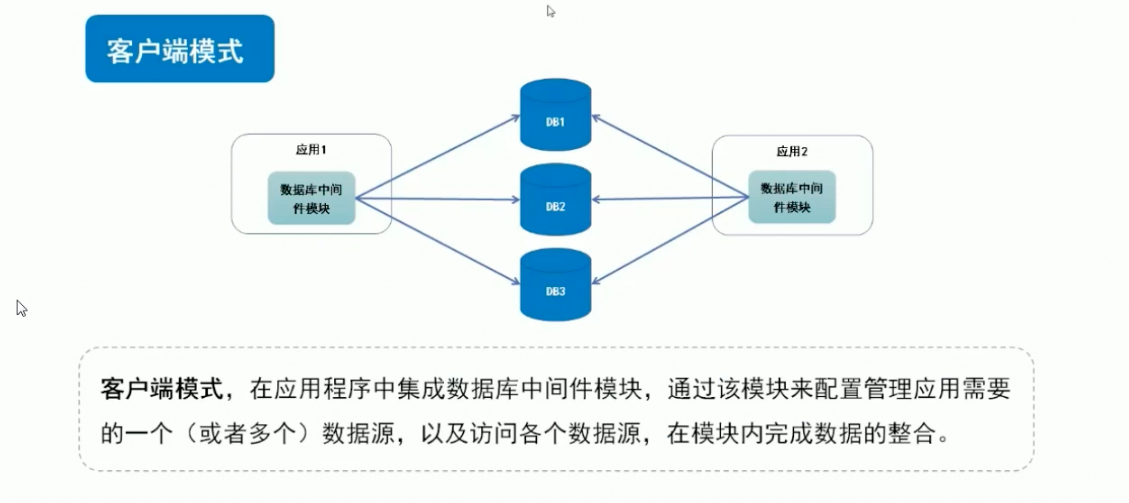
1.数据库中间件的两种实现模式:
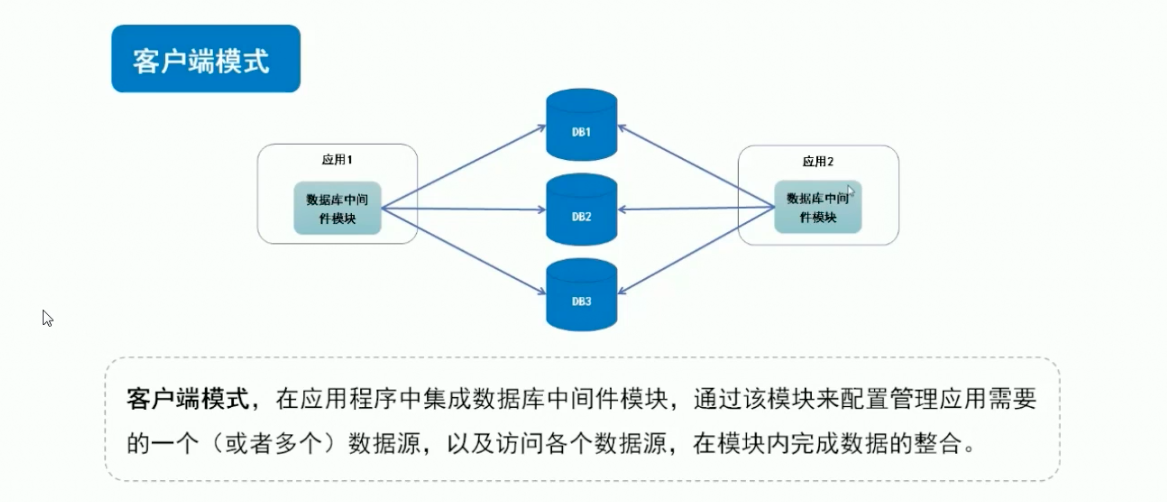
客户端模式:吃内存(与应用争内存),不适用海量数据的存储,但是适用于高并发的场景
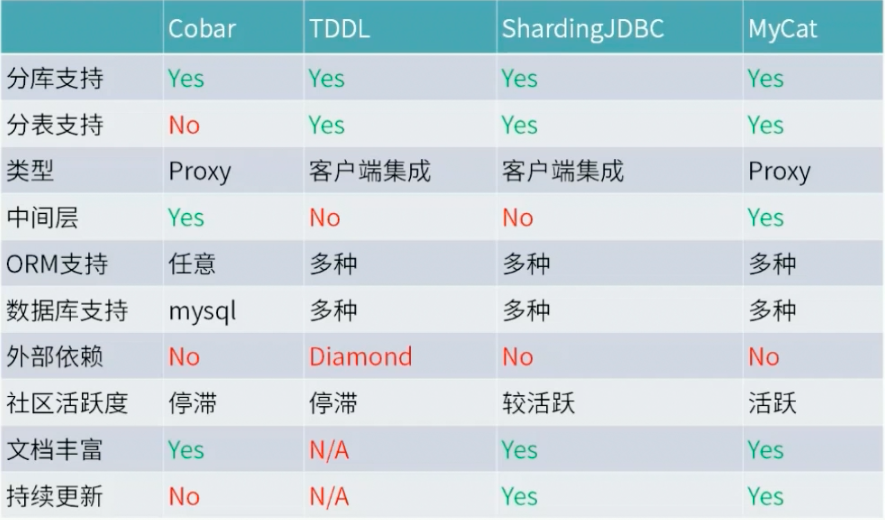
2.常用的数据库中间件

三、分布式数据库原理、技术难点
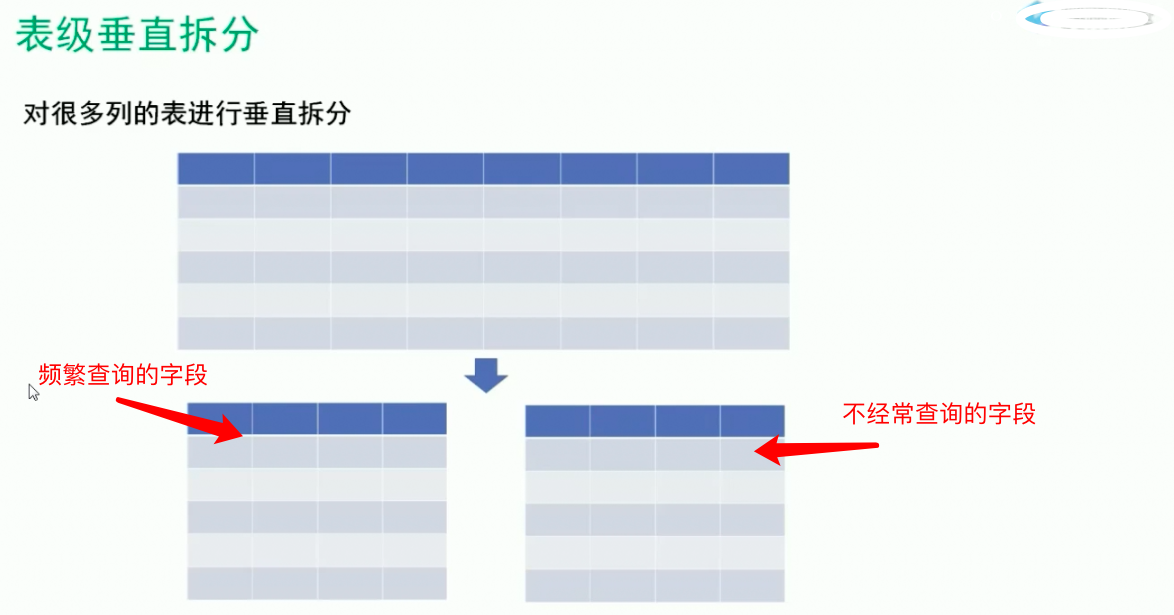
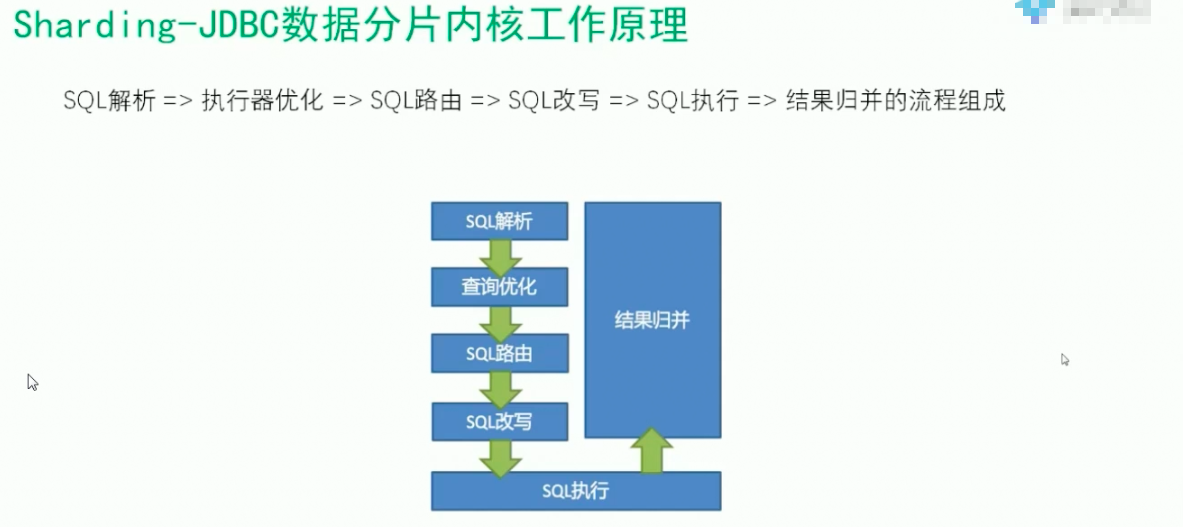
1.数据库拆分:





四、高级技能