(没太听明白,下次重新听)
1. 增强学习
有一个 Agent 和 Environment 交互。在 t 时刻,Agent 获知状态是 st,做出动作是 at;Environment 一方面给出 Reward 信号 rt,另一方面改变状态至 st+1;Agent 获得 rt 和 st+1。目标是 Agent 学习 st 到 at 的某种映射 π* 最大化累积的 Reward,∑γtrt,其中 γt 是折现系数(discount factor)。
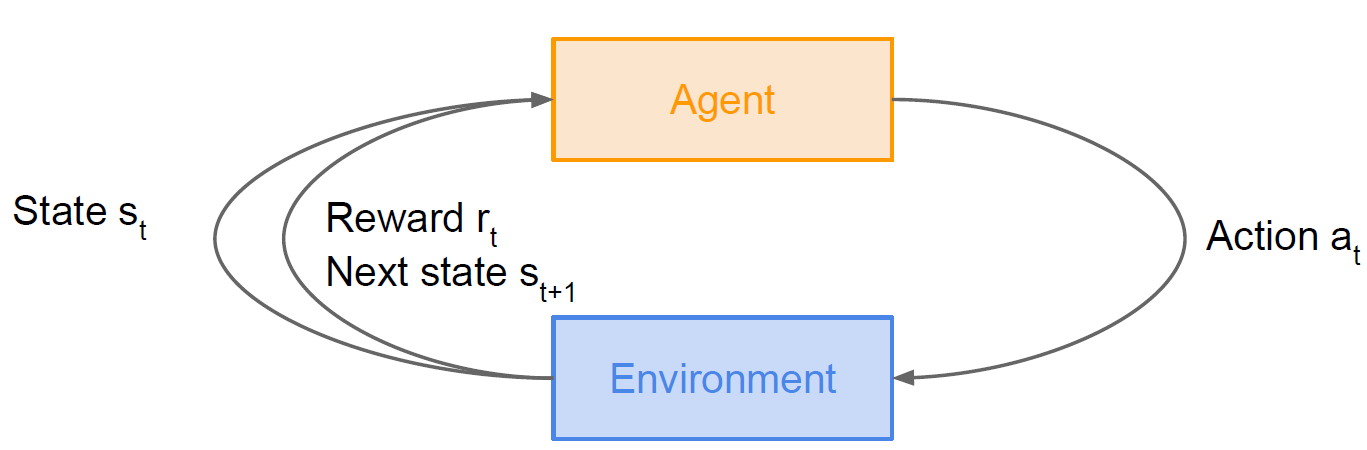
用Markov Decision Process描述RL problem。马尔可夫过程是拥有马尔可夫性质的过程。马尔可夫性质:未来的状态仅依赖当前状态,或者说该过程没有记忆特质。