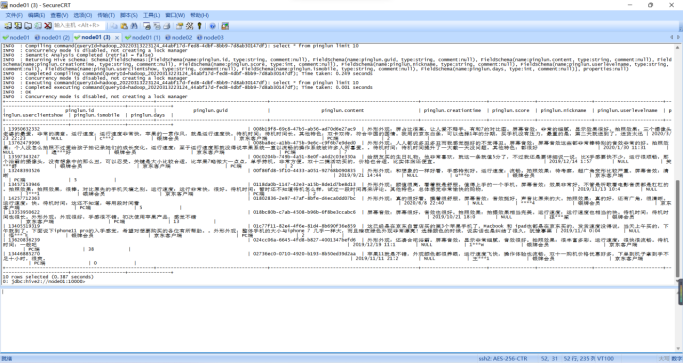
3、 数据统计:生成Hive用户评论数据:(15分)
(1)在Hive创建一张表,用于存放清洗后的数据,表名为pinglun,(创建数据表SQL语句),创建成功导入数据截图:
|
在hive中建表: create table pinglun ( id string, guid string, content string, creationtime string, score int, nickname string, userlevelname string, userclientshow string, ismobile string, days int ) row format delimited fields terminated by ',';
|
|
将数据导入到表中: load data local inpath '/kkb/install/apache-hive-3.1.2-bin/testdate/marketing/comjd1.csv' into table pinglun;
|

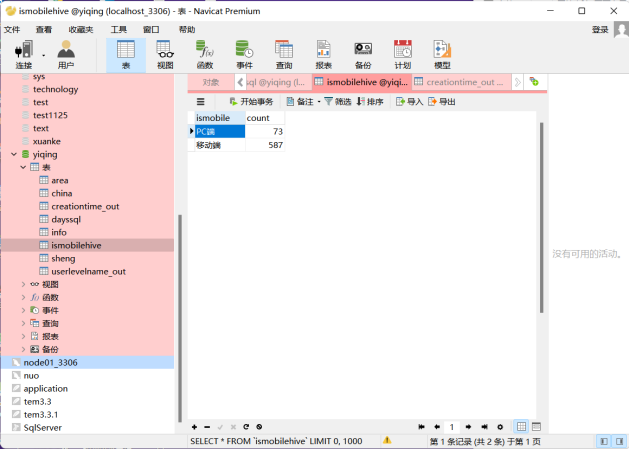
需求1:分析用户使用移动端购买还是PC端购买,及移动端和PC端的用户比例,生成ismobilehive表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
|
创建数据表: create table ismobilehive( ismobile string, count int )row format delimited fields terminated by ','; 插入数据: insert into table ismobilehive select ismobile,count(*) from pinglun group by ismobile; |
|
查看数据: Select * from ismobilehive;
|

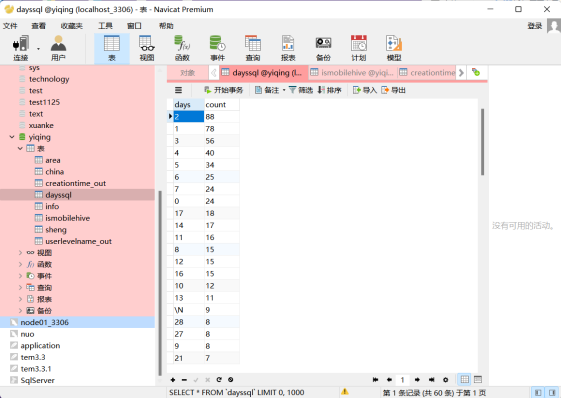
需求2:分析用户评论周期(收到货后,一般多久进行评论),生成dayssql表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
|
创建数据表: create table dayssql( days string, count int )row format delimited fields terminated by ','; 插入数据: insert into table dayssql select days, count(1) as count from pinglun group by days order by num desc; |
|
查看数据: Select * from dayssql; 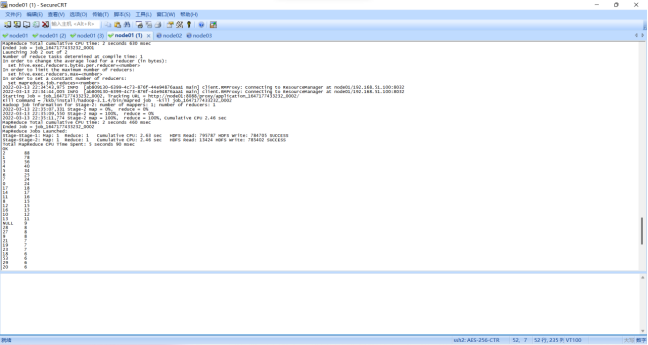
|
需求3:分析会员级别(判断购买此商品的用户级别),生成userlevelname_out表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
|
创建数据表: create table userlevelname_out( userlevelname string, count int )row format delimited fields terminated by ','; 插入数据: insert into table userlevelname_out select userlevelname, count(1) as num from pinglun group by userlevelname order by num desc; |
|
查看数据: Select * from userlevelname_out; 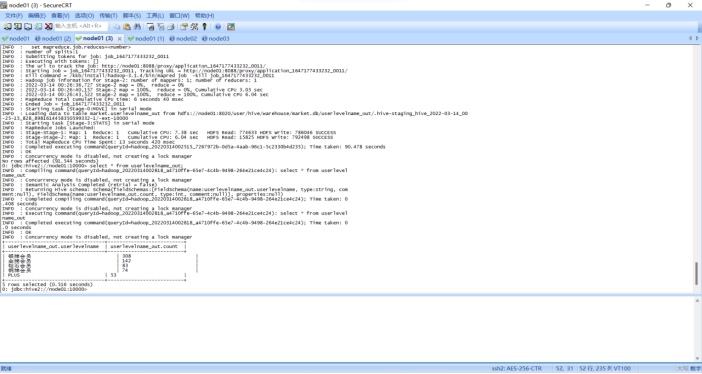
|
需求4:分析每天评论量,生成creationtime_out表,存储统计结果;创建数据表SQL语句,创建成功导入数据截图
|
创建数据表: create table creationtime_out( creationtime string, count int )row format delimited fields terminated by ','; 插入数据: insert into table creationtime_out select substr(creationtime, 0, 10) as dt, count(1) as num from pinglun group by substr(creationtime, 0, 10) order by num desc; |
|
查看数据:
|
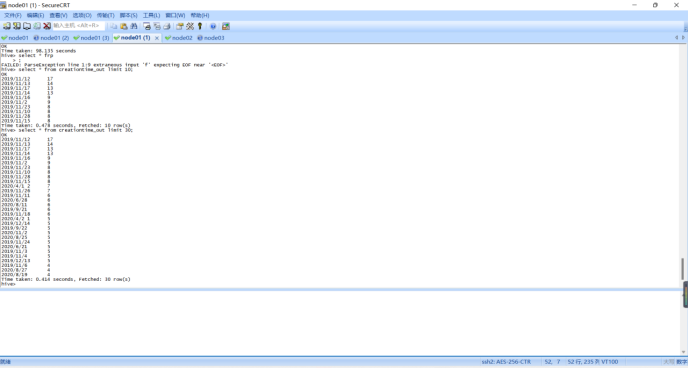
需求5:日期格式标准化后数据表前后对照截图
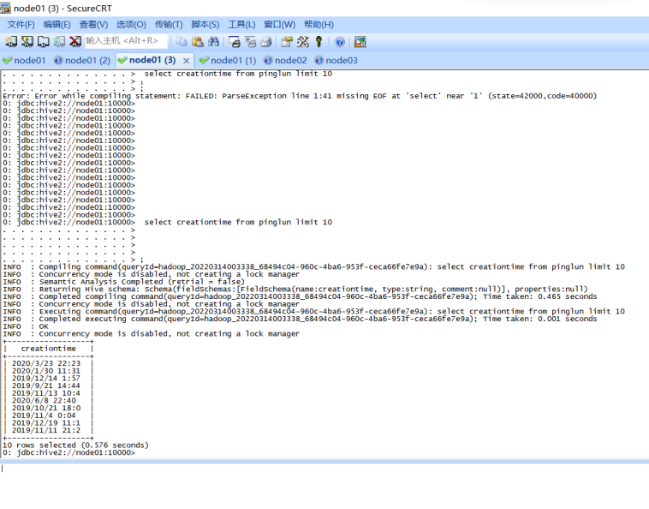 |
 |
3、 利用Sqoop进行数据迁移至Mysql数据库:(5分)
五个表导入mysql数据库中五个表截图。
|
1)通过navicat 在 Mysql 中新建表: create table ismobilehive( ismobile varchar(255), count int ) create table dayssql( days varchar(255), count int ) create table userlevelname_out( userlevelname varchar(255), count int ) create table creationtime_out( creationtime varchar(255), count int ) |
|
2)通过sqoop将hive中的数据导入到mysql bin/sqoop export \ --connect jdbc:mysql://192.168.51.100:3306/hive2?characterEncoding=utf-8 \ --username root \ --password wyhhxx \ --table ismobilehive\ --num-mappers 1 \ --export-dir /user/hive/warehouse/market.db/ismobilehive \ --input-fields-terminated-by "," bin/sqoop export \ --connect jdbc:mysql://192.168.51.100:3306/hive2?characterEncoding=utf-8 \ --username root \ --password wyhhxx \ --table dayssql\ --num-mappers 1 \ --export-dir /user/hive/warehouse/market.db/dayssql \ --input-fields-terminated-by "," bin/sqoop export \ --connect jdbc:mysql://node01:3306/hive2?characterEncoding=utf-8 \ --username root \ --password wyhhxx \ --table userlevelname_out \ --num-mappers 1 \ --export-dir /user/hive/warehouse/market.db/userlevelname_out \ --input-fields-terminated-by "," bin/sqoop export \ --connect jdbc:mysql://node01:3306/hive2?characterEncoding=utf-8 \ --username root \ --password wyhhxx \ --table creationtime_out \ --num-mappers 1 \ --export-dir /user/hive/warehouse/market.db/creationtime_out \ --input-fields-terminated-by "," 
|
|
3) 结果展示:
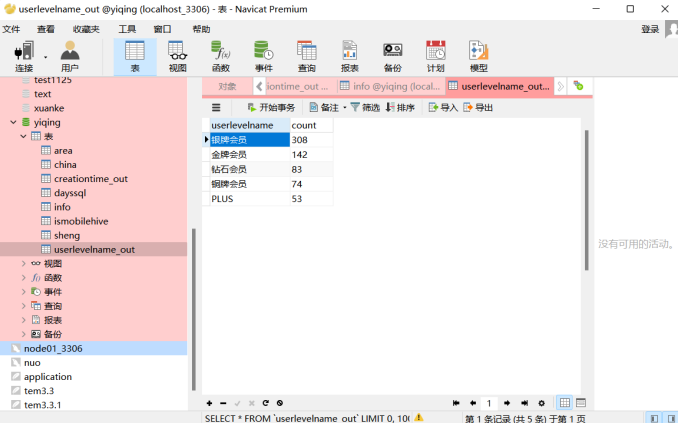
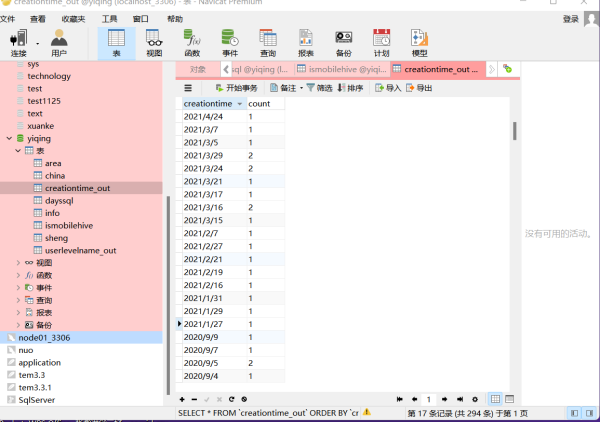 |
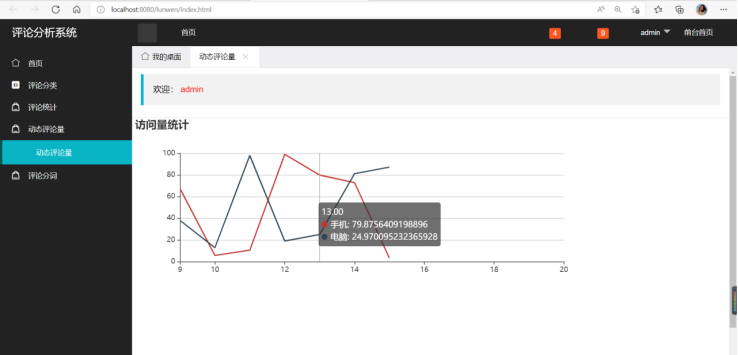
3、 数据可视化:利用JavaWeb+Echarts完成数据图表展示过程(20分)
需求1:可视化展示截图

需求2:可视化展示截图

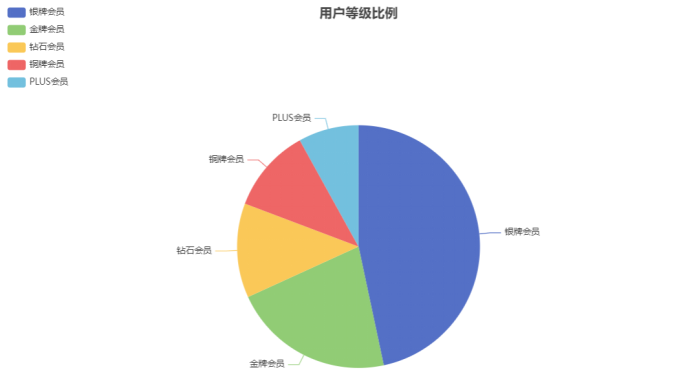
需求3:可视化展示截图
需求4:可视化展示截图

6、 中文分词实现用户评价分析。(20分)
(1)本节通过对商品评论表中的差评数据,进行分析,筛选用户差评点,以知己知彼。(筛选差评数据集截图)
当用户评价星级score小于等于3时,来获取用户差评数据集。

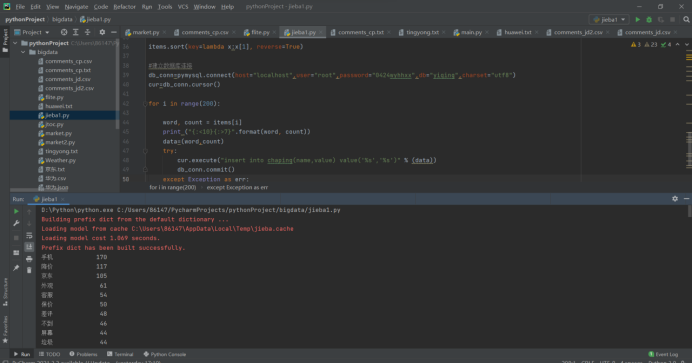
(2)利用 python 结巴分词实现用户评价信息中的中文分词及词频统计;(分词后截图)

(3)在 hive 中新建词频统计表并加载分词数据;
要求实现:
①实现用户评价信息中的中文分词;
drop table if exists comment_word_count_tb;
create table comment_word_count_tb(
word string, count int
)
row format delimited fields terminated by ',';
load data local inpath '/kkb/install/apache-hive-3.1.2-bin/testdate/marketing/chaping.csv' into table comment_word_count_tb;
②实现中文分词后的词频统计;

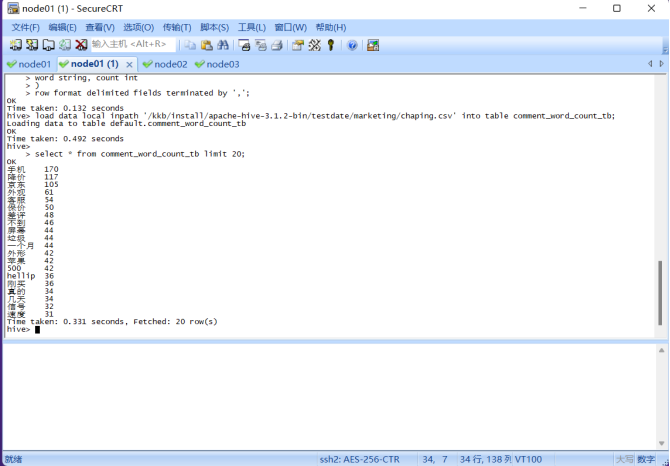
③在 hive 中新建词频统计表加载分词数据;
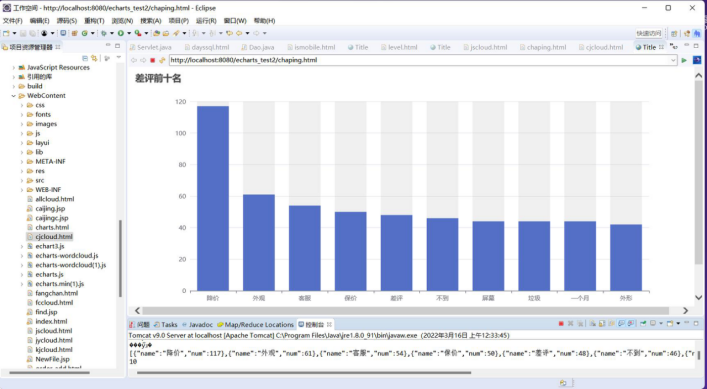
④柱状图可视化展示用户差评的统计前十类。
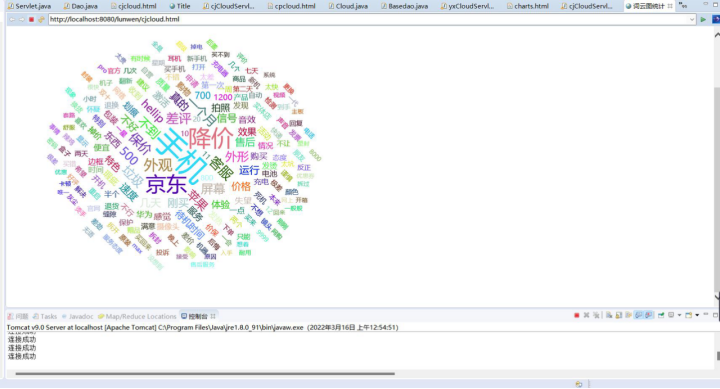
⑤用词云图可视化展示用户差评分词。
7、利用Spark进行实时数据分析。(20分)
本实验以京东商品评论为目标网站,架构采用爬虫+Flume+Kafka+Spark Streaming+Mysql,实现数据动态实时的采集、分析、展示数据。
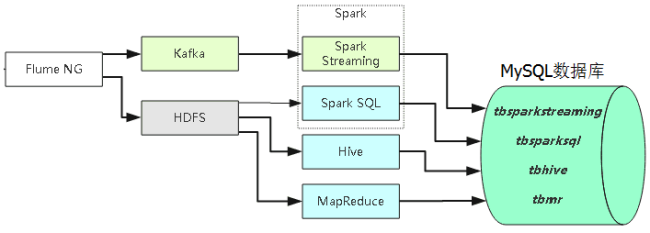
具体工作流程如下图:
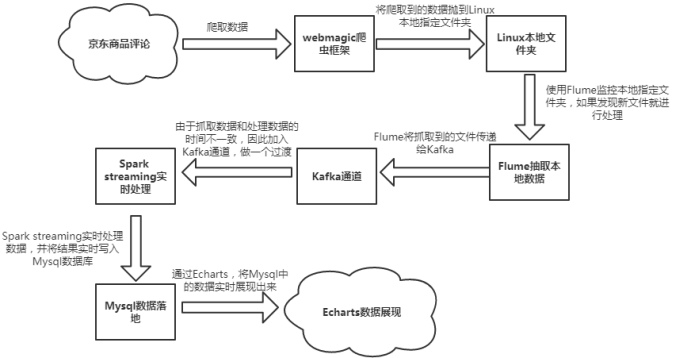
操作步骤截图
|
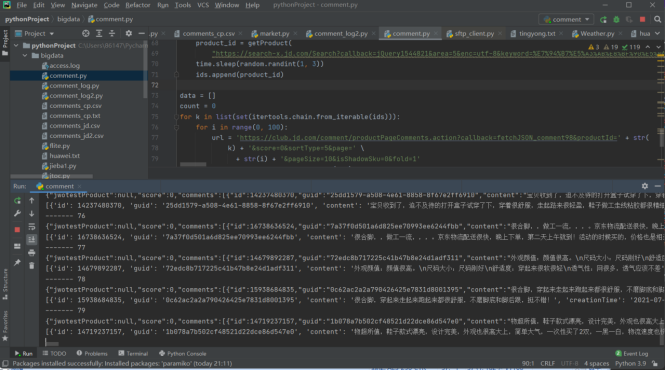
(1)编写python文件采集访问信息,并将采集到的信息写入到文件comment.log中
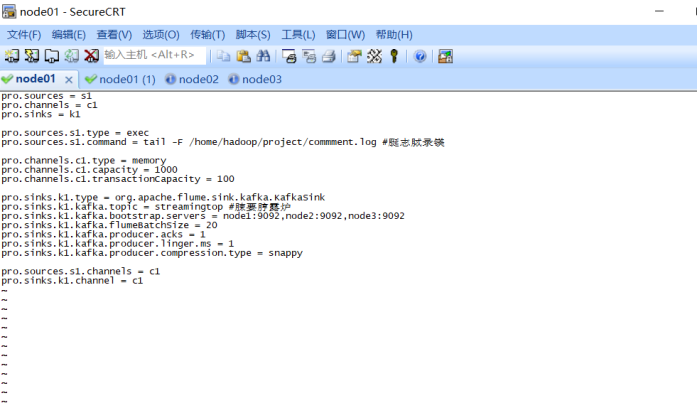
(2) 将comment.log日志收集到flume中
flume-ng agent \ --name exec-memory-logger \ --conf $FLUME_HOME/conf \ --conf-file /home/hadoop/project/streaming_project.conf \ -Dflume.root.logger=INFO,console (3) flume到kafka:
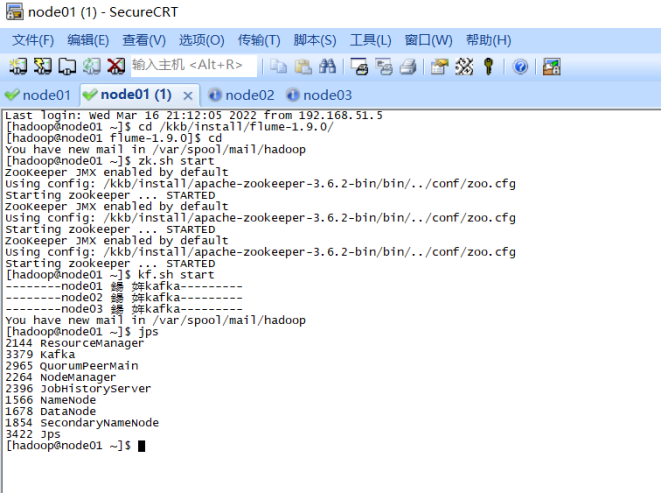
启动kafka Server:kf.sh start(集群脚本) jsp查看进程:
bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --replication-factor 1 --partitions 1 --topic steamingtopic
bin/kafka-topics.sh --zookeeper node01:2181 --list
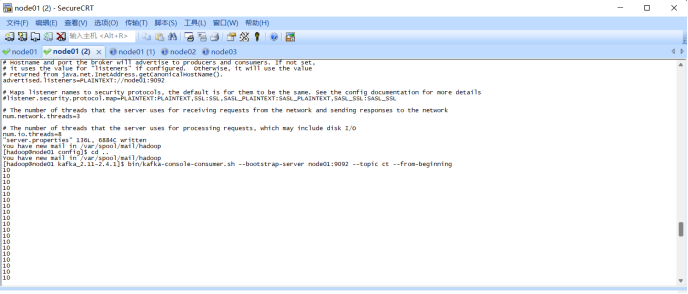
bin/kafka-console-consumer.sh --bootstrap-server node01:2181 --topic steamingtopic --from-beginning (4) 此时运行python就可以在kafka收集到信息 |
|
Python:
Flume: 
Kafka: (5) 使用sparkstreaming消费数据,将kafka数据收集到nivacat IDEA创建maven项目,创建scala文件 导入依赖: <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.2.0</version> <scope>runtime</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.10.1</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.18</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>2.4.1</version> </dependency> Direct模式连接Kafka消费数据:
|