本文所有工作基于上一篇博客《Hadoop平台搭建(VMware、CentOS)》,请确认已按照上文正确搭建好Hadoop环境
本文所有工作主要参考Apache HBase官方参考文档,部分步骤有所改变
本文工作止于在运行的HBase上测试基本的数据表功能,以确定HBase的正常运行
=====================================================================================
一、集群结构
在配置Hadoop环境的时候,集群包含1个NameNode和3个DataNode共四台主机。而在HBase这里,由于需要配置ZooKeeper服务且官方建议配置奇数台服务器,因此这里放弃一个DataNode,只留下3台主机配置HBase。结构如下:
| Hostname(IP) | Hadoop Node | HBase Master | ZooKeeper | RegionServer |
| Master.Hadoop(192.168.222.134) | NameNode | Yes | Yes | No |
| Slave1.Hadoop(192.168.222.135) | DataNode | Backup | Yes | Yes |
| Slave2.Hadoop(192.168.222.136) | DataNode | No | Yes | Yes |
二、配置ZooKeeper服务(于所有节点)
安装分布式数据库HBase需要基于一个ZooKeeper集群。因此,需要先在三台主机上配置ZooKeeper服务。
配置思路可以有两种,一种是按照以下步骤分别在每台主机上解压缩并配置;另一种是只在一台主机上配置,然后通过scp -r指令将zookeeper文件夹复制到另外的主机,需要修改的是步骤⑦中的myid文件。第二种配置方式效率更高。
②在/home/下建立zookeeper文件夹
mkdir /home/zookeeper
③解压文件
tar -zxvf zookeeper-3.4.6.tar.gz
④在zookeeper-3.4.6下建立子目录
cd /home/zookeeper/zookeeper-3.4.6
mkdir data //保存zookeeper数据
mkdir logs //保存运行日志
⑤zookeeper运行配置
cd conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改或添加以下两项(Line#12):
dataDir=/home/zookeeper/zookeeper-3.4.6/data
dataLogDir=/home/zookeeper/zookeeper-3.4.6/logs
末尾添加以下:
server.1=192.168.222.134:2888:3888 //2888是zookeeper服务之间的通信端口号
server.2=192.168.222.135:2888:3888 //3888是zookeeper与其他应用程序通信端口号
server.3=192.168.222.136:2888:3888
保存退出
⑥配置zookeeper环境变量
vi /etc/profile
末尾追加以下:
#zookeeper
export ZOOKEEPER_HOME=/home/zookeeper/zookeeper-3.4.6/
export PATH=$ZOOKEEPER_HOME/bin:$PATH
export PATH
保存退出
使配置生效:
source /etc/profile
⑦设置myid文件(各主机不同)
进入dataDir目录下(这里是/home/zookeeper/zookeeper-3.4.6/data)
cd /home/zookeeper/zookeeper-3.4.6/data
echo "1" >> myid //这里的"1"对应zoo.cfg中添加的server.1,也即在192.168.222.135主机上设置为2,最后一台设置为3
cat myid //查看确认myid内容
⑧启动/状态/停止(由于配置了环境变量,因此zkServer.sh为全局指令,无所谓在哪个工作路径)
zkServer.sh start //启动zookeeper
zkServer.sh status //查看zookeeper启动状态
zkServer.sh stop //停止zookeeper服务
⑨运行状态



运行状态有所调整,刚启动时Slave1为leader,现在又变成了Slave2,并且Slave1收到一条消息。
⑩关闭zookeeper服务
三、安装并配置HBase
根据集群结构,需要在三台主机上安装HBase,并配置Master.Hadoop为HMaster,Slave1.Hadoop为Backup,Slave1.Hadoop及Slave2.Hadoop配置RegionServer。
②在/home/下建立hbase文件夹
mkdir /home/hbase
③解压文件
tar -zxvf hbase-1.2.4-bin.tar.gz
④配置Hbase的JAVA环境变量
cd /home/hbase/hbase-1.2.4/conf
vi hbase-env.sh
修改JAVA_HOME变量(Line#27):
export JAVA_HOME="/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131.x86_64"
⑤配置HBase的核心参数
cd /home/hbase/hbase-1.2.4/conf
vi hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://192.168.222.134:9000/hbase</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/zookeeper/zookeeper-3.4.6/data</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>Master.Hadoop,Slave1.Hadoop,Slave2.Hadoop,Slave3.Hadoop</value> </property> </configuration>
⑥配置集群主机之间的SSH无密码通信
参考《Hadoop平台搭建(VMware、CentOS)》一文中第6步
⑦配置RegionServer
cd /home/hbase/hbase-1.2.4/conf
vi regionservers
内容修改为:
192.168.222.135
192.168.222.136
⑧配置HMaster backup
cd /home/hbase/hbase-1.2.4/conf
vi backup-masters //backup-masters文件为新建文件
添加如下内容:
Slave1.Hadoop
⑨将Hbase复制到另外两台主机
scp -r /home/hbase root@192.168.222.135:/home/hbase
scp -r /home/hbase root@192.168.222.137:/home/hbase
⑩启动HBase
cd /home/hbase/hbase-1.2.4/
bin/start-hbase.sh
可能会要求确认是否添加信任,需要手动输入yes并回车
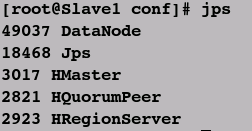
⑪jps查看各主机进程


⑫在浏览器中查看HBase信息
http://192.168.222.134:16010/
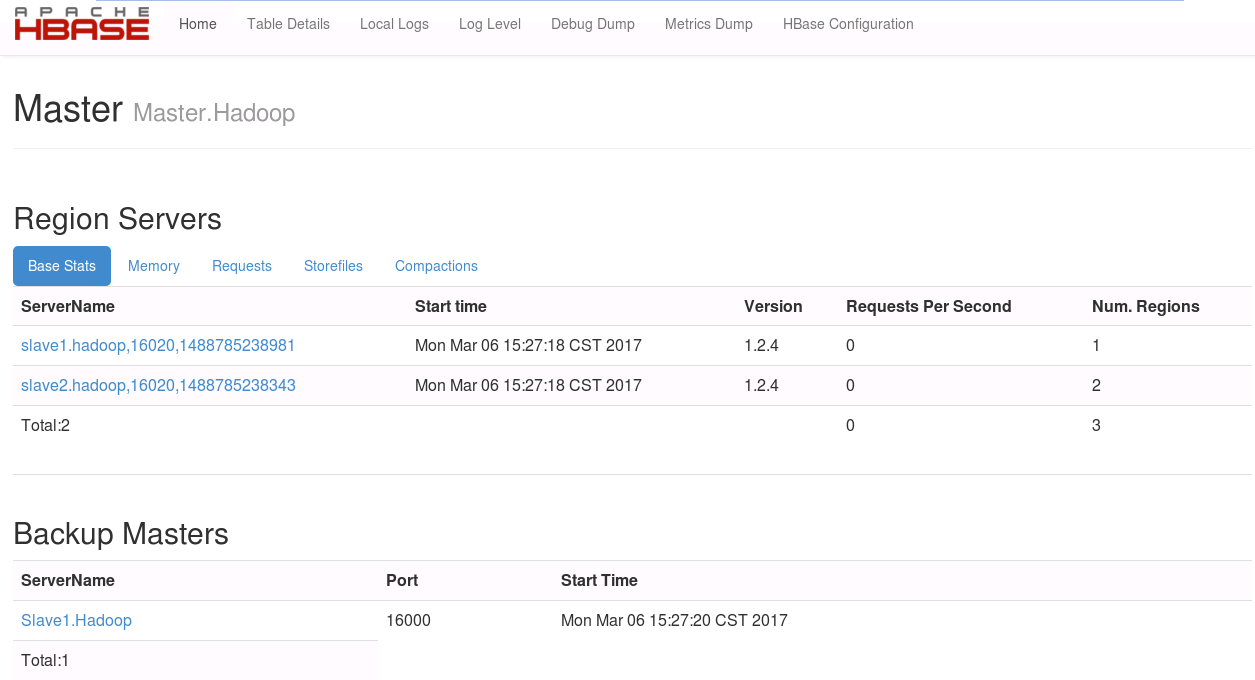
还有更多信息未截图
三、测试HBase基本功能
①连接HBase
./bin/hbase shell
②创建新数据表test

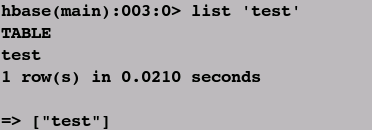
③查看数据表test
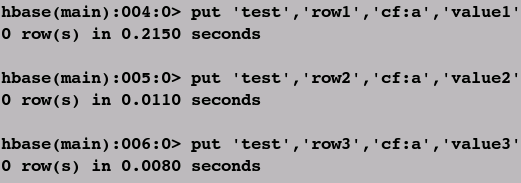
④添加数据
⑤查看表格内容

⑥获得某一数据记录

⑦更多操作请参考HBase官方文档
四、经验集锦
①在配置zookeeper及hbase的过程中,出现错误或异常仍然需要优先查看.log文件以及.out文件。
②在选择配置的hadoop、zookeeper、hbase以及基本的JDK版本时,可以参考官方说明。
③在配置hbase-env.sh文件时,我们只配置了JAVA_HOME。在该文件中还可以配置默认为true的HBASE_MANAGE_ZK参数,该参数默认由hbase来同步开启/关闭zookeeper服务,如有必要可以配置为false,然后手动控制zookeeper。
④在配置hbase的第④步骤中,实际情况是设置JAVA_HOME变量不可以使用${JAVA_HOME},运行时会提示:
"Error:JAVA_HOME is not set and could not be found"
五、参考文章