不多说,直接上干货!
很多地方都需用到这个知识点,比如Tableau里。 通常可以采取如python 和 r来作为数据处理的前期。
Tableau学习系列之Tableau如何通过数据透视表方式读取数据文件(图文详解)
如何用Python来处理数据表的长宽转换(图文详解)
数据长宽转换是很常用的需求,特别是当是从Excel中导入的汇总表时,常常需要转换成一维表(长数据)才能提供给图表函数或者模型使用。
在R语言中,提供数据长宽转换的包主要有两个:
- reshape2::melt/dcast
- tidyr::gather/spread
library("reshape2") library("tidyr")
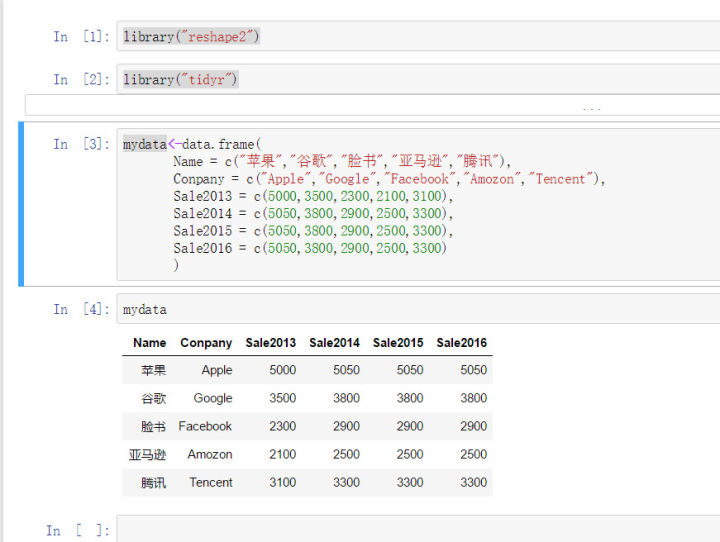
mydata<-data.frame( Name = c("苹果","谷歌","脸书","亚马逊","腾讯"), Conpany = c("Apple","Google","Facebook","Amozon","Tencent"), Sale2013 = c(5000,3500,2300,2100,3100), Sale2014 = c(5050,3800,2900,2500,3300), Sale2015 = c(5050,3800,2900,2500,3300), Sale2016 = c(5050,3800,2900,2500,3300) )
数据重塑(宽转长):
melt函数是reshape2包中的数据宽转长的函数
mydata<-melt( mydata, #待转换的数据集名称 id.vars=c("Conpany","Name"), #要保留的主字段 variable.name="Year", #转换后的分类字段名称(维度) value.name="Sale" #转换后的度量值名称 )
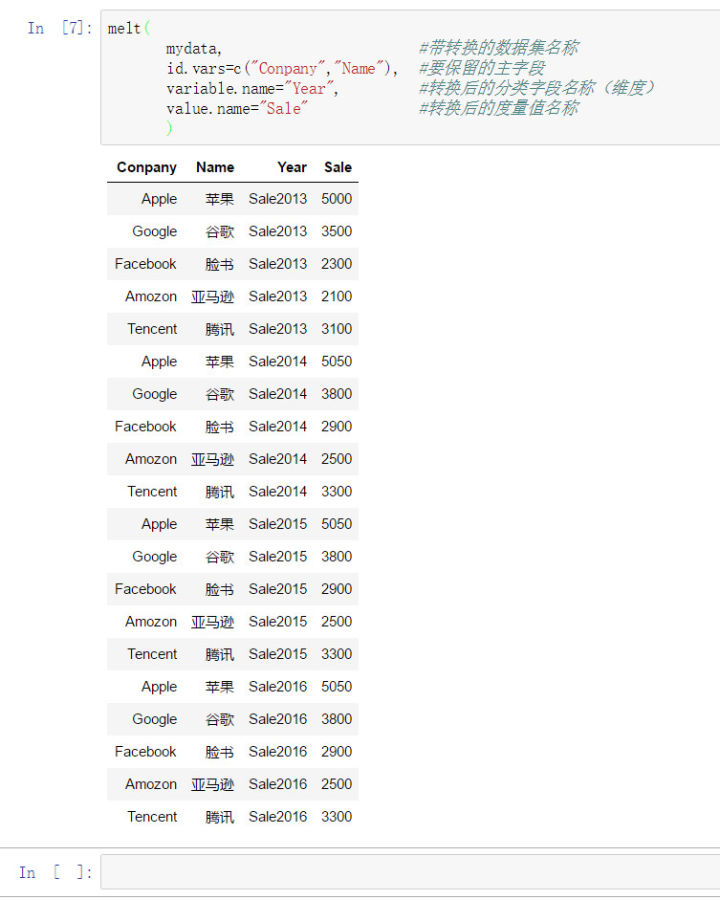
转换之后,长数据结构保留了原始宽数据中的Name、Conpany字段,同时将剩余的年度指标进行堆栈,转换为一个代表年度的类别维度和对应年度的指标。(即转换后,所有年度字段被降维化了)。
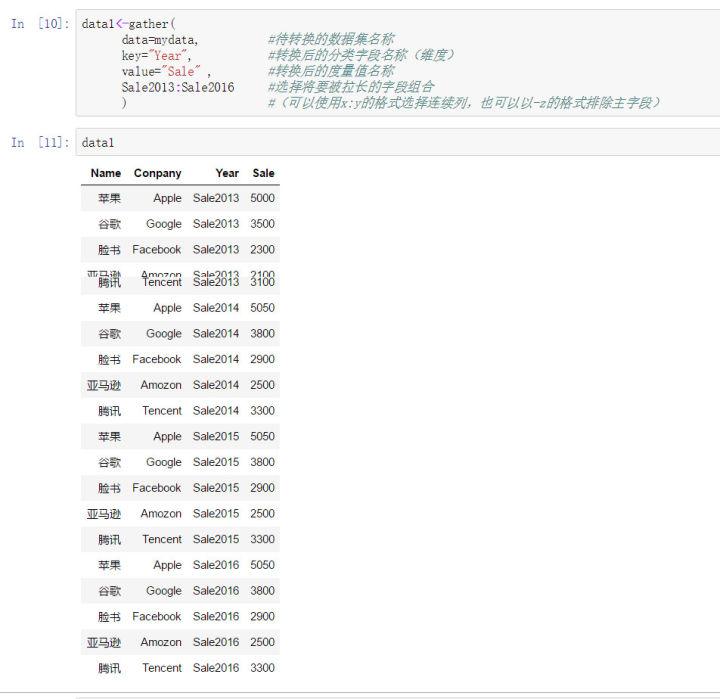
1、在tidyr包中的gather也可以非常快捷的完成宽转长的任务:
data1<-gather( data=mydata, #待转换的数据集名称 key="Year", #转换后的分类字段名称(维度) value="Sale" , #转换后的度量值名称 Sale2013:Sale2016 #选择将要被拉长的字段组合 ) #(可以使用x:y的格式选择连续列,也可以以-z的格式排除主字段)
而相对于数据宽转长而言,数据长转宽就显得不是很常用,因为长转宽是数据透视,这种透视过程可以通过汇总函数或者类数据透视表函数来完成。
但是既然数据长宽转换是成对的需求,自然有对应的长转宽函数。
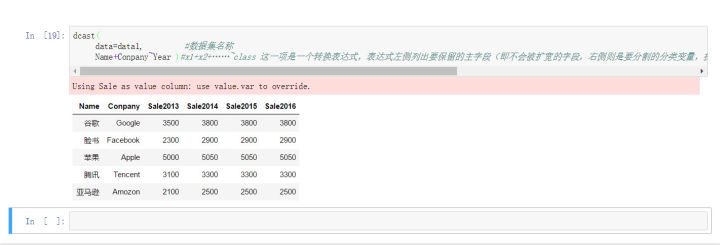
2、reshape2中的dcast函数可以完成数据长转宽的需求:
dcast( data=data1, #数据集名称 Name+Conpany~Year #x1+x2+……~class #这一项是一个转换表达式,表达式左侧列 #出要保留的主字段(即不会被扩宽的字段,右侧则是要分割的分类变量,扩展之后的 #宽数据会增加若干列度量值,列数等于表达式右侧分类变量的类别个数 )
除此之外,tidyr包中的spread函数在解决数据长转宽方面也是很好的一个选择。
spread:
spread( data=data1, #带转换长数据框名称 key=Year, #带扩宽的类别变量(编程新增列名称) value=Sale) #带扩宽的度量值 (编程新增列度量值)
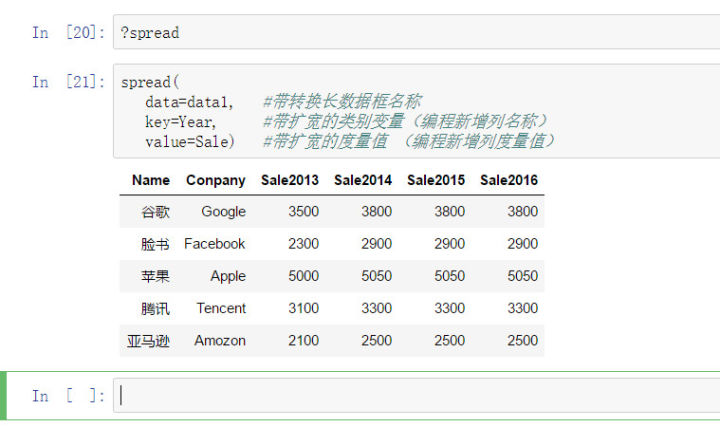
从以上代码的复杂度来看,reshape2内的两个函数meltdcast和tidyr内的两个函数gatherspread相比,gatherspread这一对函数完胜,不愧是哈神的最新力作,tidyr内的两个函数所需参数少,逻辑上更好理解,自始至终都围绕着data,key、value三个参数来进行设定,而相对老旧的包reshape2内的meltdcast函数在参数配置上就显得不是很友好,他是围绕着一直不变的主字段来进行设定的,tidyr包则围绕着转换过程中会变形的维度和度量来设定的。
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()


