不多说,直接上干货!
Apache Beam的API设计
Apache Beam还在开发之中,后续对应的API设计可能会有所变化,不过从当前版本来看,基于对数据处理领域对象的抽象,API的设计风格大量使用泛型来定义,具有很高的抽象级别。下面我们分别对感兴趣的的设计来详细说明。
- Source
Source表示数据输入的抽象,在API定义上分成两大类:一类是面向数据批处理的,称为BoundedSource,它能够从输入的数据集读取有限的数据记录,知道数据具有有限性的特点,从而能够对输入数据进行切分,分成一定大小的分片,进而实现数据的并行处理;另一类是面向数据流处理的,称为UnboundedSource,它所表示的数据是连续不断地进行输入,从而能够实现支持流式数据所特有的一些操作,如Checkpointing、Watermarks等。
Source对应的类设计,如下类图所示:
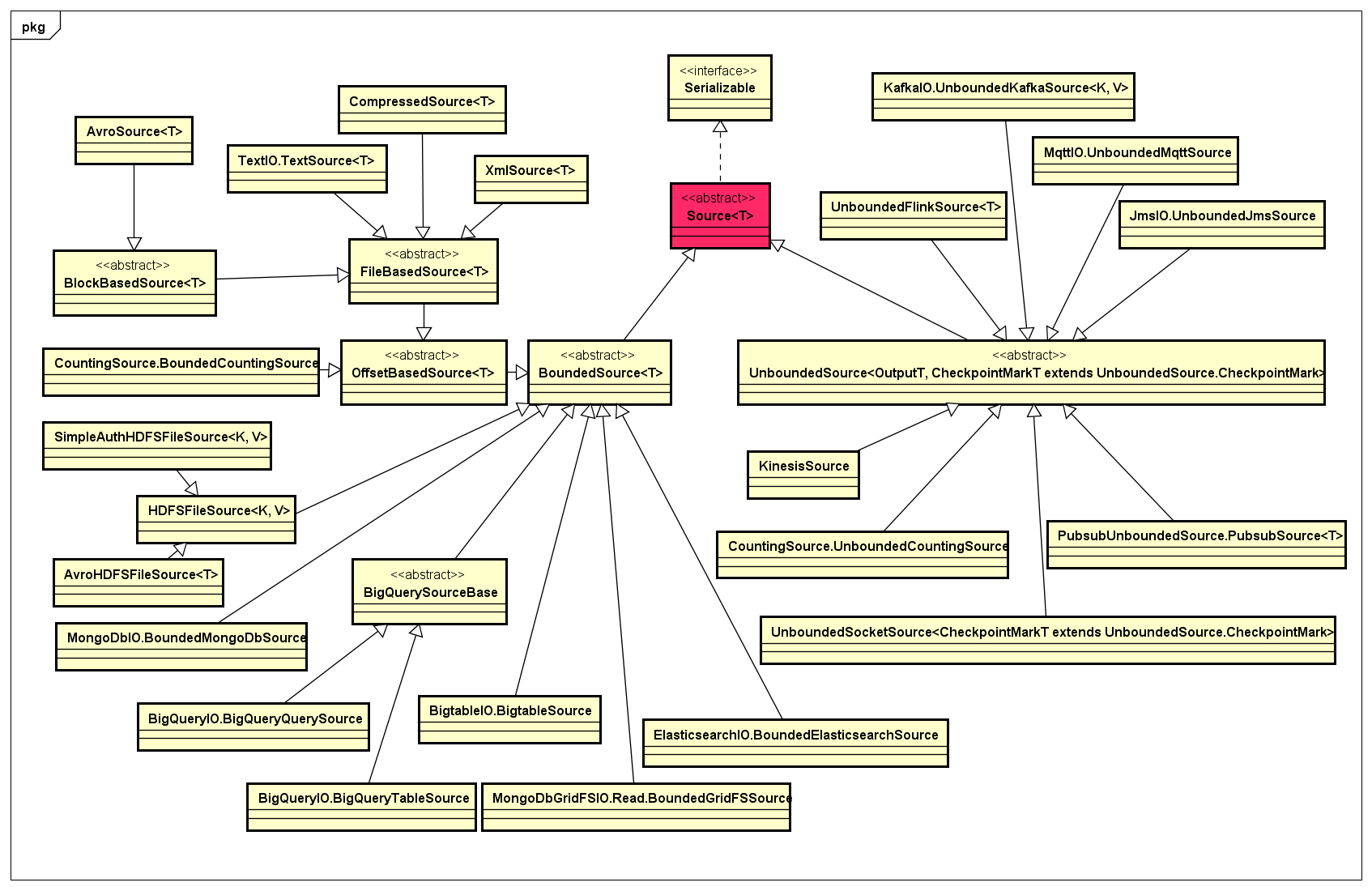
目前,Apache Beam支持BoundedSource的数据源主要有:HDFS、MongoDB、Elasticsearch、File等,支持UnboundedSource的数据源主要有:Kinesis、Pubsub、Socker等。未来,任何具有Bounded或Unbounded两类特性的数据源都可以在Apache Beam的抽象基础上实现对应的Source。
- Sink
Sink表示任何经过Pipeline中一个或多个PTransform处理过的PCollection,最终会输出到特定的存储中。与Source对应,其实Sink主要也是具有两种类型:一种是直接写入特定存储的Bounded类型,如文件系统;另一种是写入具有Unbounded特性的存储或系统中,如Flink。在API设计上,Sink的类图如下所示:

可见,基于Sink的抽象,可以实现任意可以写入的存储系统。
- PipelineRunner
下面,我们来看一下PipelineRunner的类设计以及目前开发中的PipelineRunner,如下图所示:
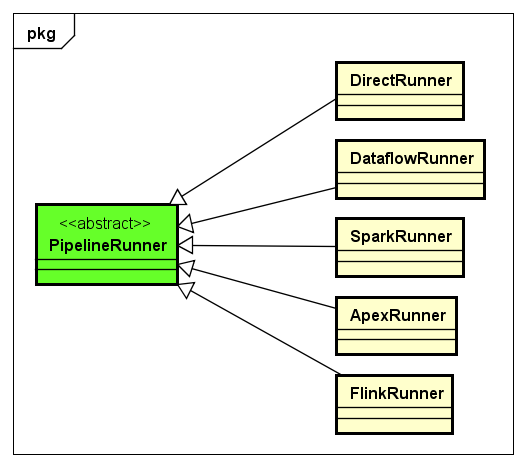
目前,PipelineRunner有DirectRunner、DataflowRunner、SparkRunner、ApexRunner、FlinkRunner,待这些主流的PipelineRunner稳定以后,如果有其他新的计算引擎框架出现,可以在PipelineRunner这一层进行扩展实现。
这些PipelineRunner中,DirectRunner是最简单的PipelineRunner,它非常有用,比如我们实现了一个从HDFS读取数据,但是需要在Spark集群上运行的ETL程序,使用DirectRunner可以在本地非常容易地调试ETL程序,调试到程序的数据处理逻辑没有问题了,再最终在实际的生产环境Spark集群上运行。如果特定的PipelineRunner所对应的计算引擎没有很好的支撑调试功能,使用DirectRunner是非常方便的。
- PCollection
PCollection是对分布式数据集的抽象,主要用作输入、输出、中间结果集。其中,在Apache Beam中对数据及其数据集的抽象有几类,我们画到一张类图上,如下图所示:
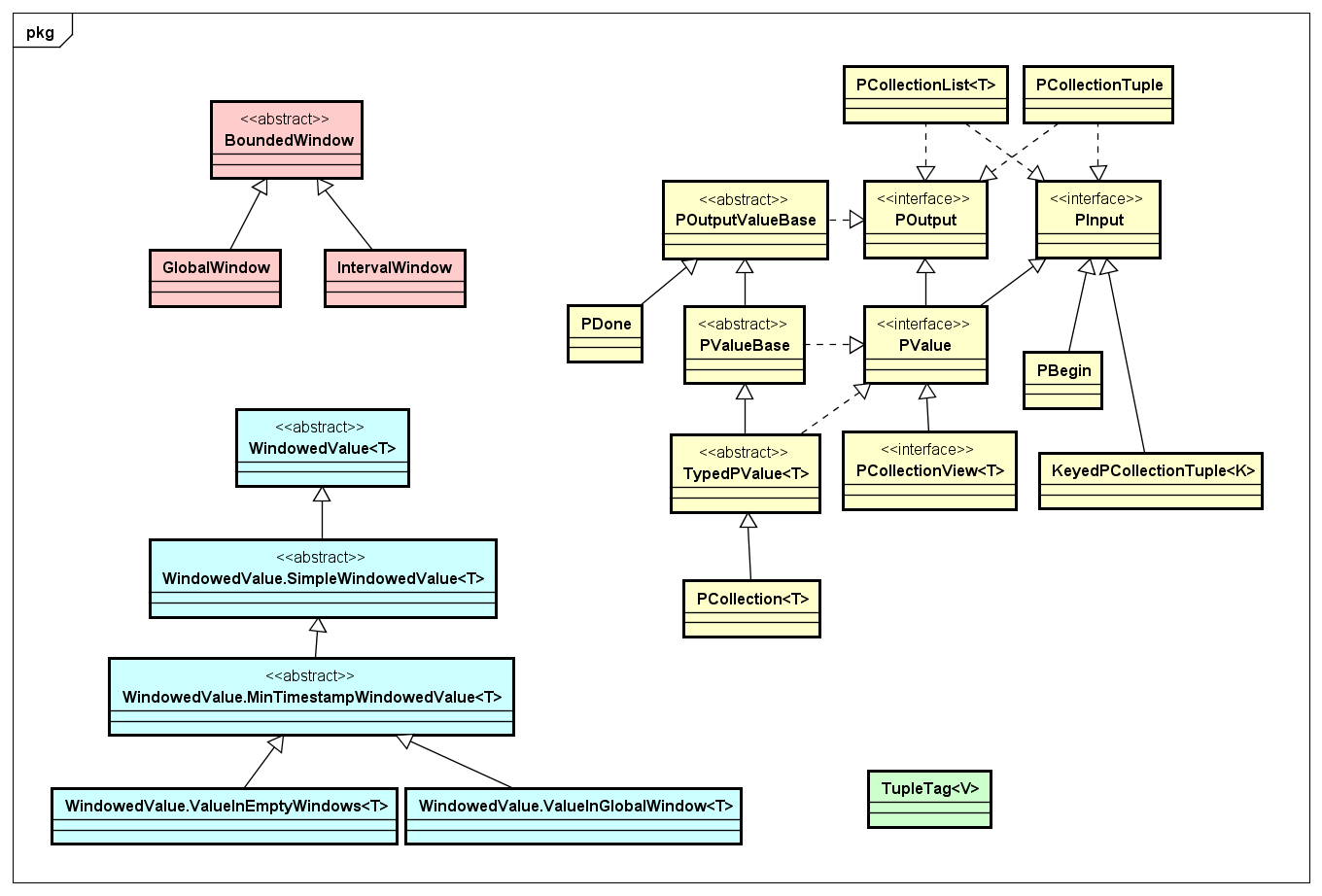
PCollection是对数据集的抽象,包括输入输出,而基于Window的数据处理有对应的Window相关的抽象,还有一类就是TupleTag,针对具有CoGroup操作的情况下用来标记对应数据中的Tuple数据,具体如何使用可以后面我们实现的Join的例子。
- PTransform
一个Pipeline是由一个或多个PTransform构建而成的DAG图,其中每一个PTransform都具有输入和输出,所以PTransform是Apache Beam中非常核心的组件,我按照PTransform的做了一下分类,如下类图所示:
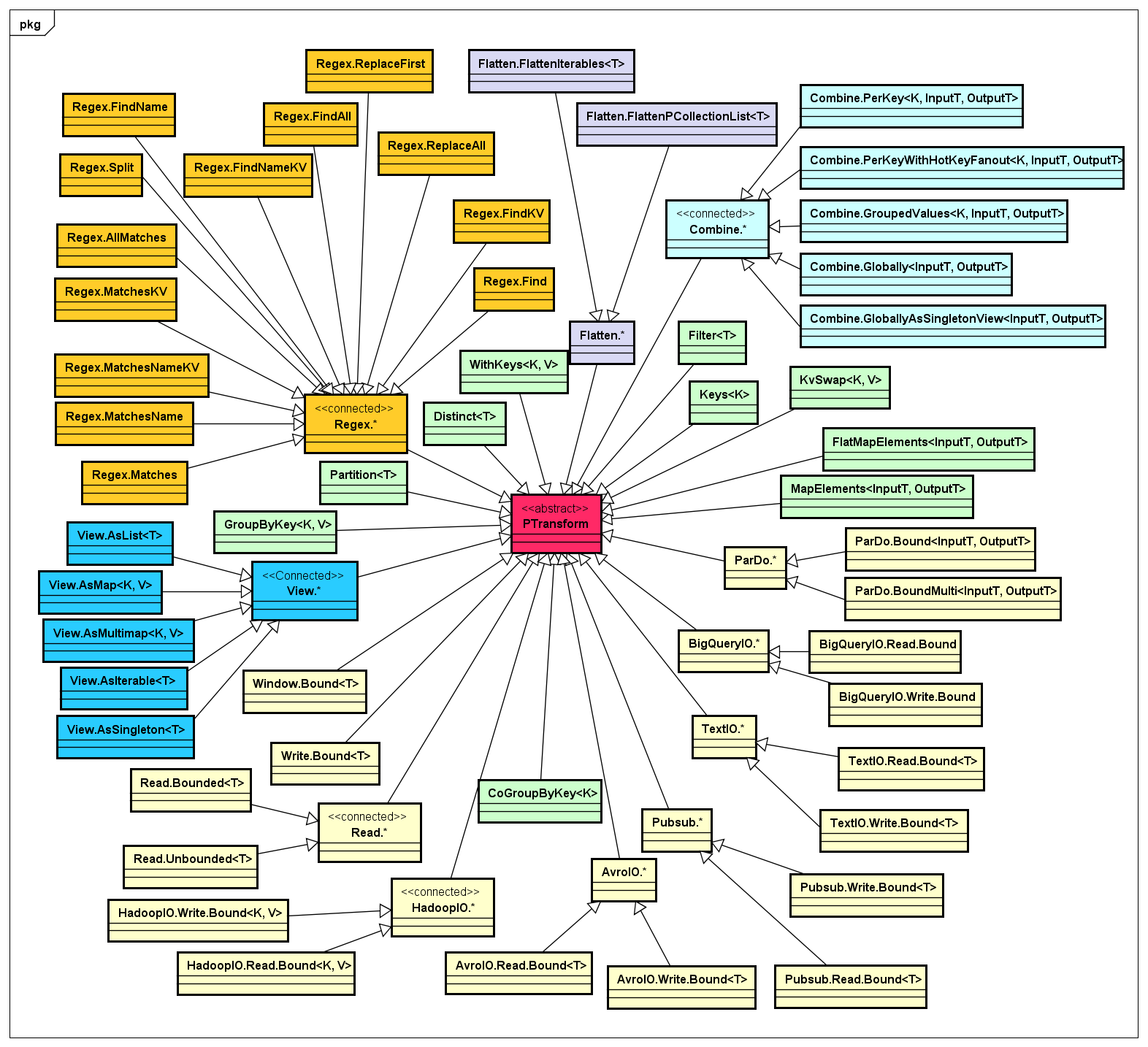
通过上图可以看出,PTransform针对不同输入或输出的数据的特征,实现了一个算子(Operator)的集合,而Apache Beam除了期望实现一些通用的PTransform实现来供数据处理的开发人员开箱即用,同时也在API的抽象级别上做的非常Open,如果你想实现自己的PTransform来处理指定数据集,只需要自定义即可。而且,随着社区的活跃及其在实际应用场景中推广和使用,会很快构建一个庞大的PTransform实现库,任何有数据处理需求的开发人员都可以共享这些组件。
- Combine
这里,单独把Combine这类合并数据集的实现拿出来,它的抽象很有趣,主要面向globally 和per-key这两类抽象,实现了一个非常丰富的PTransform算子库,对应的类图如下所示:
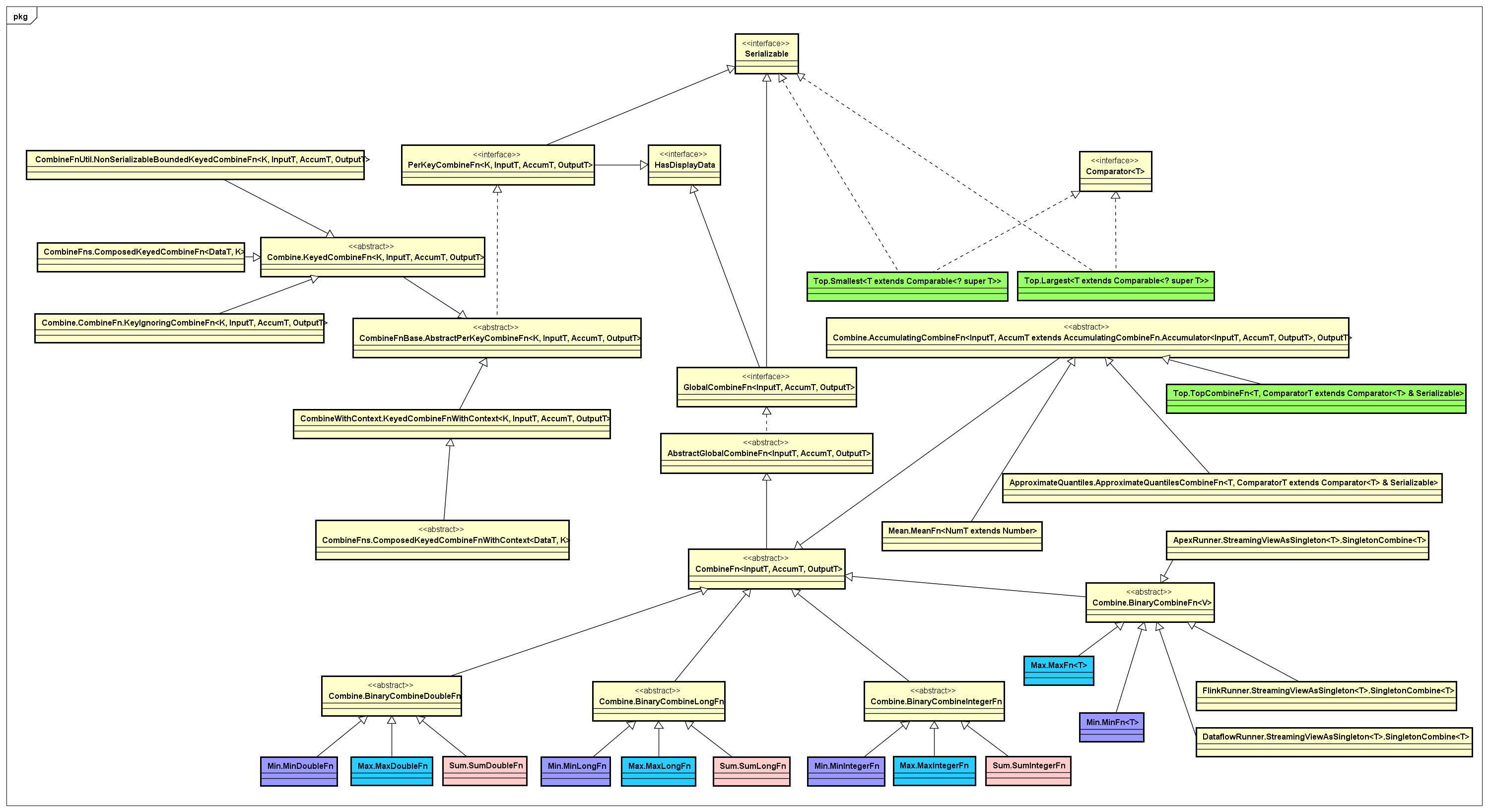
通过上图可以看出,作用在一个数据集上具有Combine特征的基本操作:Max、Min、Top、Mean、Sum、Count等等。
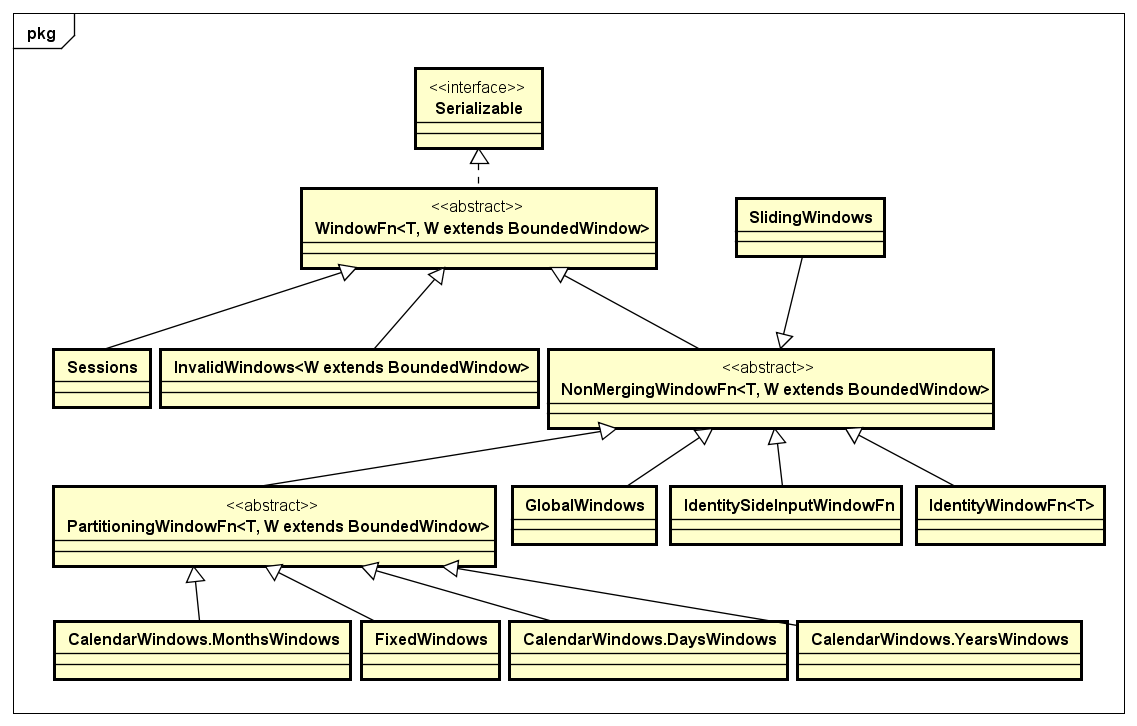
- Window
Window是用来处理某一个Micro batch的数据记录可以进行Merge这种场景的需求,通常用在Streaming处理的情况下。Apache Beam也提供了对Window的抽象,其中对于某一个Window下的数据的处理,是通过WindowFn接口来定义的,与该接口相关的处理类,如下类图所示: