不多说,直接上干货!
最近,开始,进一步学习spark的最新版本。由原来经常使用的spark-1.6.1,现在来使用spark-2.2.0-bin-hadoop2.6.tgz。
前期博客
Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
这里我,使用的是spark-2.2.0-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz 的单节点来测试下。
其中,hadoop-2.6.0的单节点配置文件,我就不赘述了。
这里,我重点写下spark on yarn。我这里采取的是这模式。
spark-defaults.conf
默认,保持不修改。
spark-env.sh

export JAVA_HOME=/home/spark/app/jdk1.8.0_60 export SCALA_HOME=/home/spark/app/scala-2.10.4 export HADOOP_HOME=/home/spark/app/hadoop-2.6.0 export HADOOP_CONF_DIR=/home/spark/app/hadoop-2.6.0/etc/hadoop export SPARK_MASTER_IP=192.168.80.218 export SPARK_WORKER_MERMORY=1G
slaves
sparksinglenode
问题详情
我已经是启动了hadoop进程。
然后,来执行

[spark@sparksinglenode spark-2.2.0-bin-hadoop2.6]$ bin/spark-shell
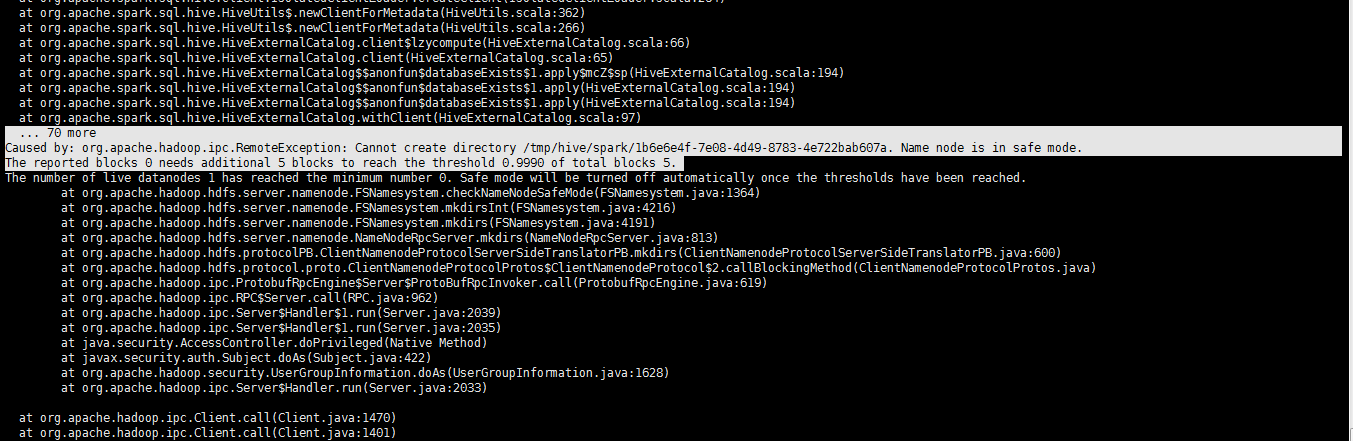
at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:362) at org.apache.spark.sql.hive.HiveUtils$.newClientForMetadata(HiveUtils.scala:266) at org.apache.spark.sql.hive.HiveExternalCatalog.client$lzycompute(HiveExternalCatalog.scala:66) at org.apache.spark.sql.hive.HiveExternalCatalog.client(HiveExternalCatalog.scala:65) at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:194) at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194) at org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$databaseExists$1.apply(HiveExternalCatalog.scala:194) at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97) ... 70 more Caused by: org.apache.hadoop.ipc.RemoteException: Cannot create directory /tmp/hive/spark/1b6e6e4f-7e08-4d49-8783-4e722bab607a. Name node is in safe mode. The reported blocks 0 needs additional 5 blocks to reach the threshold 0.9990 of total blocks 5. The number of live datanodes 1 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached. at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1364) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4216) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4191) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:813) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:600) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:962) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2039) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2035) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2033)
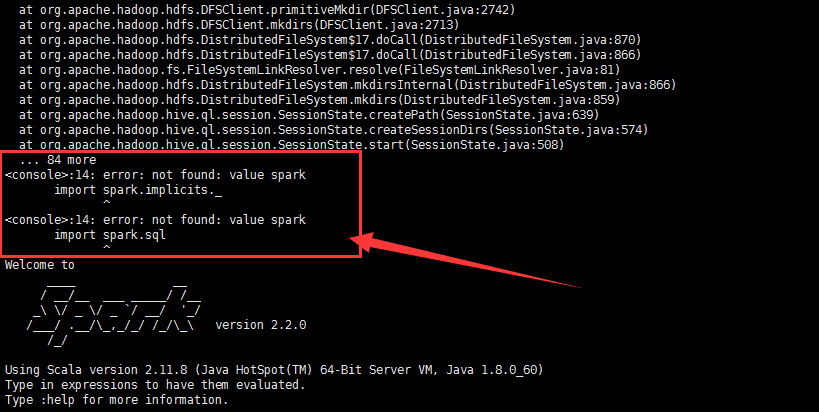
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:2713) at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:870) at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:866) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirsInternal(DistributedFileSystem.java:866) at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:859) at org.apache.hadoop.hive.ql.session.SessionState.createPath(SessionState.java:639) at org.apache.hadoop.hive.ql.session.SessionState.createSessionDirs(SessionState.java:574) at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:508) ... 84 more <console>:14: error: not found: value spark import spark.implicits._ ^ <console>:14: error: not found: value spark import spark.sql ^ Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_ version 2.2.0 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60) Type in expressions to have them evaluated. Type :help for more information. scala>
解决办法

[spark@sparksinglenode ~]$ jps 5733 SecondaryNameNode 6583 Jps 5464 NameNode 5933 ResourceManager 6031 NodeManager 5583 DataNode [spark@sparksinglenode ~]$ hdfs dfsadmin -safemode leave 17/08/29 05:29:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Safe mode is OFF [spark@sparksinglenode ~]$
再次执行,成功了
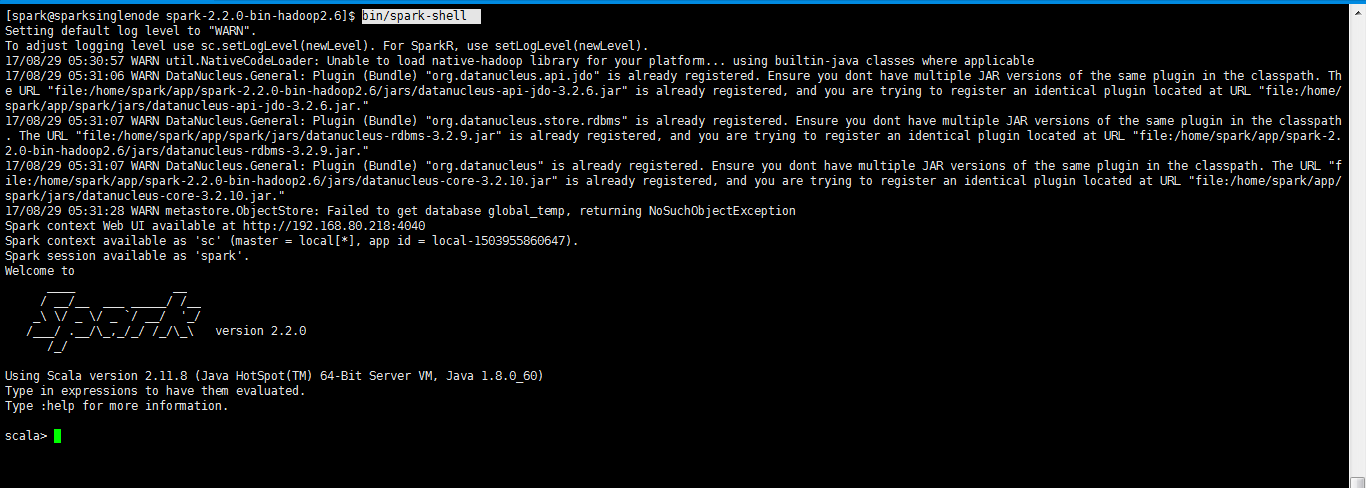
[spark@sparksinglenode spark-2.2.0-bin-hadoop2.6]$ bin/spark-shell Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 17/08/29 05:30:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 17/08/29 05:31:06 WARN DataNucleus.General: Plugin (Bundle) "org.datanucleus.api.jdo" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/home/spark/app/spark-2.2.0-bin-hadoop2.6/jars/datanucleus-api-jdo-3.2.6.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/home/spark/app/spark/jars/datanucleus-api-jdo-3.2.6.jar." 17/08/29 05:31:07 WARN DataNucleus.General: Plugin (Bundle) "org.datanucleus.store.rdbms" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/home/spark/app/spark/jars/datanucleus-rdbms-3.2.9.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/home/spark/app/spark-2.2.0-bin-hadoop2.6/jars/datanucleus-rdbms-3.2.9.jar." 17/08/29 05:31:07 WARN DataNucleus.General: Plugin (Bundle) "org.datanucleus" is already registered. Ensure you dont have multiple JAR versions of the same plugin in the classpath. The URL "file:/home/spark/app/spark-2.2.0-bin-hadoop2.6/jars/datanucleus-core-3.2.10.jar" is already registered, and you are trying to register an identical plugin located at URL "file:/home/spark/app/spark/jars/datanucleus-core-3.2.10.jar." 17/08/29 05:31:28 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException Spark context Web UI available at http://192.168.80.218:4040 Spark context available as 'sc' (master = local[*], app id = local-1503955860647). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _ / _ / _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_ version 2.2.0 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60) Type in expressions to have them evaluated. Type :help for more information. scala>
或者
[spark@sparksinglenode spark-2.2.0-bin-hadoop2.6]$ bin/spark-shell --master yarn-client
注意,这里的--master是固定参数