不多说,直接上干货!
Weka介绍:
Weka是一个用Java编写的数据挖掘工具,能够运行在各种平台上。它不仅提供了可以直接用于数据挖掘的软件,还提供了src代码,使用者可以修改源代码,进行二次开发。但是,由于其使用了Java虚拟机,导致其不适合处理大型数据,运行缓慢。处理超过一定大小数据,还会溢出heap size,使程序崩溃。但作为初学者,很适合通过处理一些小型数据集,以直观地了解各种数据挖掘方法。它还自带一些典型的数据集,可以直接使用。在安装目录下的data子目录中。
Weka通常使用ARFF文件格式的文件。也可以直接使用CSV文件格式的文件,但与传统CSV文件不同,Weka能识别的CSV文件要求第一行给各列的定义。因为CSV文件比较容易获得,excel表格文件可以直接另存为csv文件。推荐使用csv文件。
以著名数据挖掘数据集鸢尾花为例,该数据集对应的iris.csv文件应如下所示:
sepal-length,sepal-width,petal-length,petal-width,class 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa
1、使用Weka工具,将ARFF文件转换成CSV文件

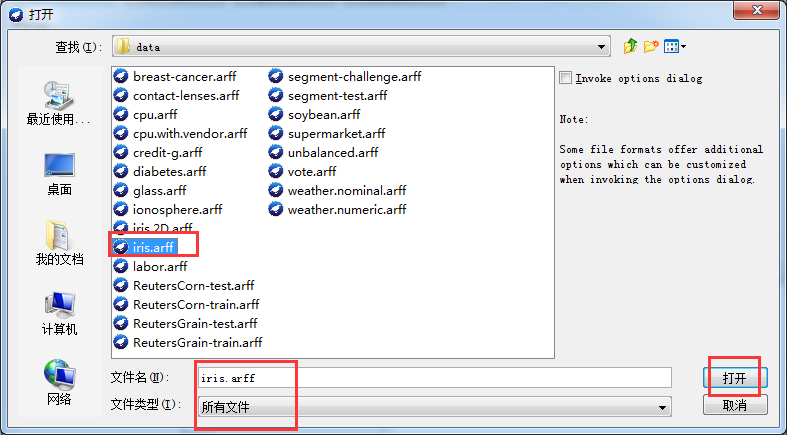
进入Explorer模块,点击界面上方的按钮“open file”打开文件选择面板,将面板下方的文件类型选择“所有文件”,找到
iris.arff文件即可将数据导入到Explorer如下图所示。


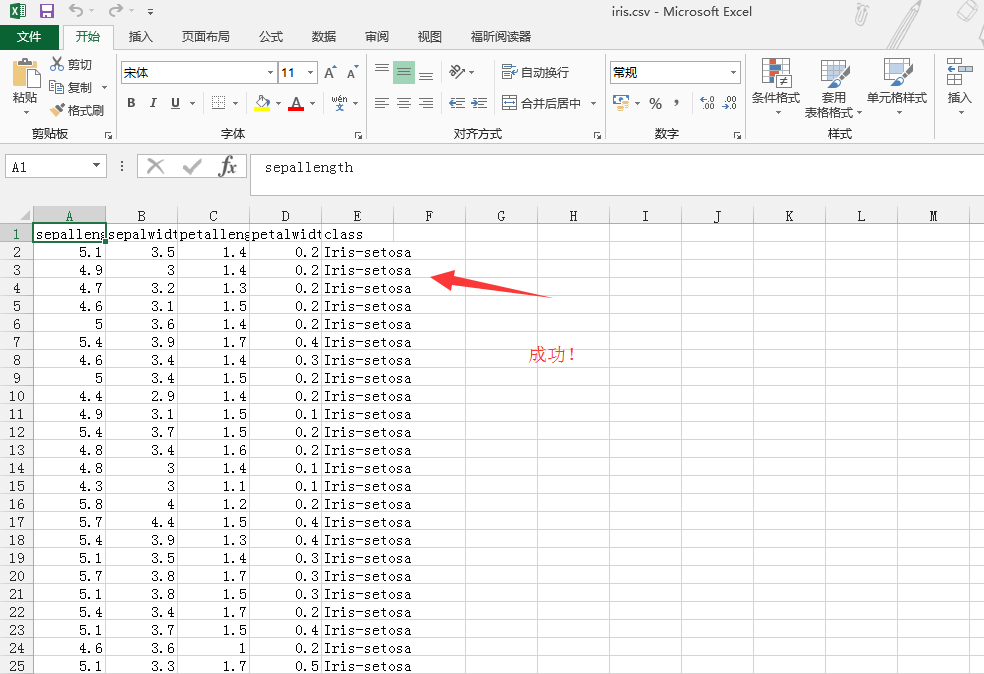
得到




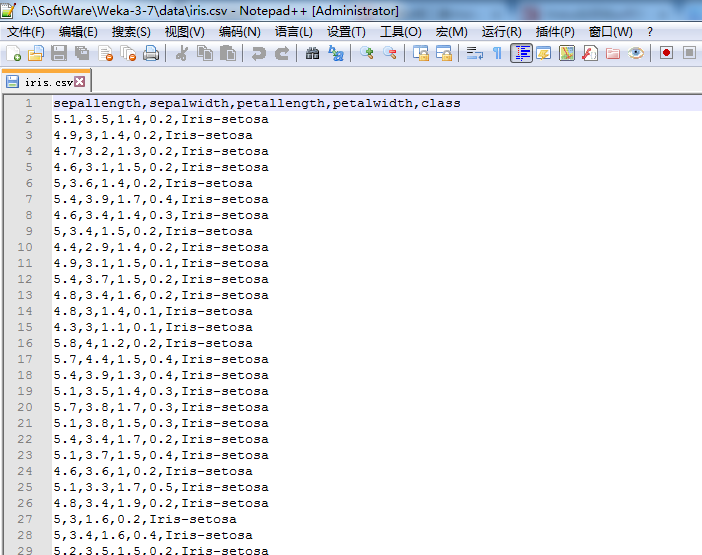
2、使用Weka工具,将CSV文件转换成ARFF文件
打开Weka的Explorer界面
比如,这里,我先把iris.arff拷贝到桌面去。
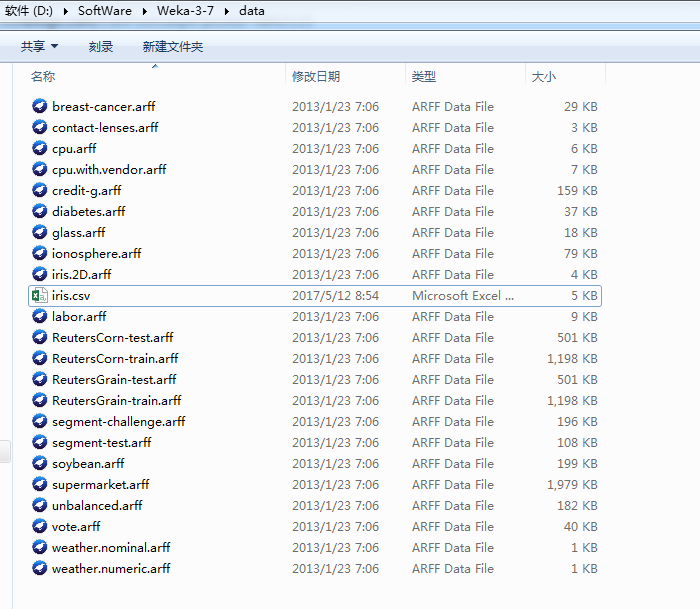
然后,在preprocess->open file

将面板下方的文件类型选择“所有文件”,找到iris.csv
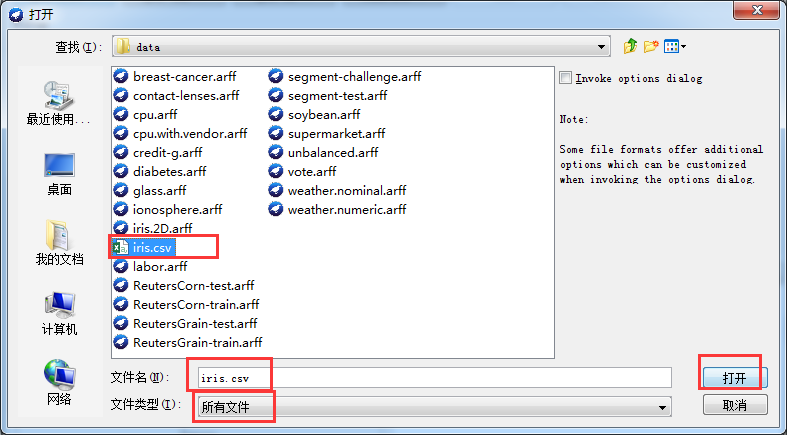

通过save可以将CSV文件另存为ARFF文件。格式如下图所示:


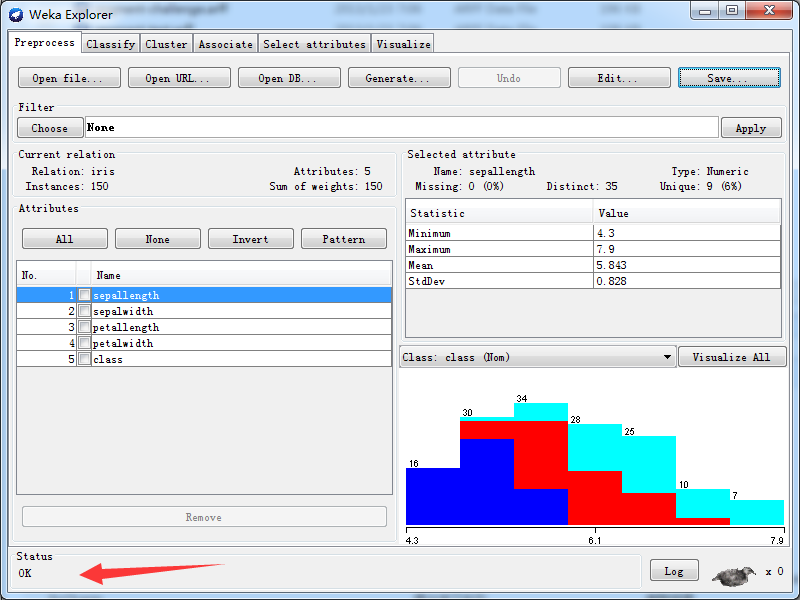
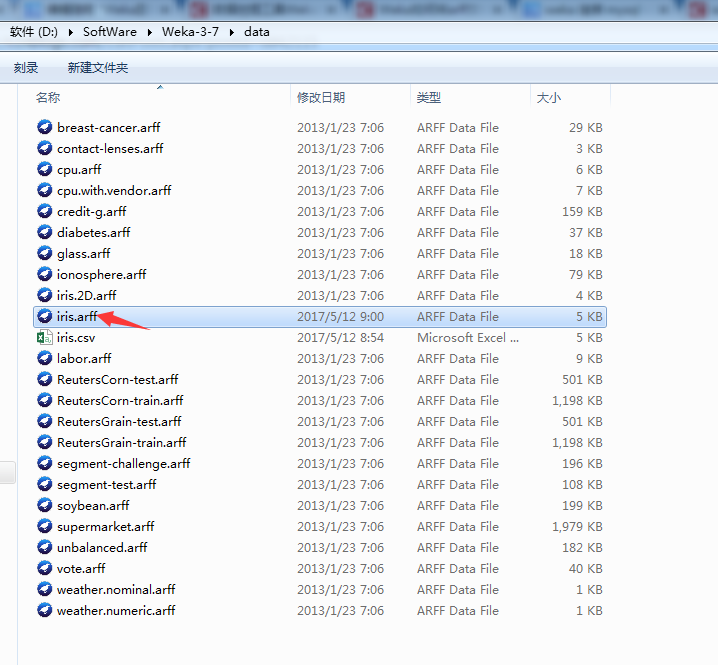
成功!