Spark SQL基本原理
1、Spark SQL模块划分
2、Spark SQL架构--catalyst设计图
3、Spark SQL运行架构
4、Hive兼容性
1、Spark SQL模块划分


Spark SQL模块划分为Core、caralyst、hive和hive- ThriftServer四大模块。
Spark SQL依然是读取数据进去,然后你可以执行sql操作,然后你还可以执行其他的结构化操作,不光仅仅是只能sql操作哈!这一点,很多人都没理解到位。
也有数据的输入和输出的工作。
比如,Spark SQL模块里的core模块,就是为了处理数据的输入输出。将查询结果输出成DataFrame。具体见上图。
Spark SQL模块里的catalyst模块。具体见上图。
Spark SQL模块里的hive模块,对hive数据的处理。具体见上图。
Spark SQL模块里的hive -ThriftServer模块,具体见上图。
2、Spark SQL架构--catalyst设计图(这里说Spark SQL模块里的catalyst模块!!)
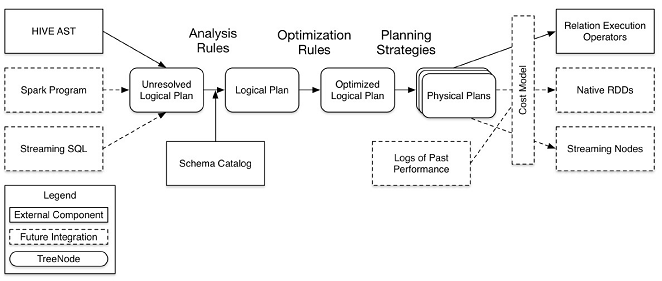
注意:图中的虚线部分是现在未实现或实现不完善的。
其中虚线部分是以后版本要实现的功能,实线部分是已经实现的功能。从上图看,catalyst主要的实现组件有:
sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
optimizer,对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan(OptimizationRules,对resolvedLogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan);
Planner,将LogicalPlan转换成PhysicalPlan;
CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划。
3、Spark SQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、DataSource(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。

执行SparkSQL语句顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、DataSource等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->DataSource-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
4、Hive兼容性
支持使用hql来写查询语句
兼容metastore
使用Hive的SerDes
对UDFs, UDAFs, UDTFs作了封装。