本博文的主要内容有
.kafka整合storm
.storm-kafka工程
.storm + kafka的具体应用场景有哪些?

要想kafka整合storm,则必须要把这个storm-kafka-0.9.2-incubating.jar,放到工程里去。
无非,就是storm要去拿kafka里的东西,


storm-kafka工程
我们自己,在storm-kafka工程里,写,
KafkaTopo.java、 WordSpliter.java、WriterBolt.java、
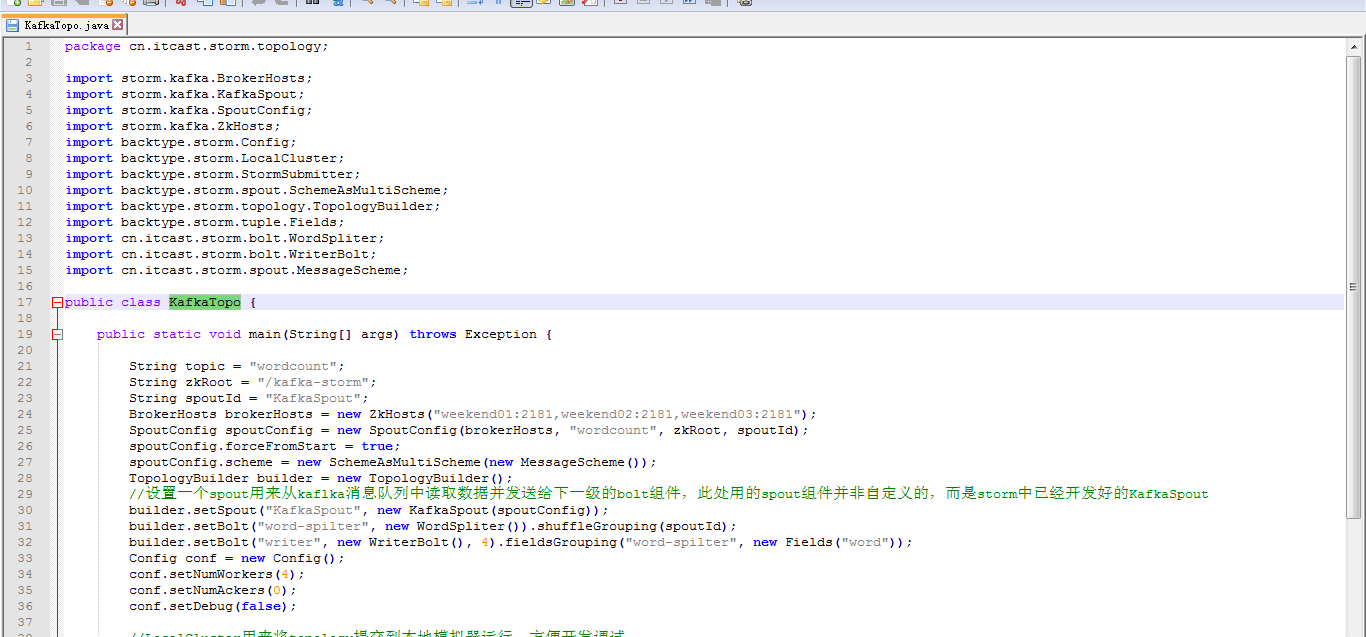
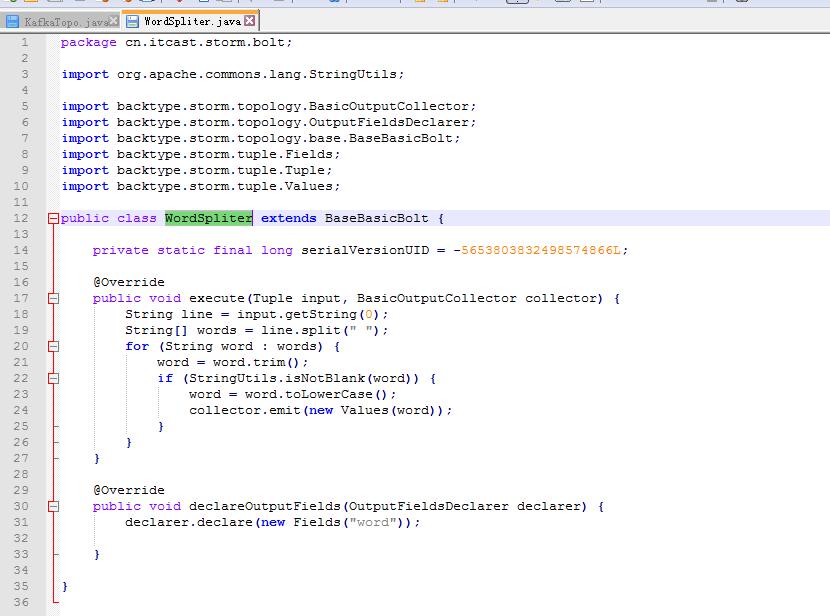

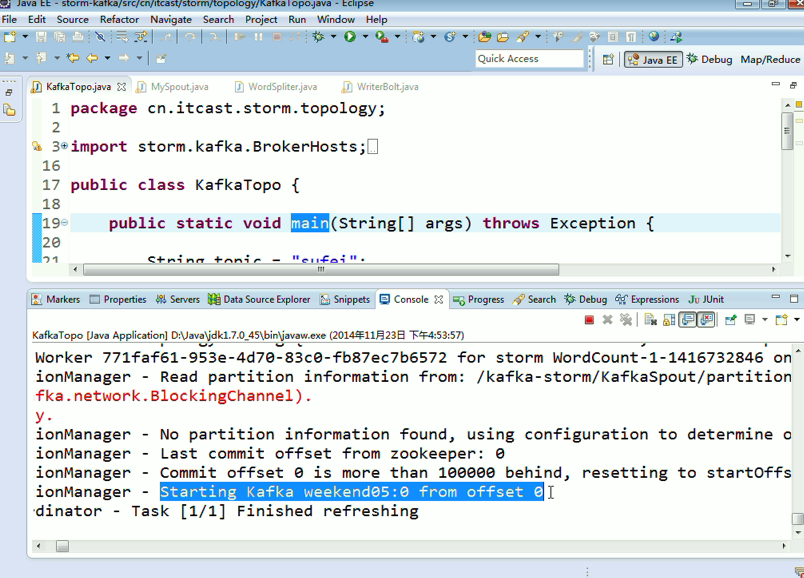
这里,把话题wordcount改为,sufei,即可。

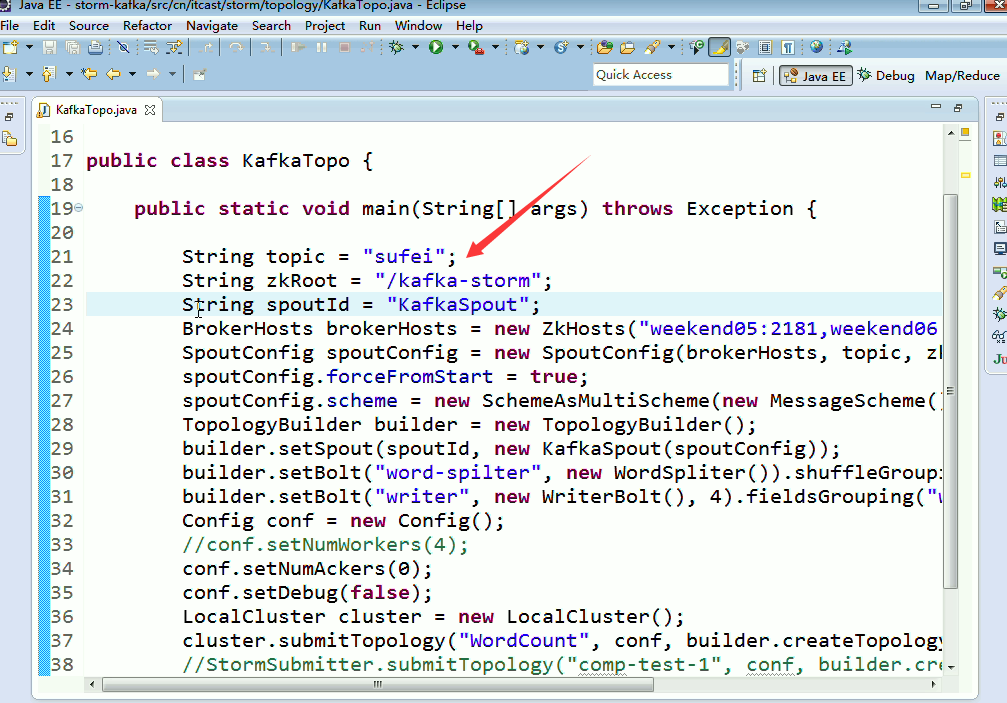


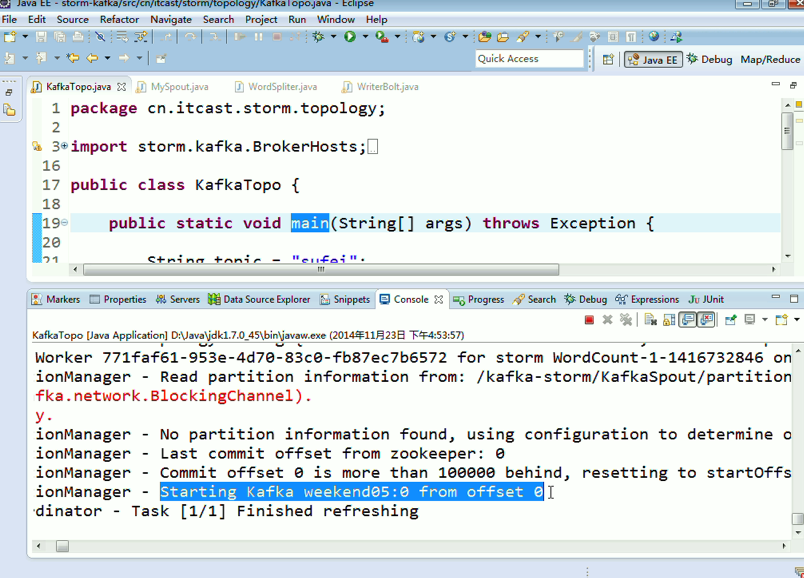

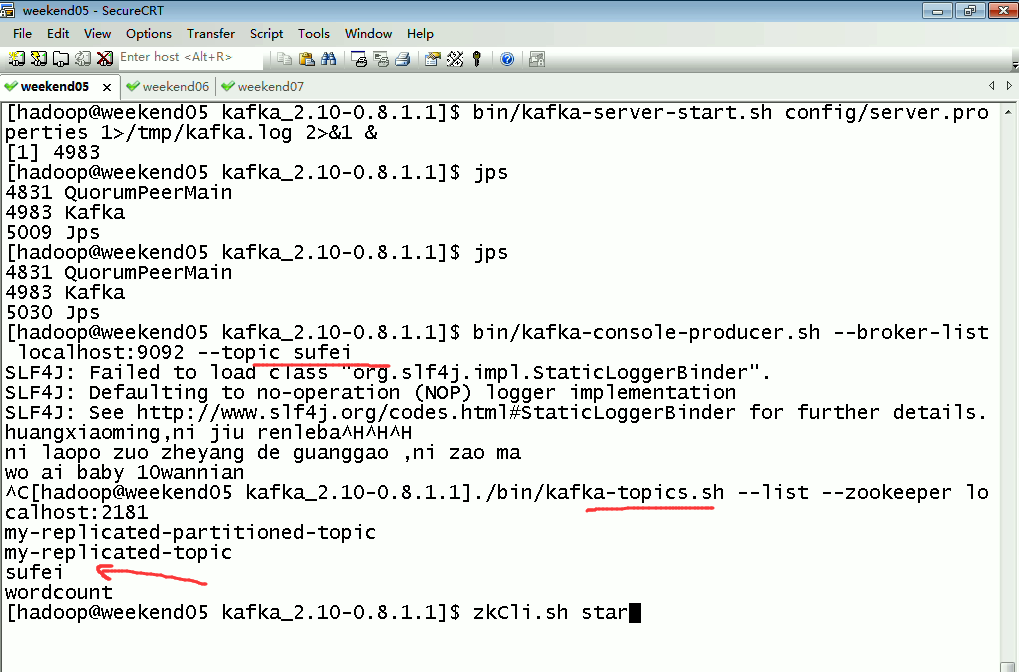
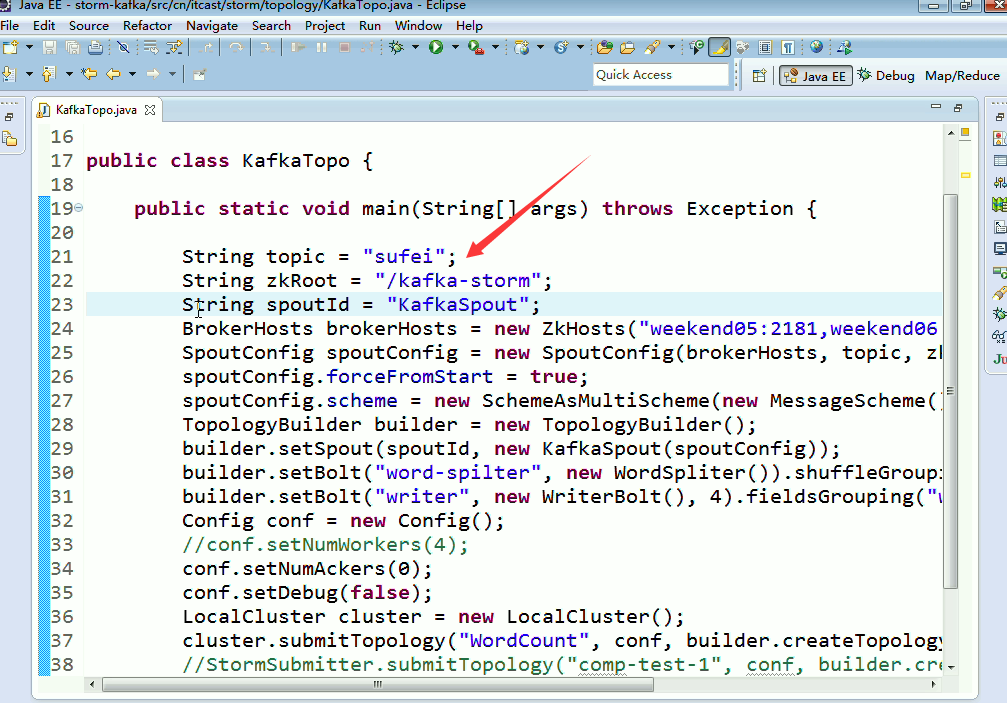





KafkaTopo.java
package cn.itcast.storm.topology;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import cn.itcast.storm.bolt.WordSpliter;
import cn.itcast.storm.bolt.WriterBolt;
import cn.itcast.storm.spout.MessageScheme;
public class KafkaTopo {
public static void main(String[] args) throws Exception {
String topic = "wordcount";
String zkRoot = "/kafka-storm";
String spoutId = "KafkaSpout";
BrokerHosts brokerHosts = new ZkHosts("weekend01:2181,weekend02:2181,weekend03:2181");
SpoutConfig spoutConfig = new SpoutConfig(brokerHosts, "wordcount", zkRoot, spoutId);
spoutConfig.forceFromStart = true;
spoutConfig.scheme = new SchemeAsMultiScheme(new MessageScheme());
TopologyBuilder builder = new TopologyBuilder();
//设置一个spout用来从kaflka消息队列中读取数据并发送给下一级的bolt组件,此处用的spout组件并非自定义的,而是storm中已经开发好的KafkaSpout
builder.setSpout("KafkaSpout", new KafkaSpout(spoutConfig));
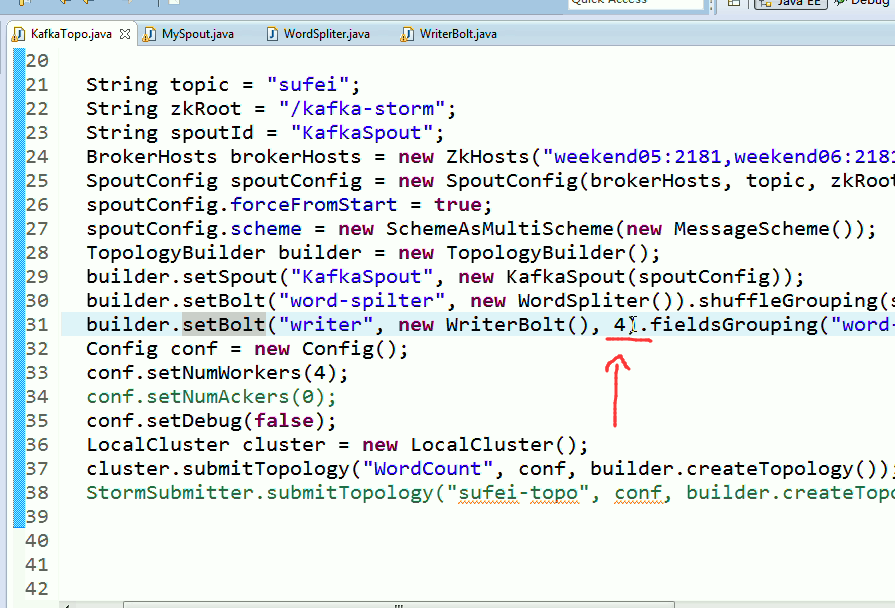
builder.setBolt("word-spilter", new WordSpliter()).shuffleGrouping(spoutId);
builder.setBolt("writer", new WriterBolt(), 4).fieldsGrouping("word-spilter", new Fields("word"));
Config conf = new Config();
conf.setNumWorkers(4);
conf.setNumAckers(0);
conf.setDebug(false);
//LocalCluster用来将topology提交到本地模拟器运行,方便开发调试
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCount", conf, builder.createTopology());
//提交topology到storm集群中运行
// StormSubmitter.submitTopology("sufei-topo", conf, builder.createTopology());
}
}
WordSpliter.java
package cn.itcast.storm.bolt;
import org.apache.commons.lang.StringUtils;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class WordSpliter extends BaseBasicBolt {
private static final long serialVersionUID = -5653803832498574866L;
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
word = word.trim();
if (StringUtils.isNotBlank(word)) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WriterBolt.java
package cn.itcast.storm.bolt;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Map;
import java.util.UUID;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
/**
* 将数据写入文件
*
*
*/
public class WriterBolt extends BaseBasicBolt {
private static final long serialVersionUID = -6586283337287975719L;
private FileWriter writer = null;
@Override
public void prepare(Map stormConf, TopologyContext context) {
try {
writer = new FileWriter("c:\storm-kafka\" + "wordcount"+UUID.randomUUID().toString());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String s = input.getString(0);
try {
writer.write(s);
writer.write(" ");
writer.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
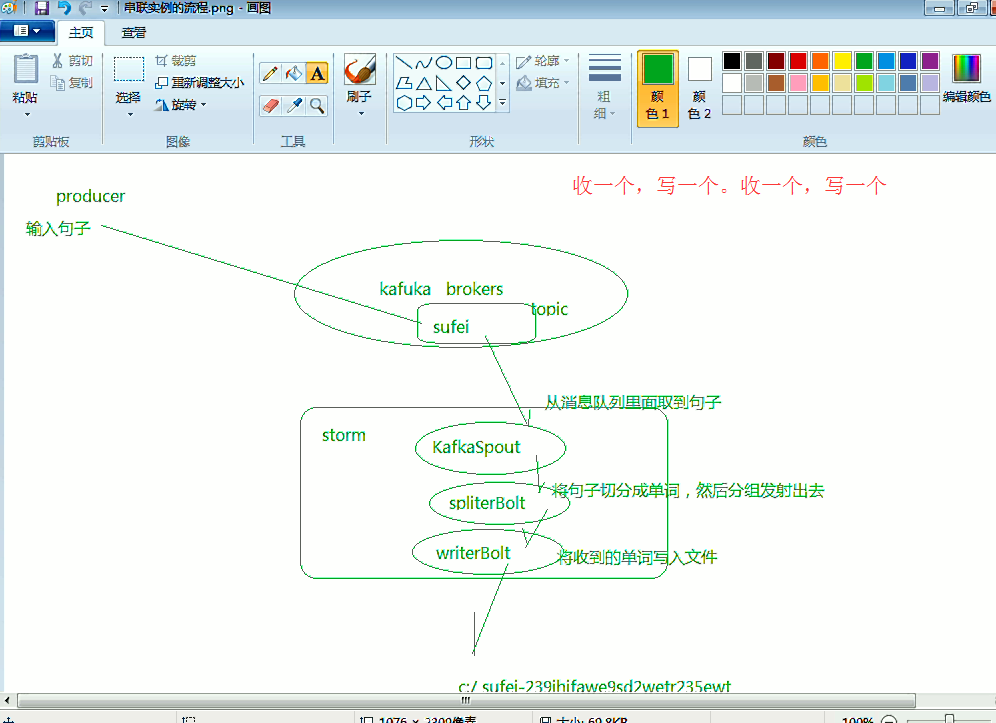
storm + kafka的具体应用场景有哪些?
手机位置的,在基站的实时轨迹分析。
Storm,是可以做实时分析,但是你,若没有个消息队列的话,你那消息,当storm死掉之后,中间那段时间,消息都没了。而,你若采用storm + kafka,则把那中间段时间的消息缓存下。
初步可以这么理解,storm + kafka,把kafka理解为缓存,只不过这个缓存,可以分区域。实际上,处理业务逻辑的是,storm。