
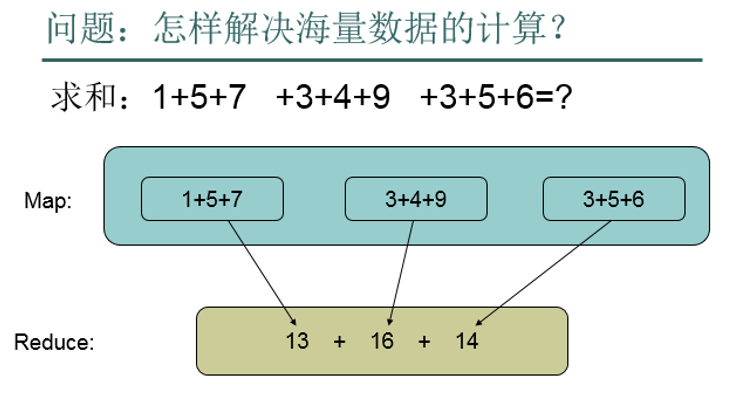
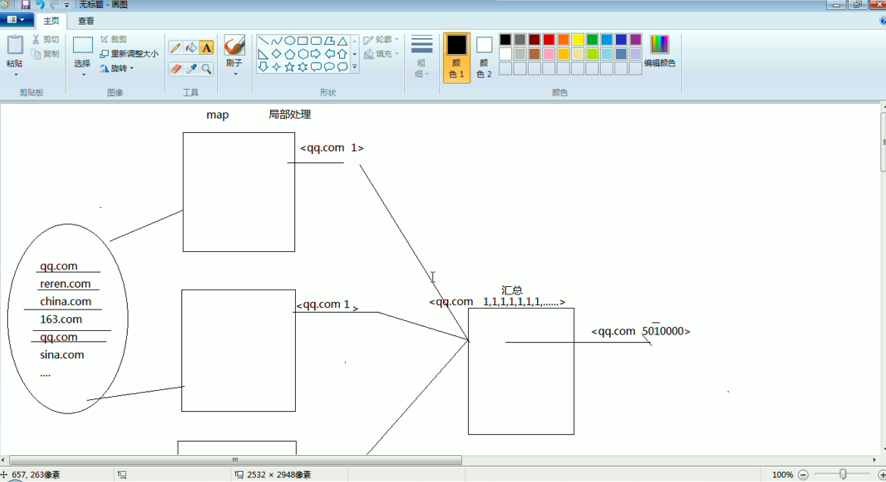
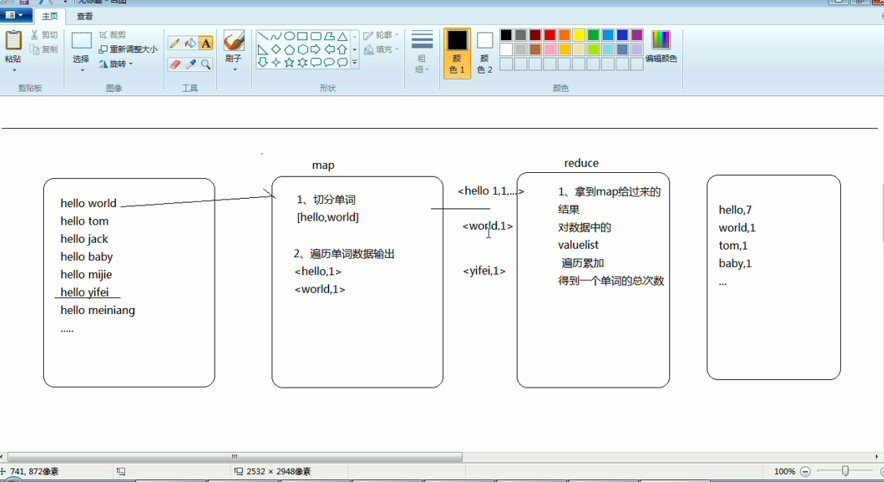
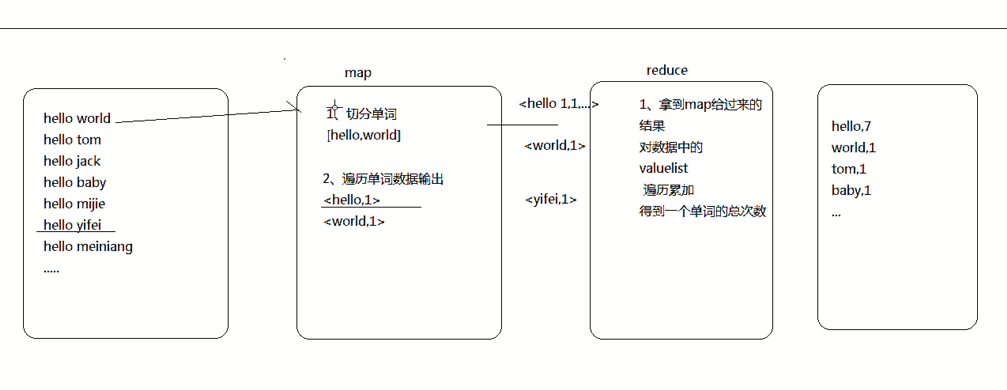
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算。
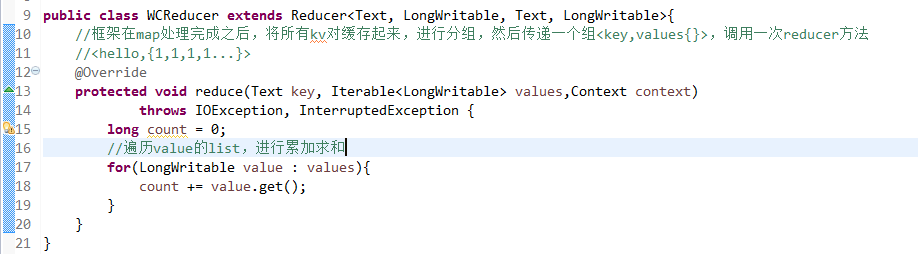
Map作一些,数据的局部处理和打散工作。
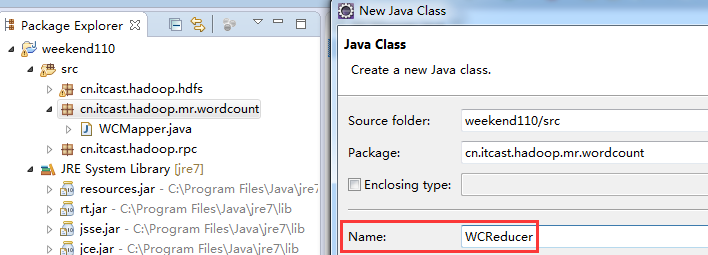
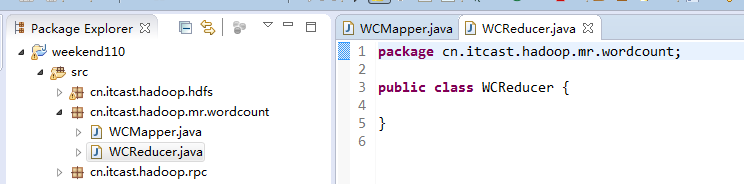
Reduce作一些,数据的汇总工作。
这是之前的,weekend110的hdfs输入流之源码分析。现在,全部关闭断点。
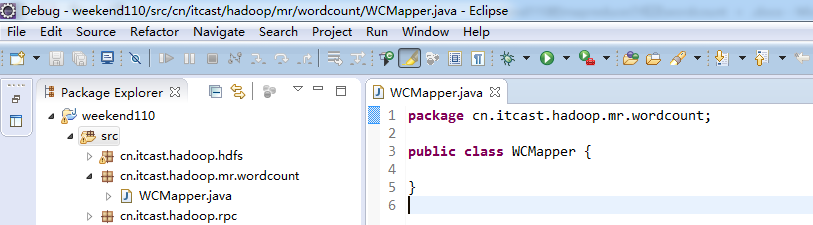
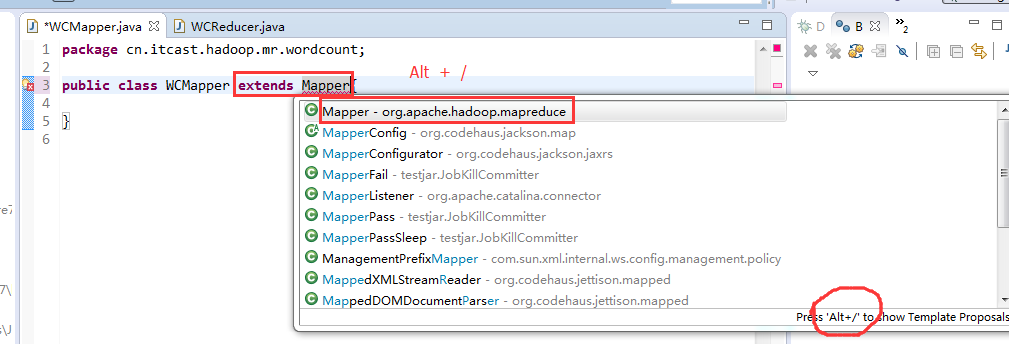
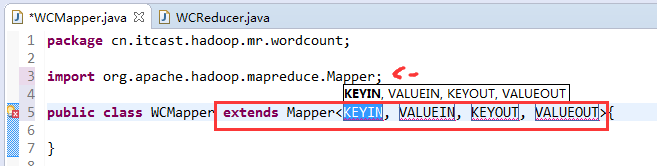
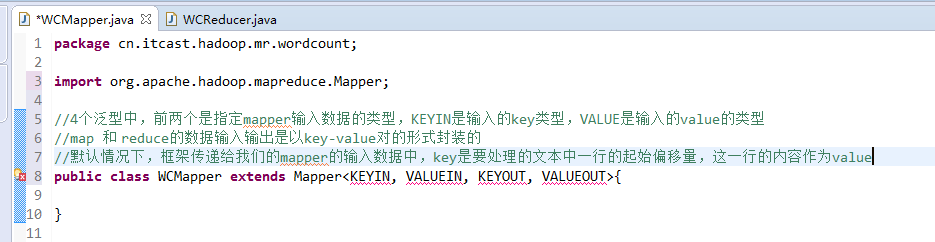
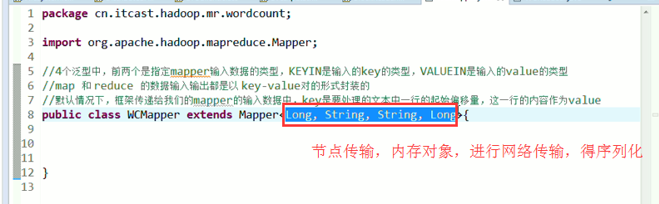

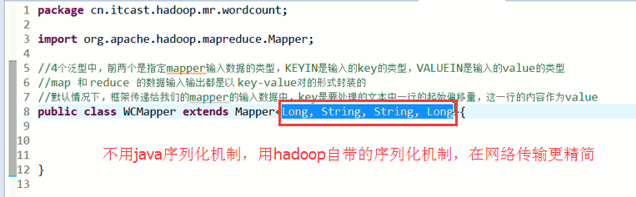

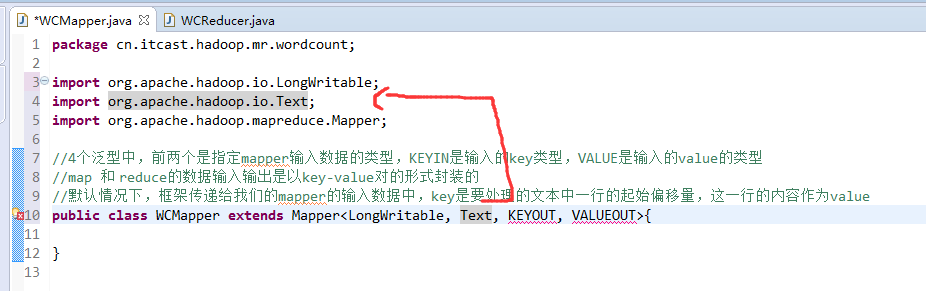
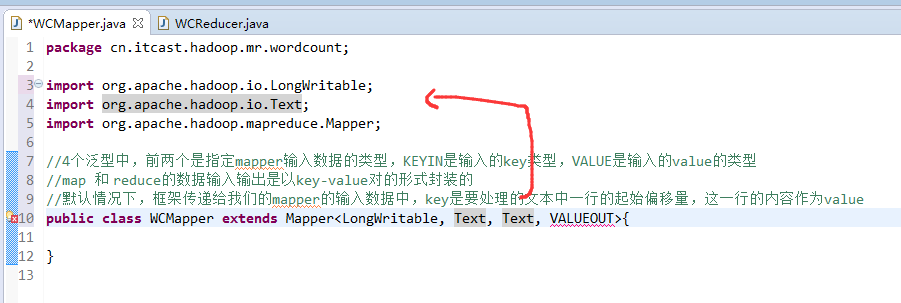
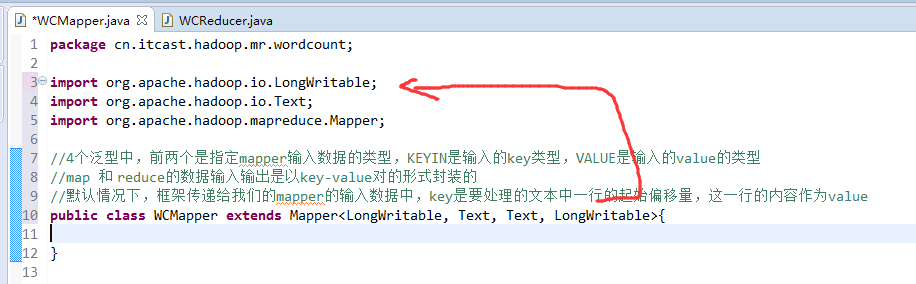
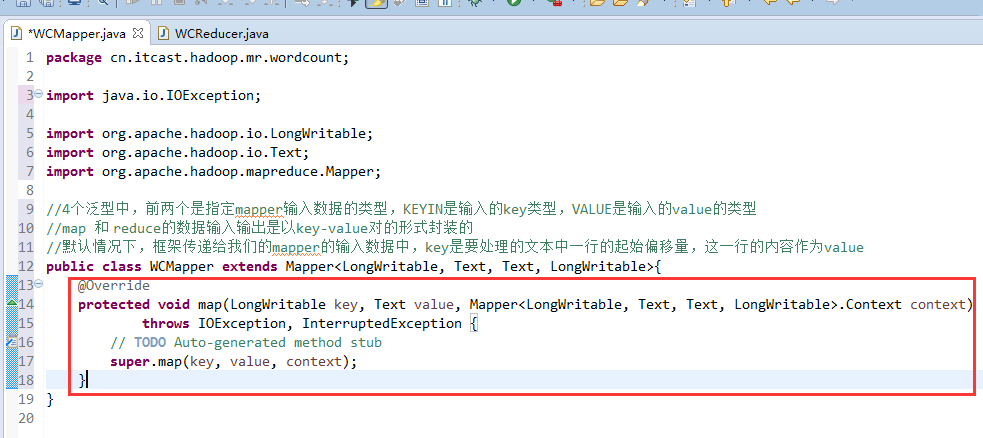
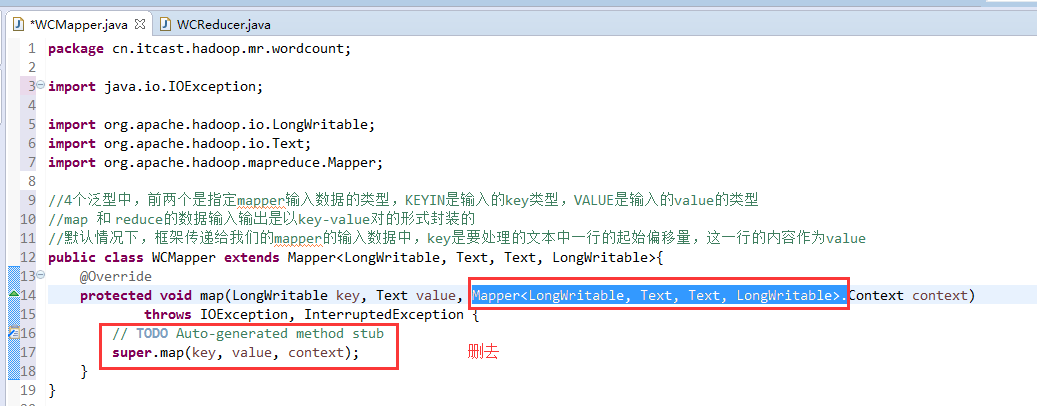
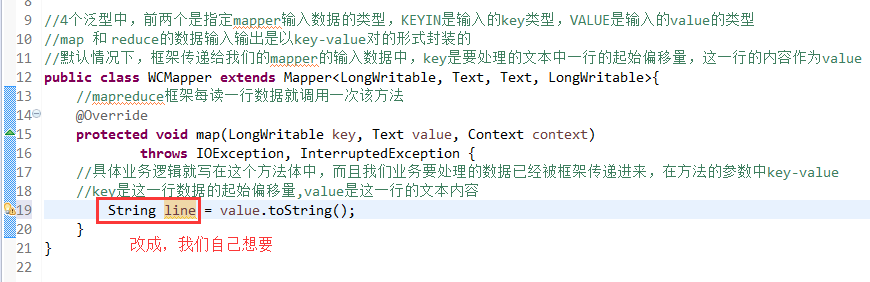
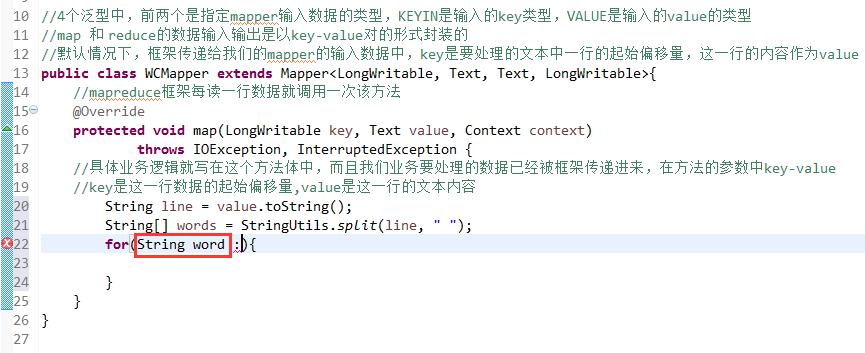
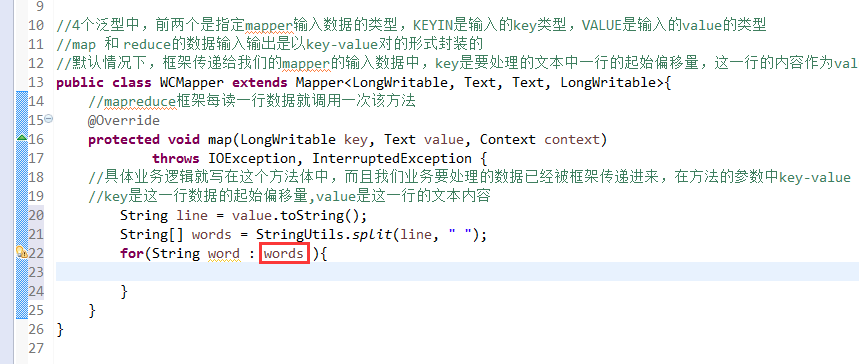
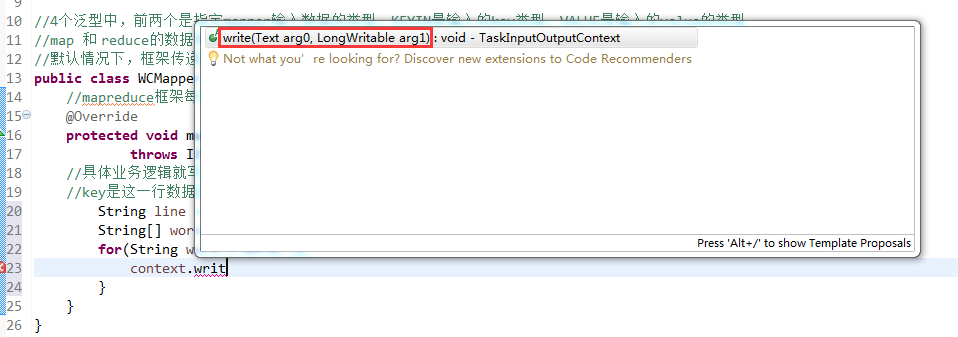
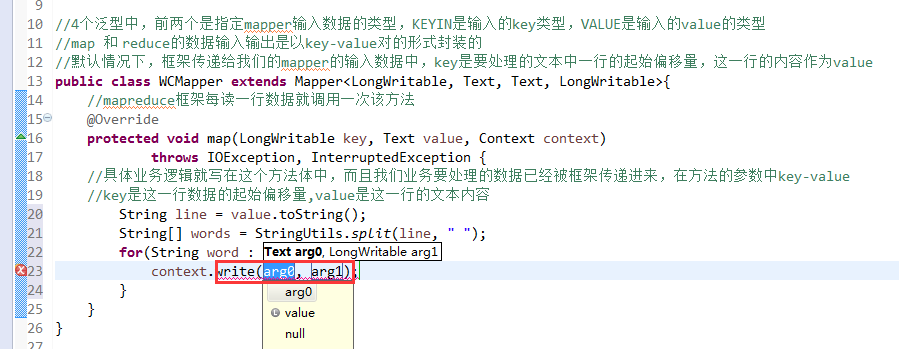
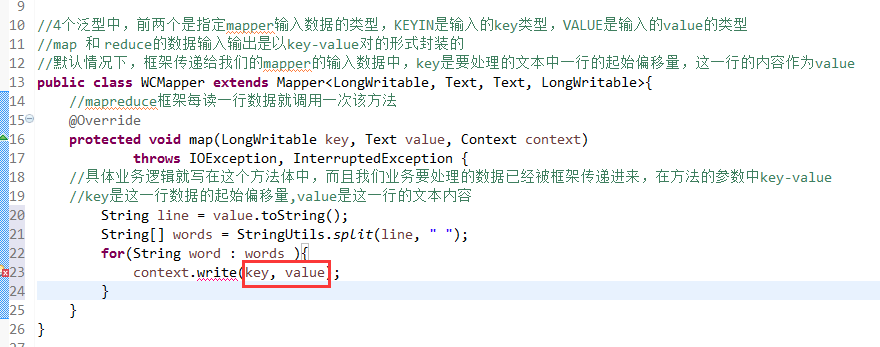
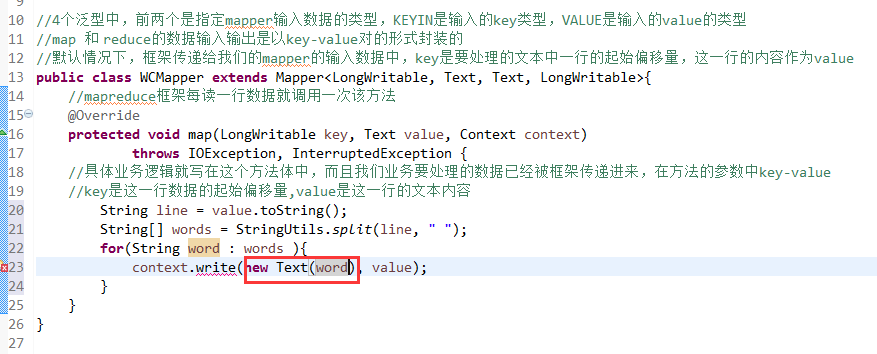
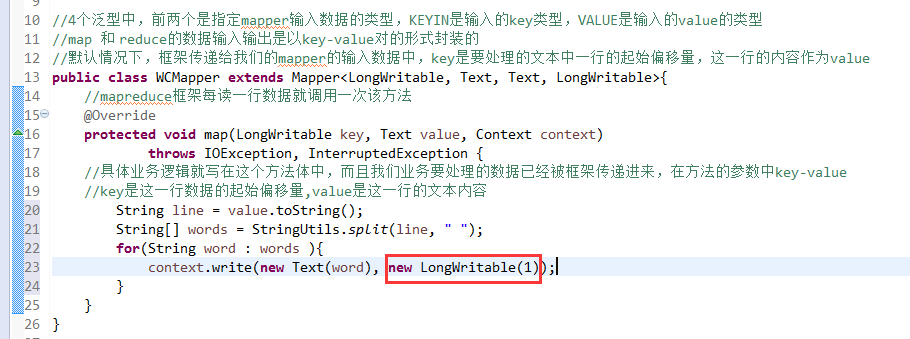
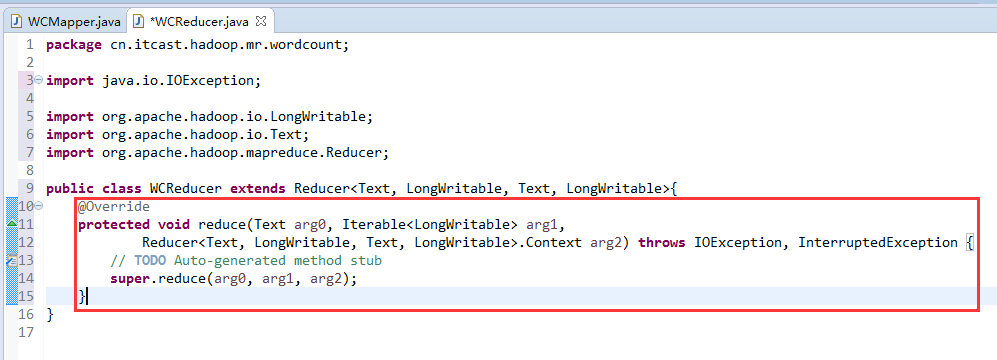
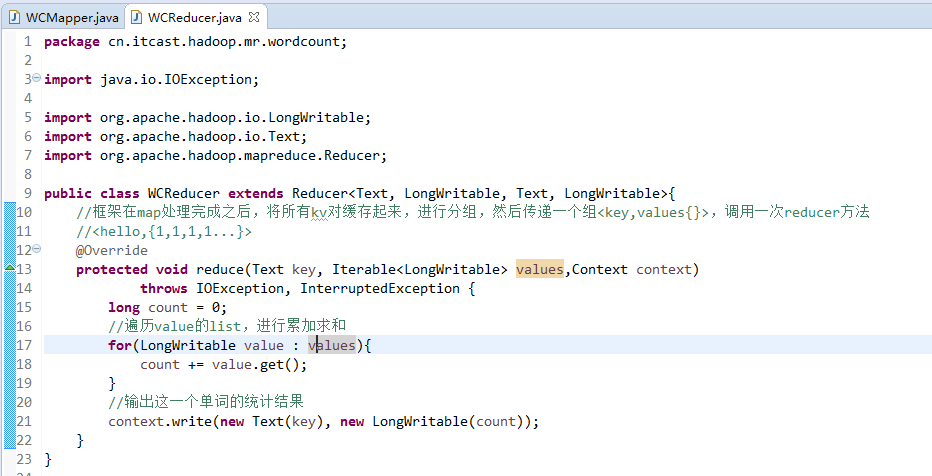
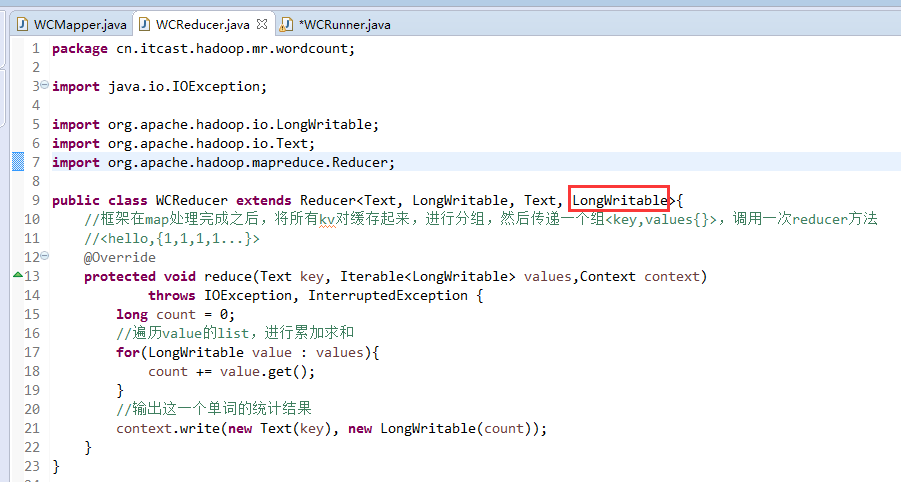
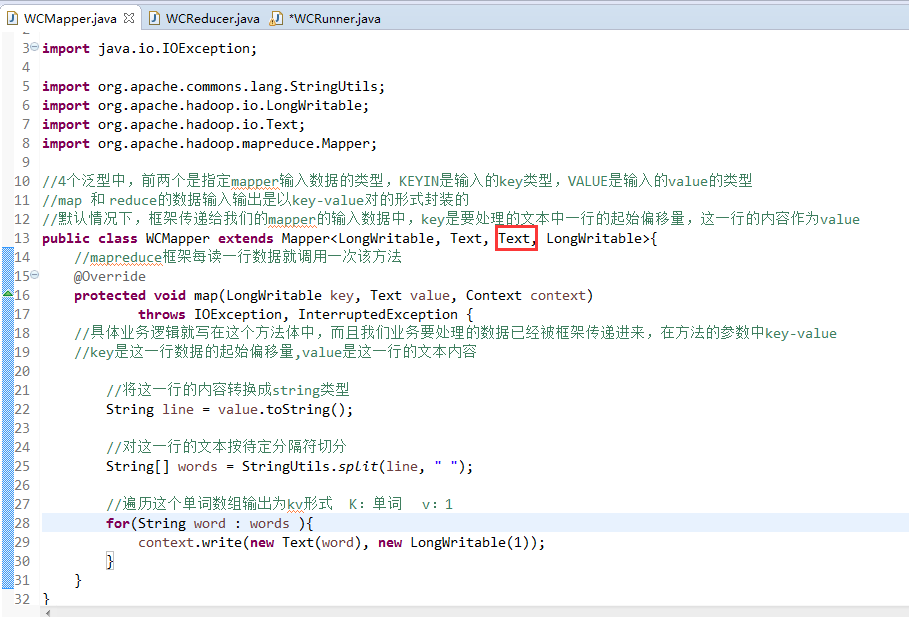
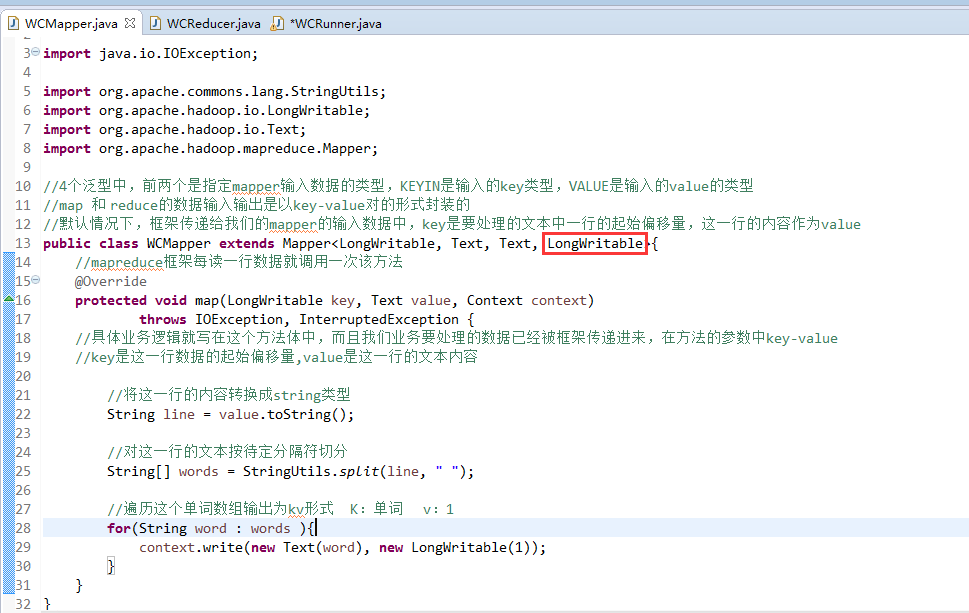
//4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key类型,VALUE是输入的value的类型
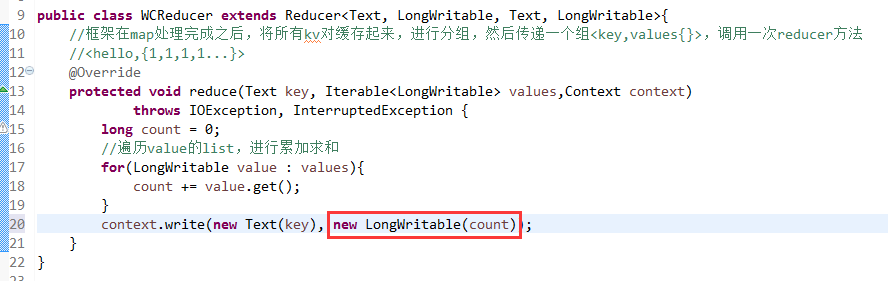
//map 和 reduce的数据输入输出是以key-value对的形式封装的
//默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value
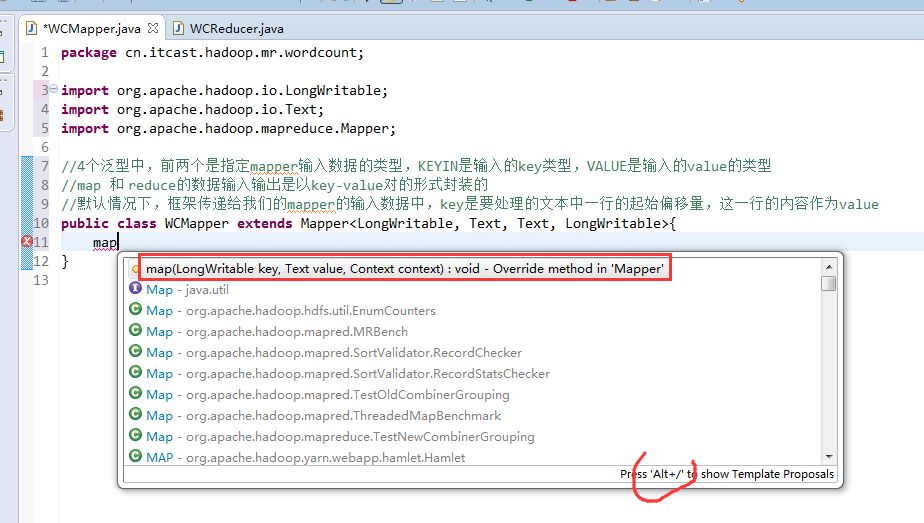
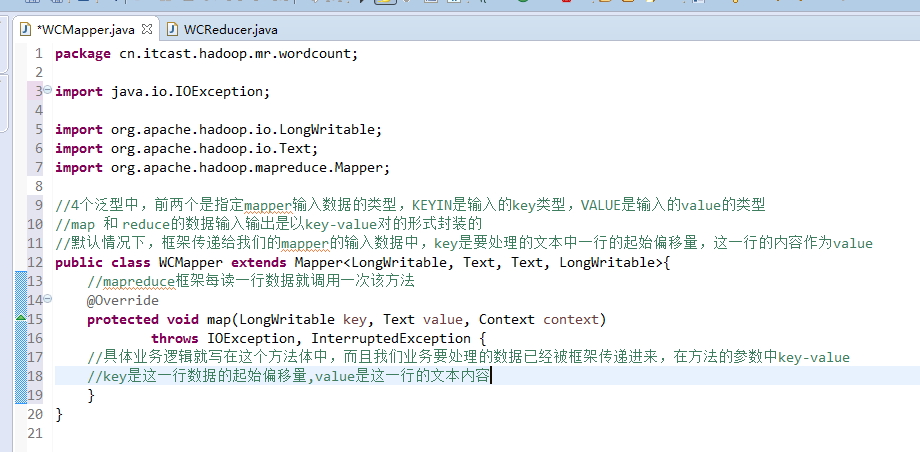
//mapreduce框架每读一行数据就调用一次该方法
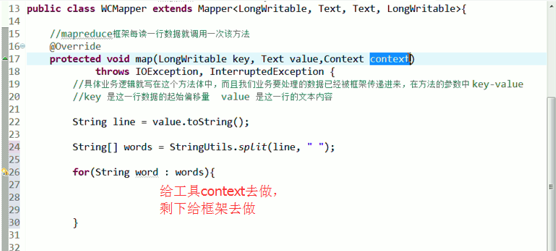
//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value
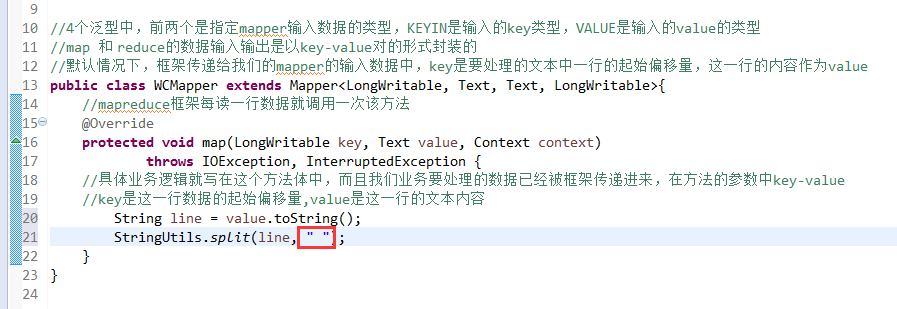
//key是这一行数据的起始偏移量,value是这一行的文本内容
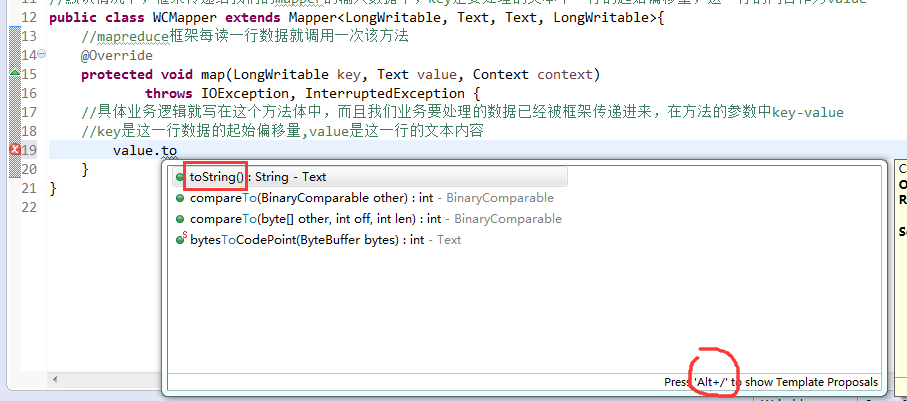
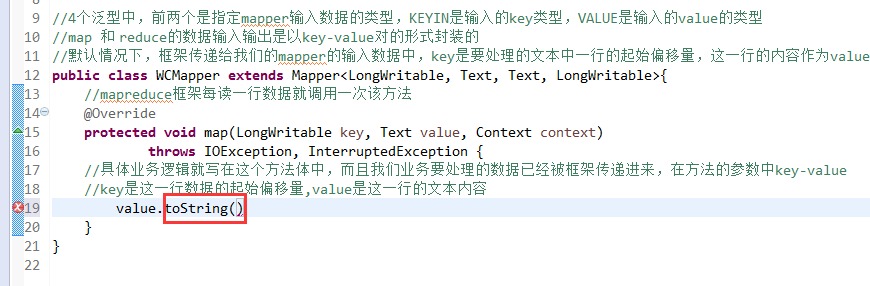
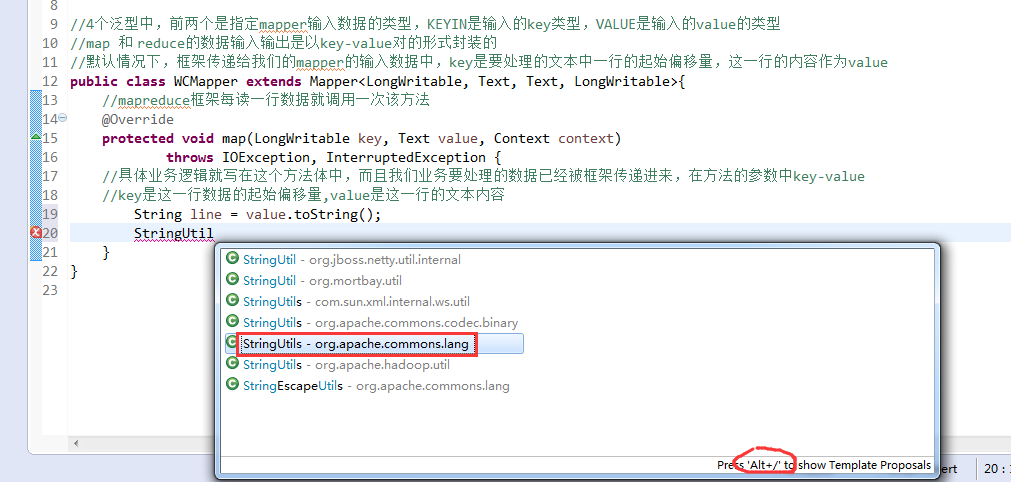


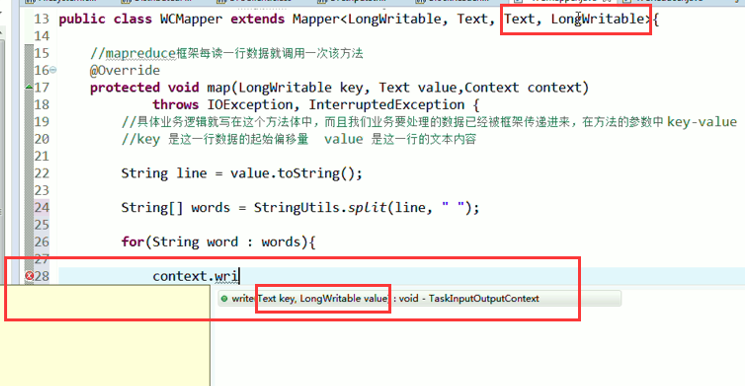

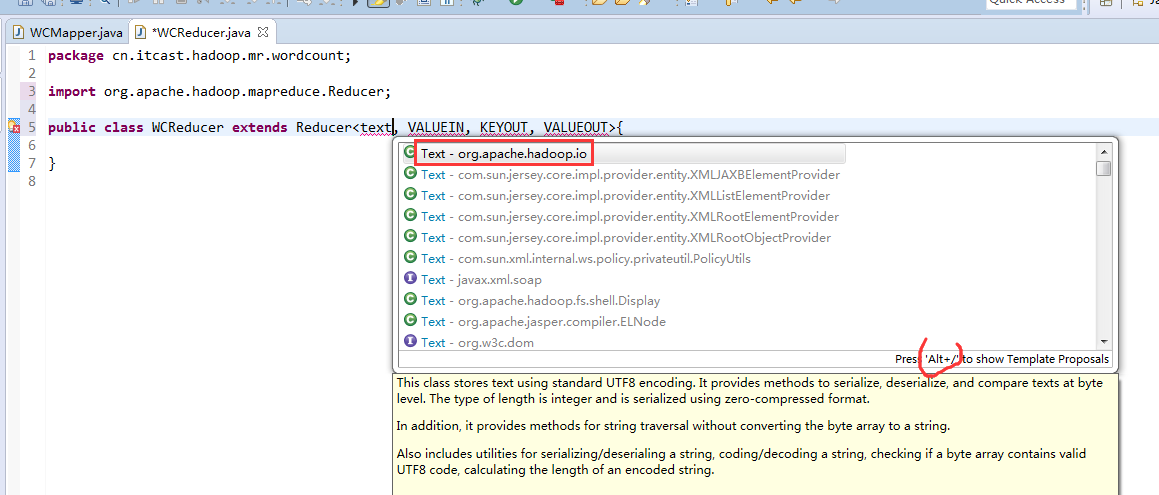
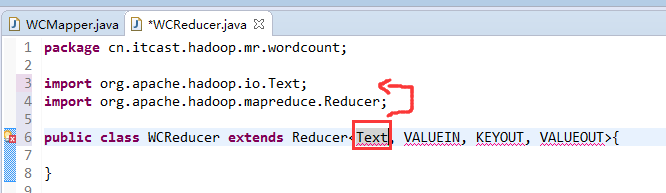
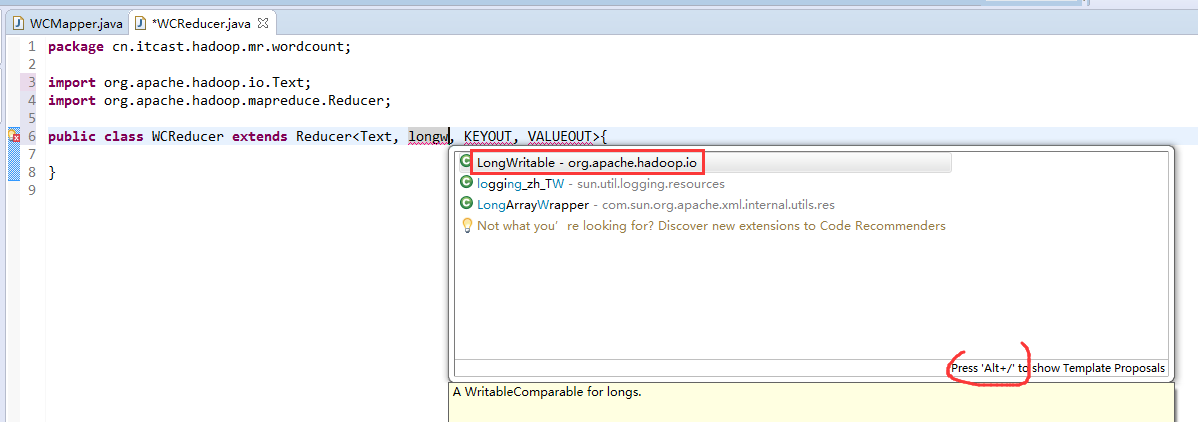
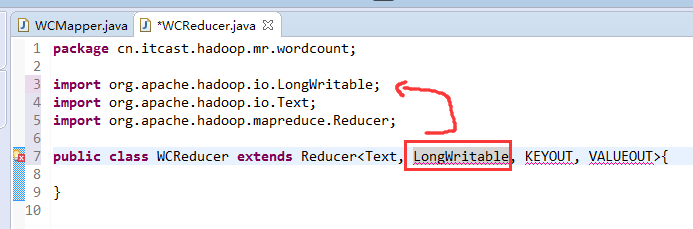
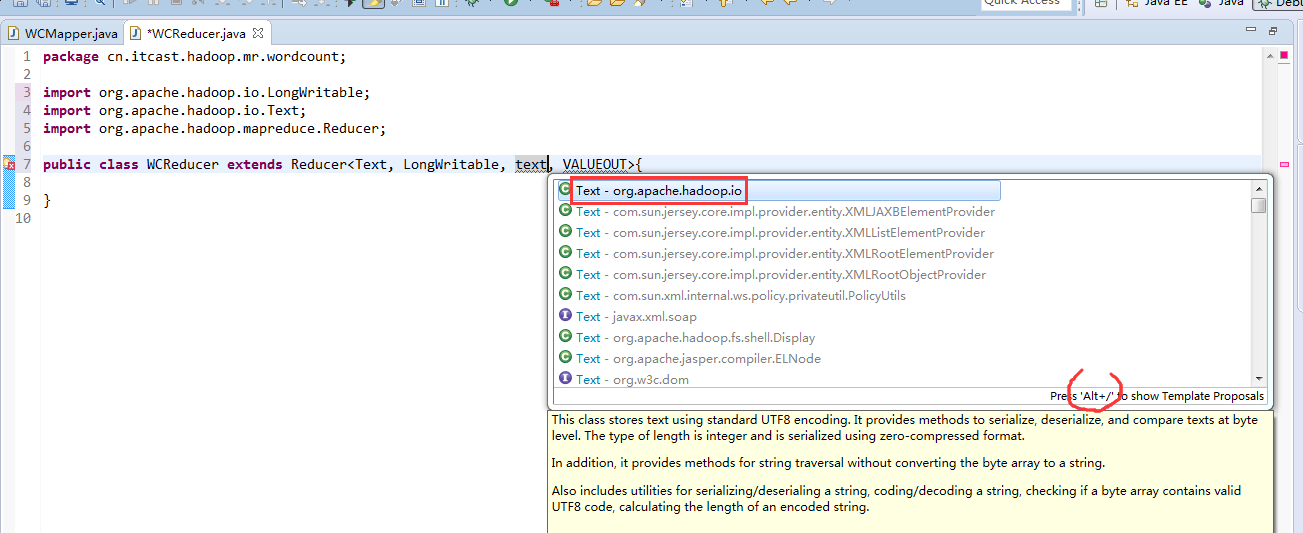

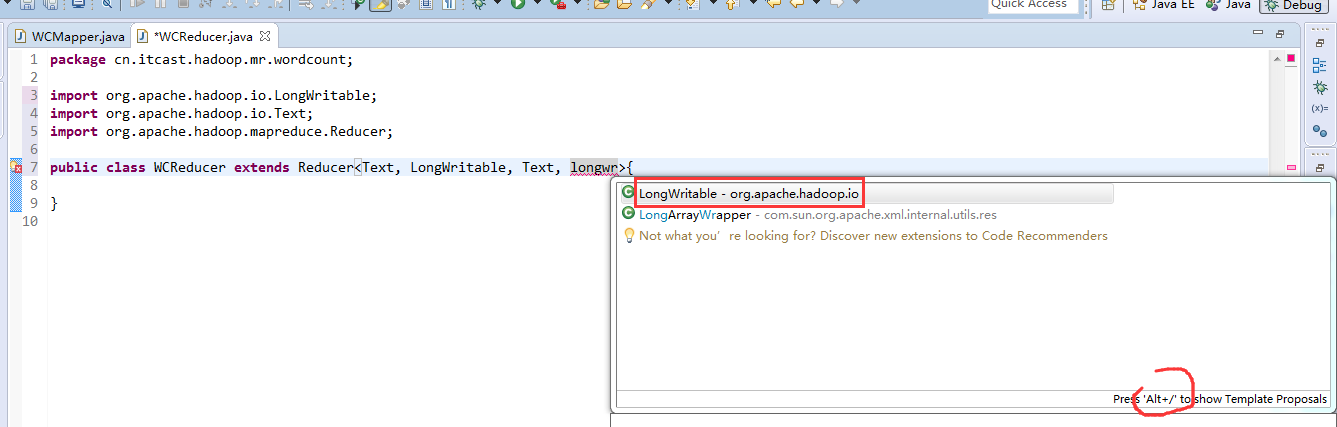
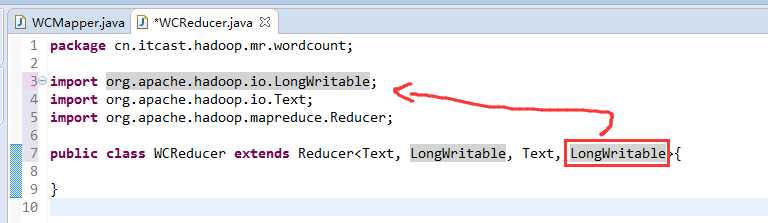

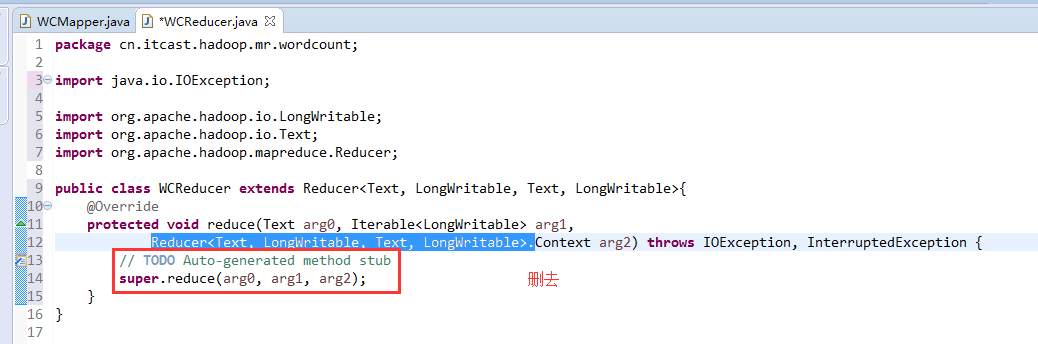
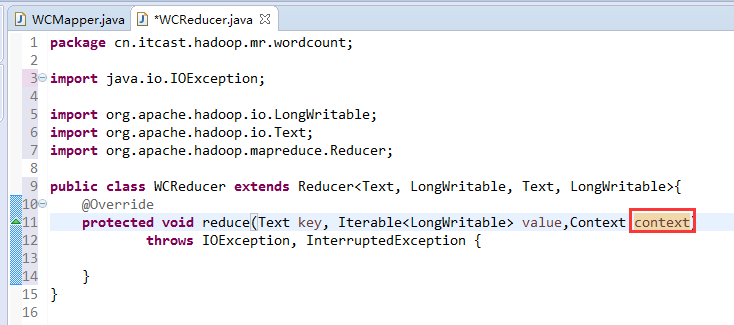
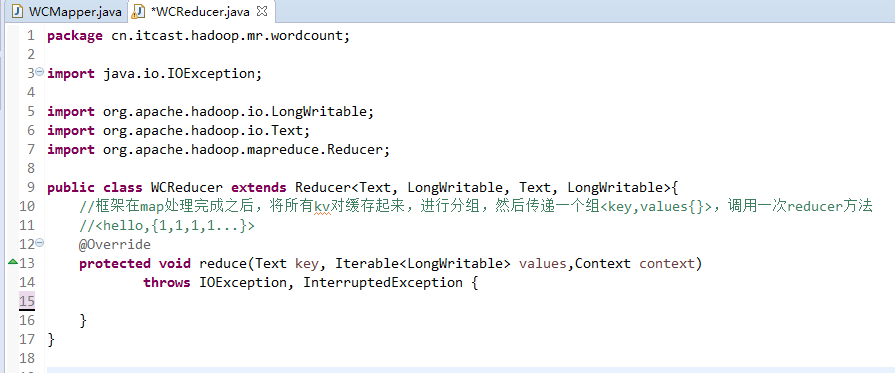
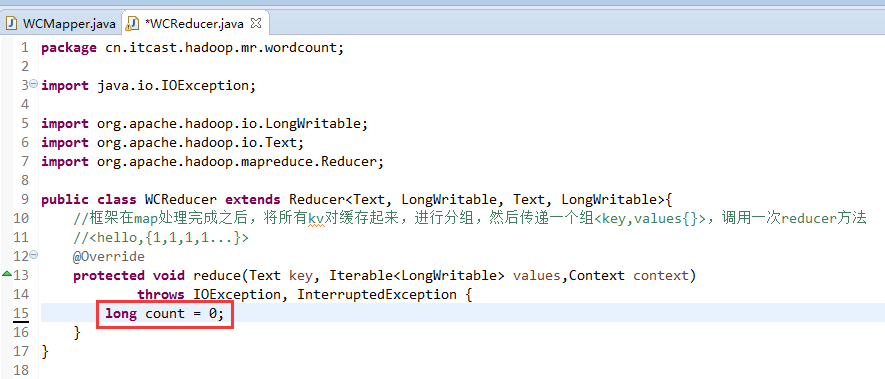

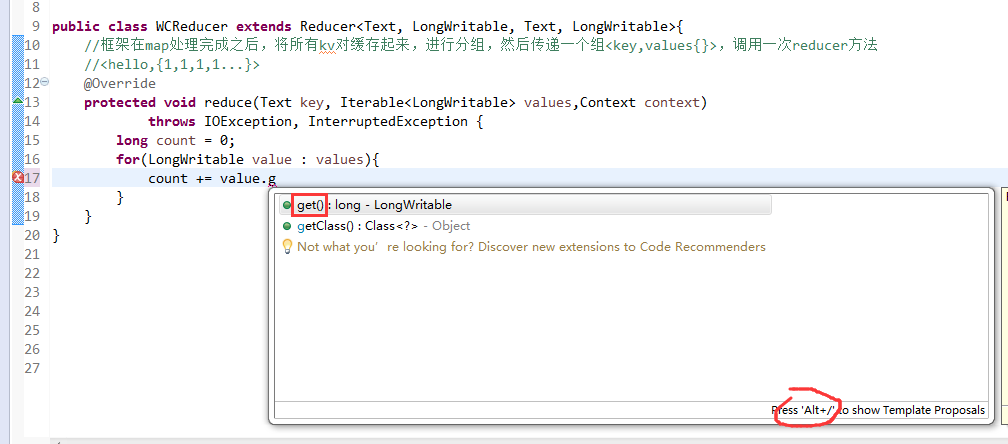



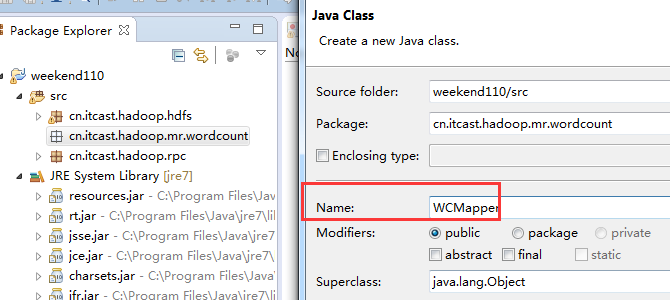
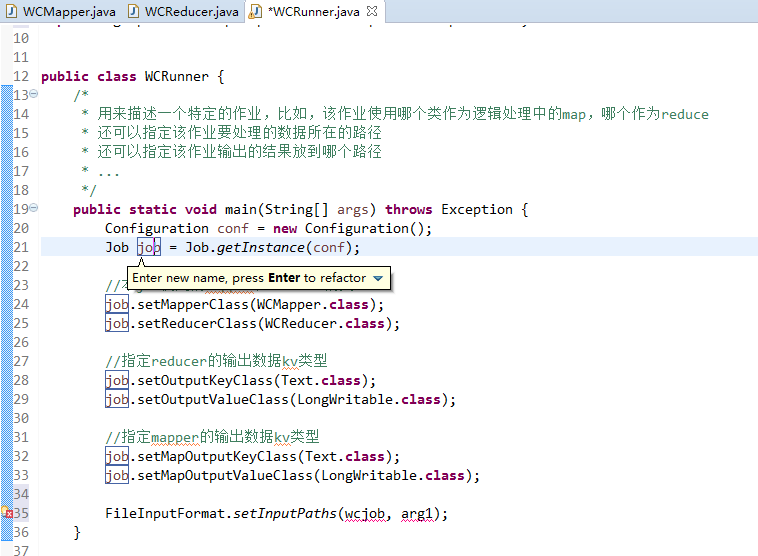
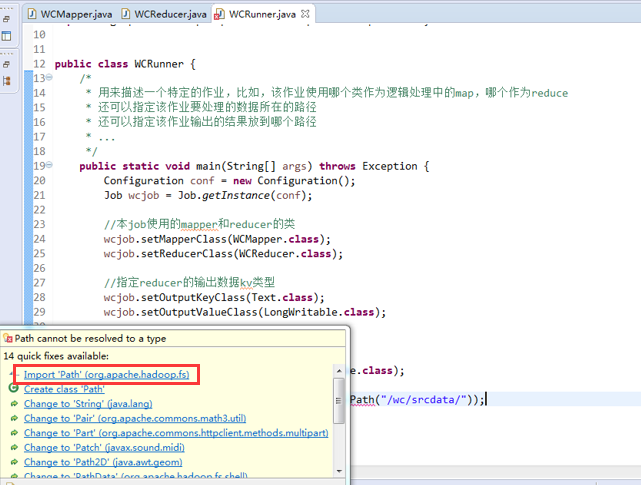
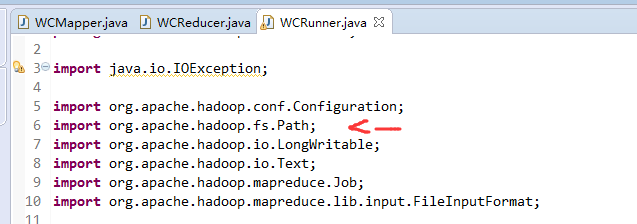
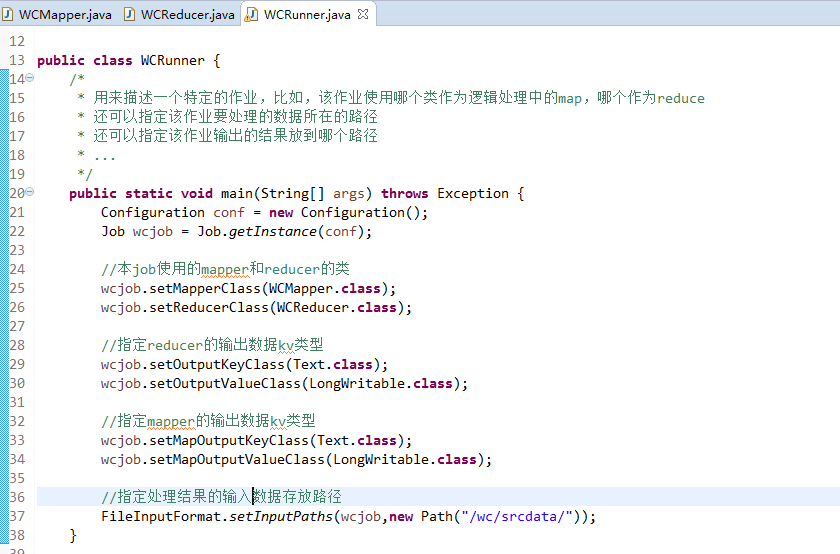
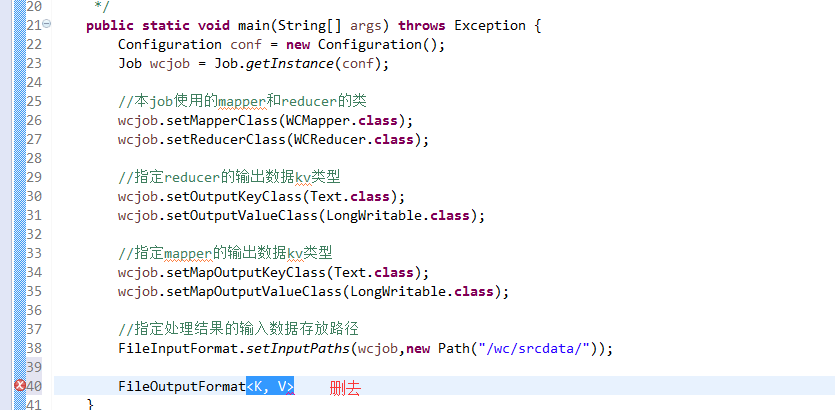
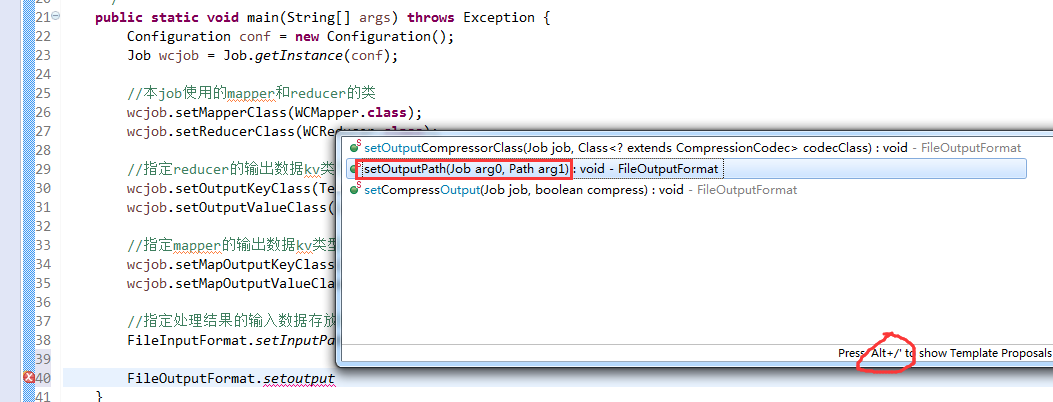
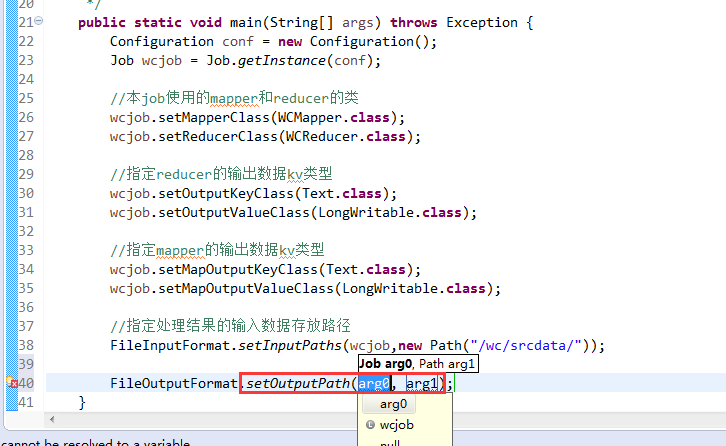
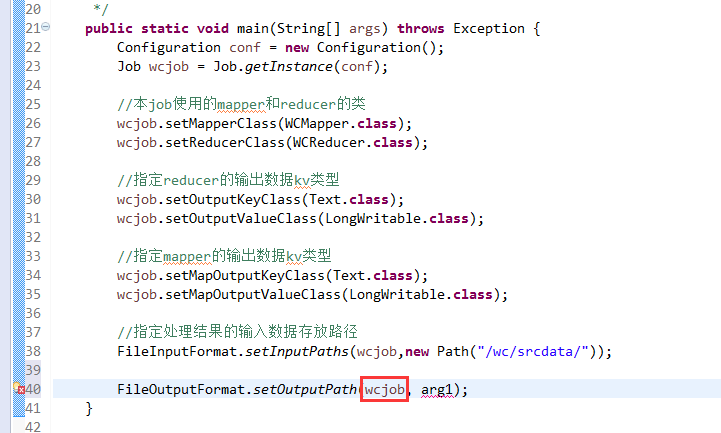
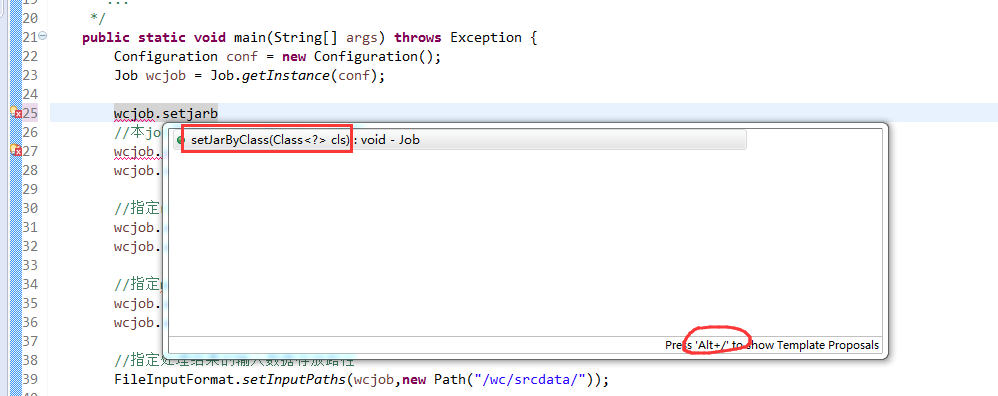
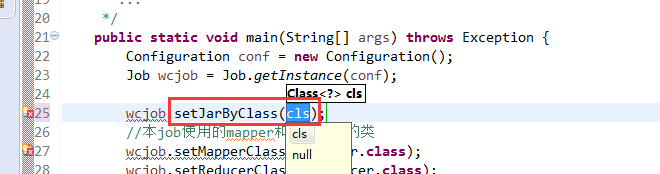
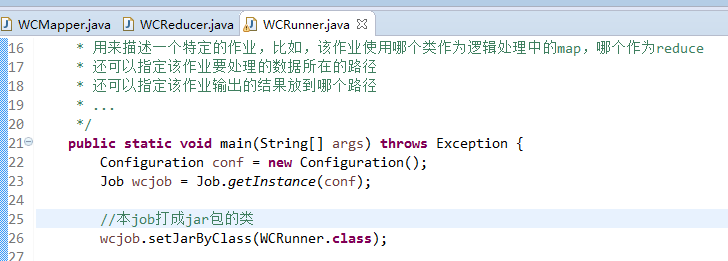
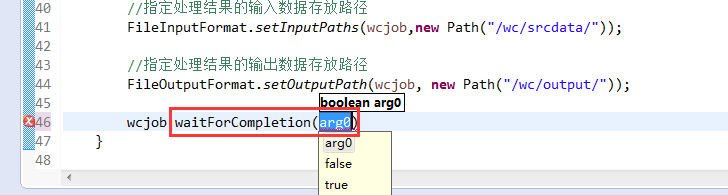
有这么多信息,可以封装到对象里,job对象,
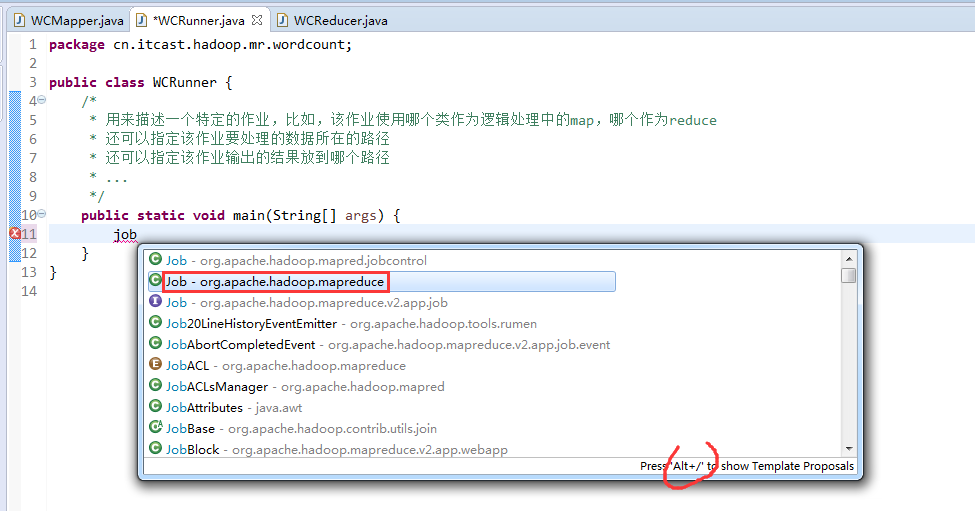
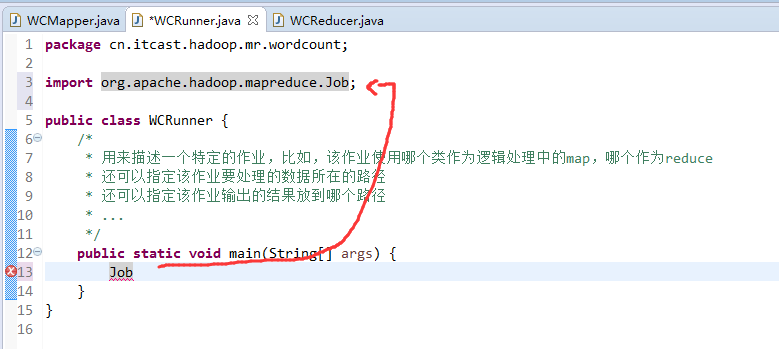
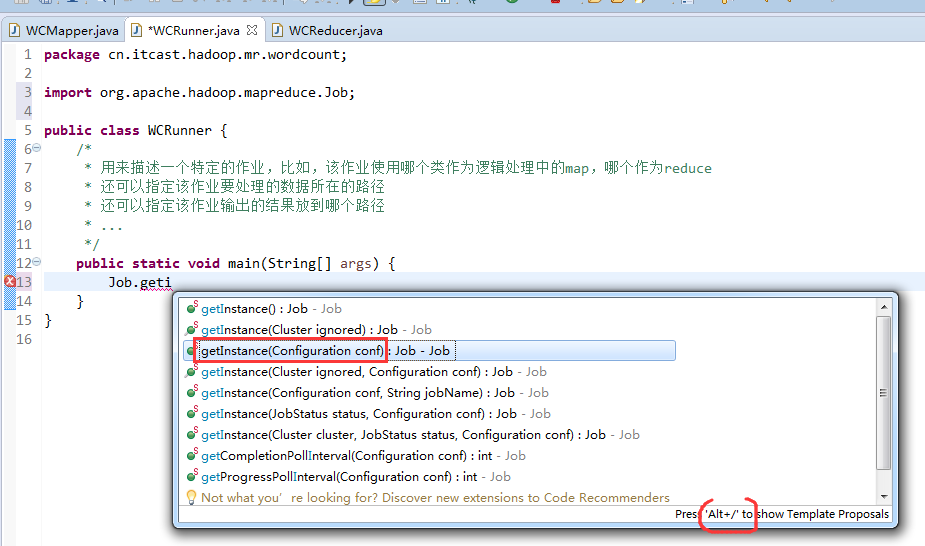
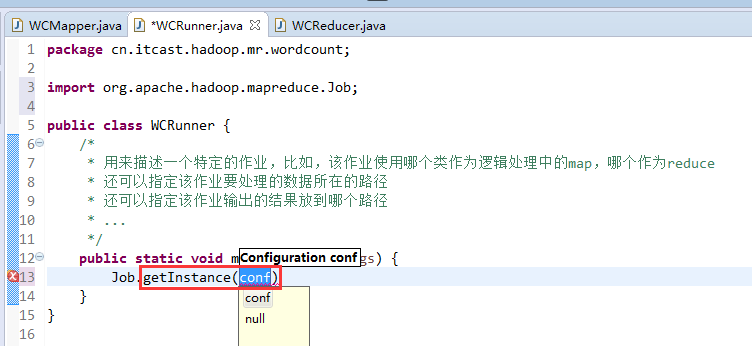
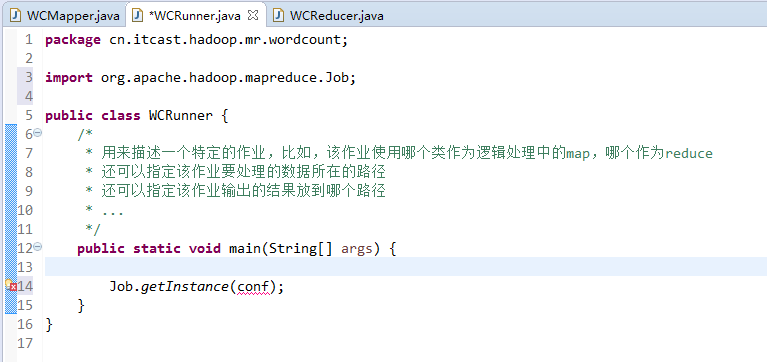
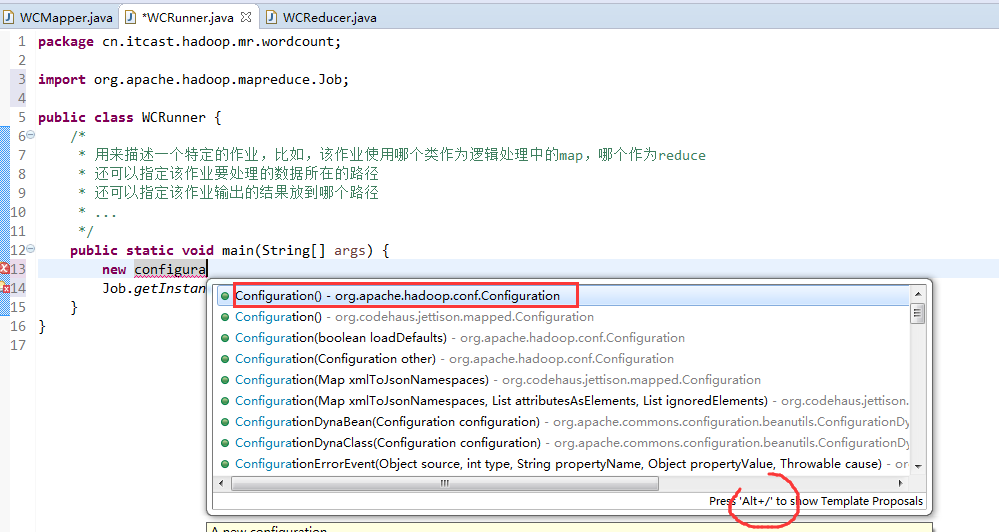
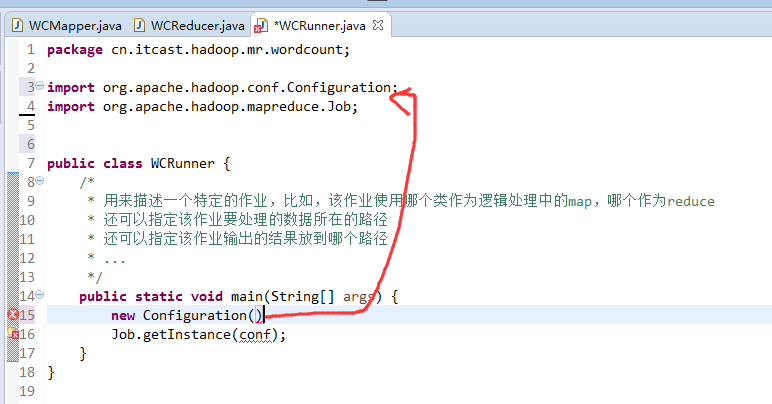
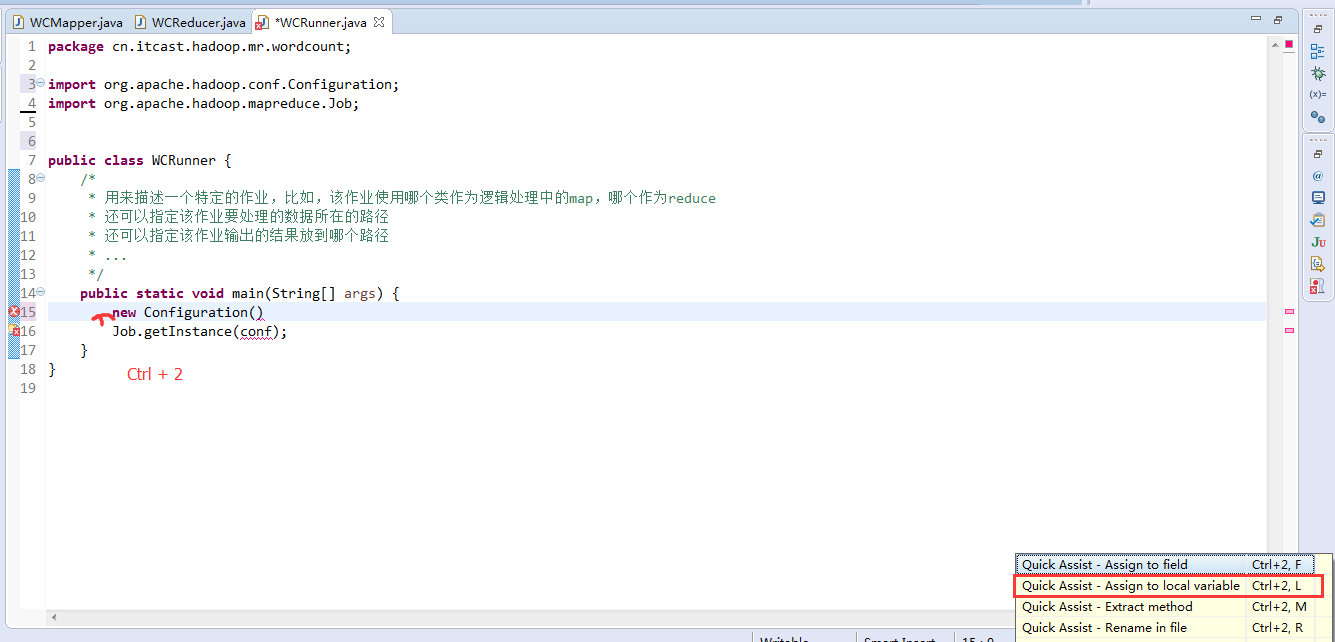
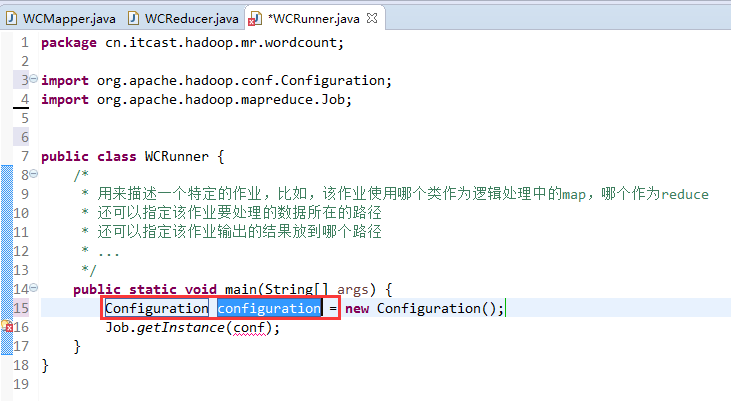
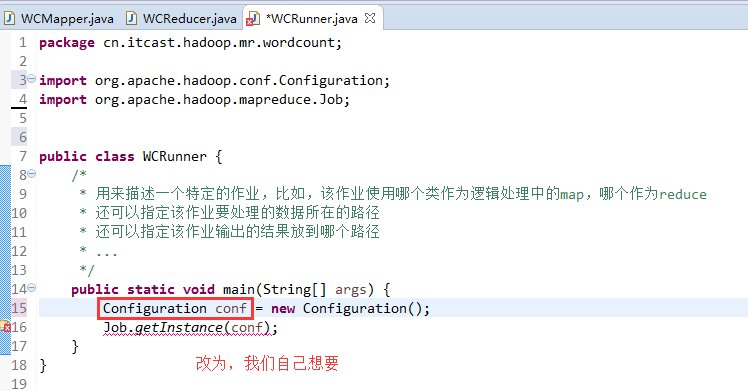
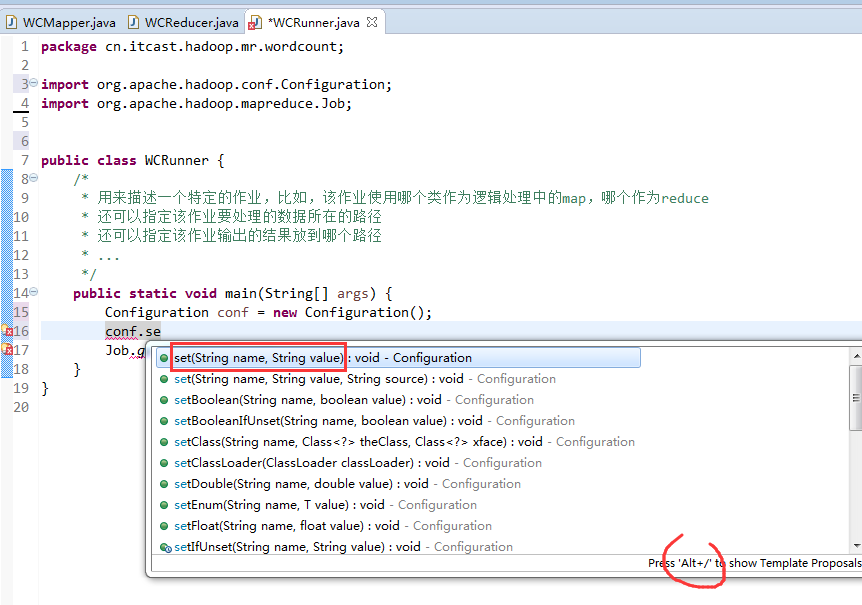
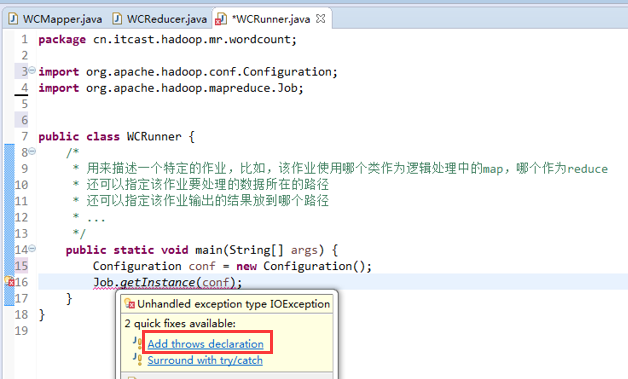
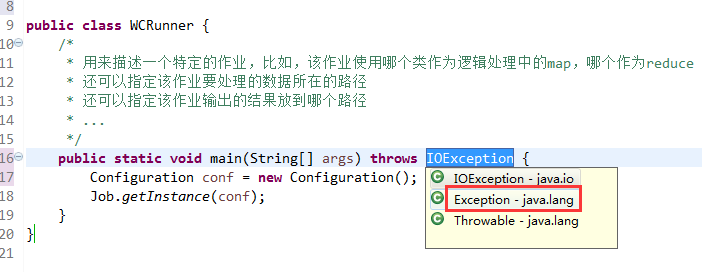

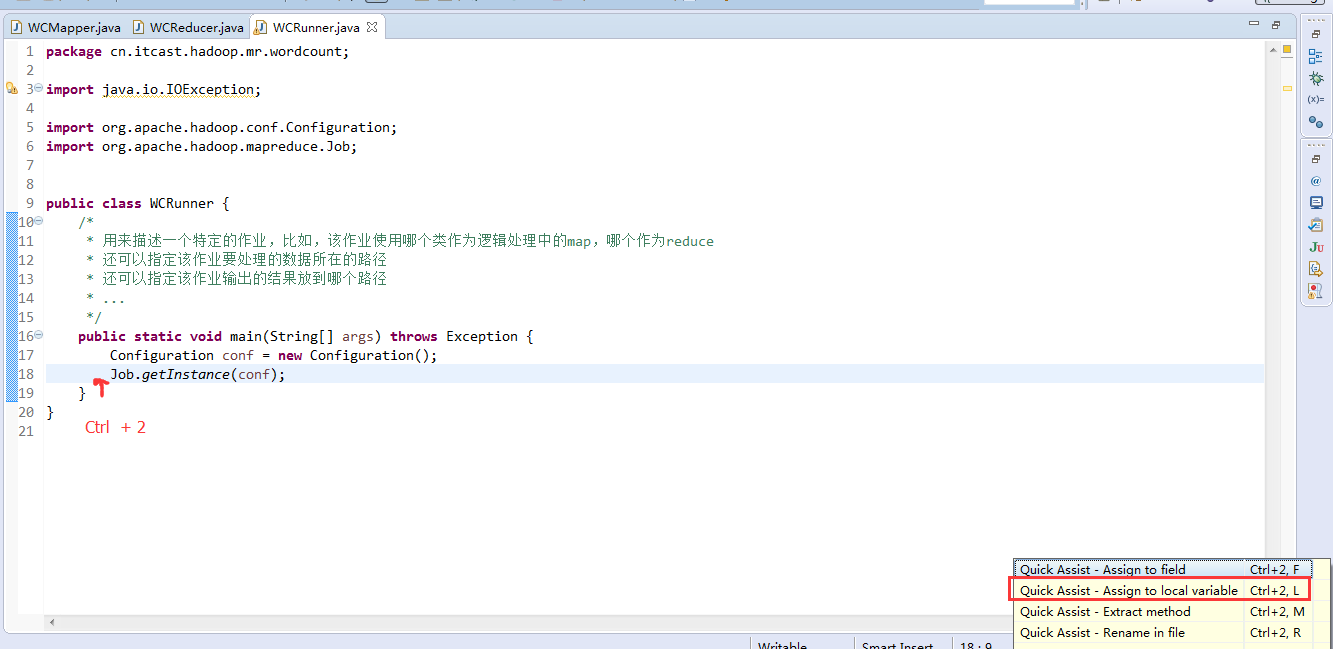
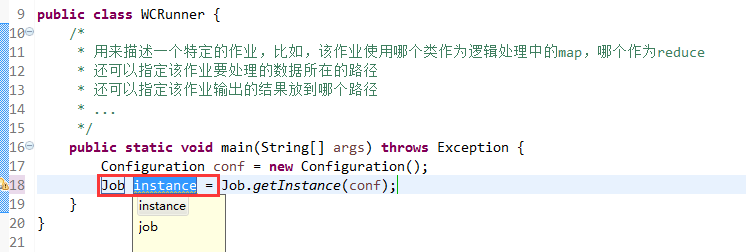
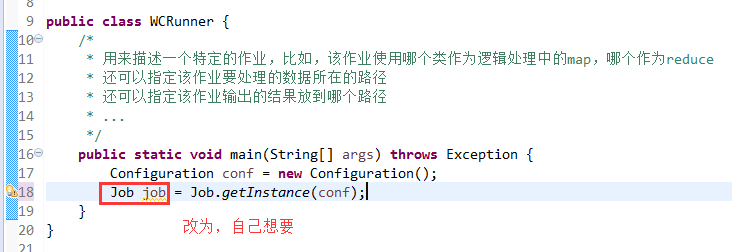
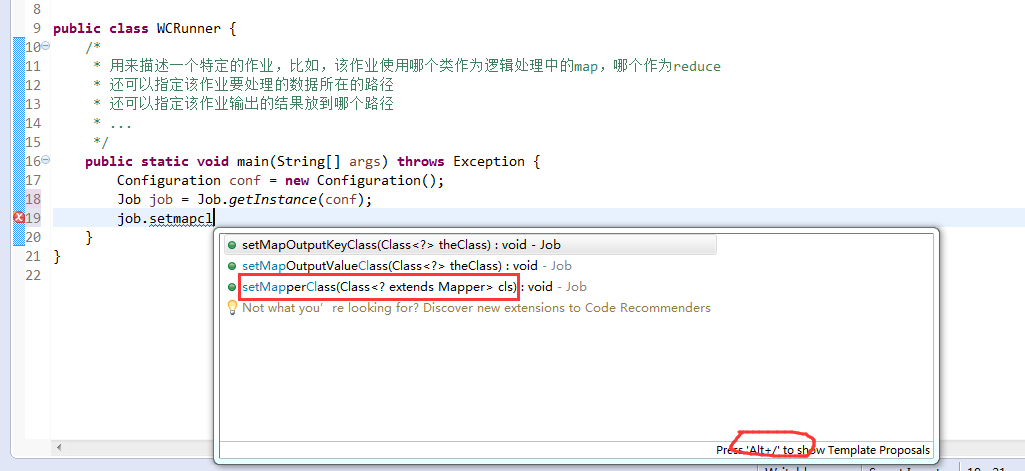

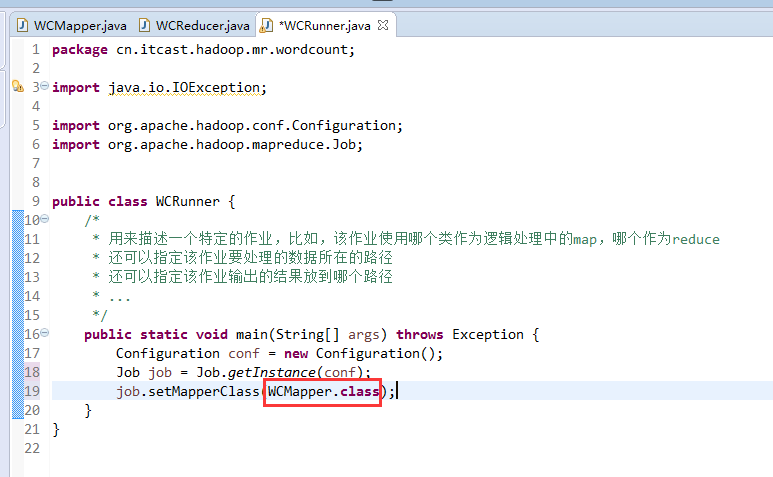
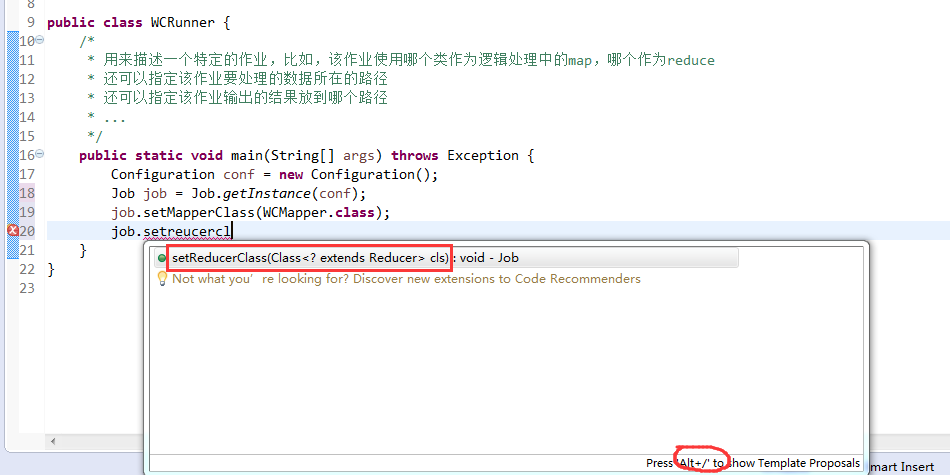
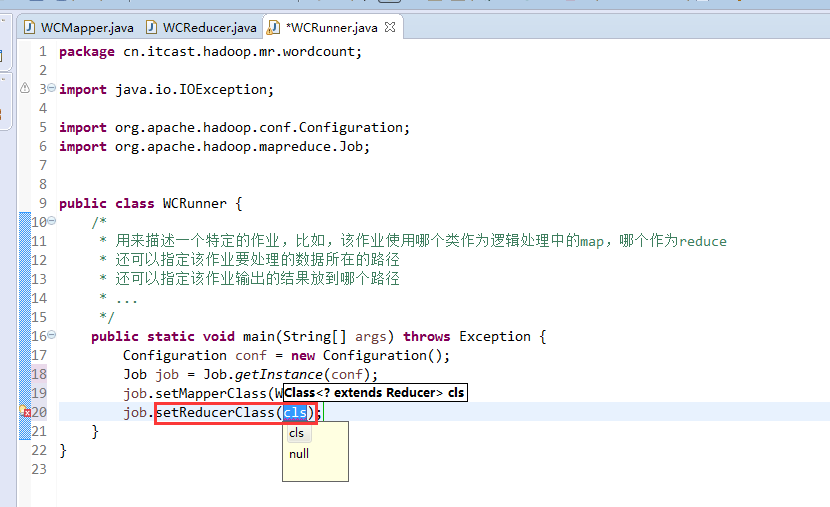
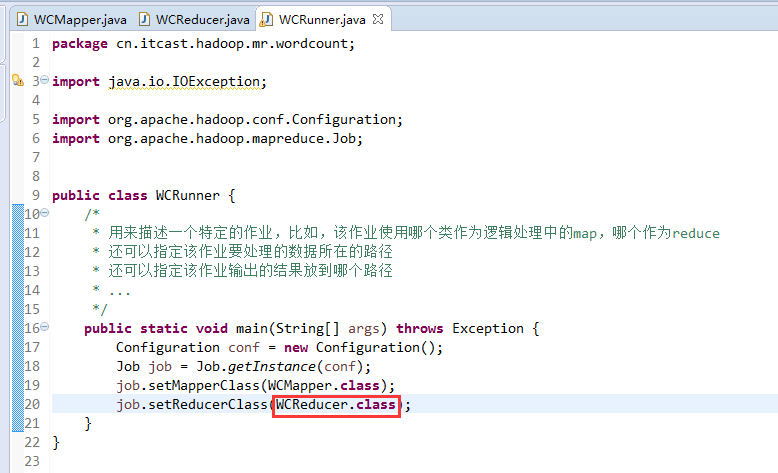
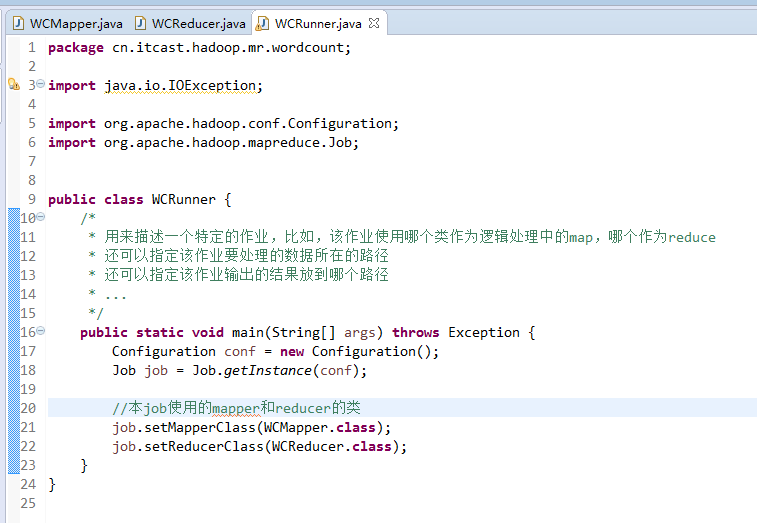
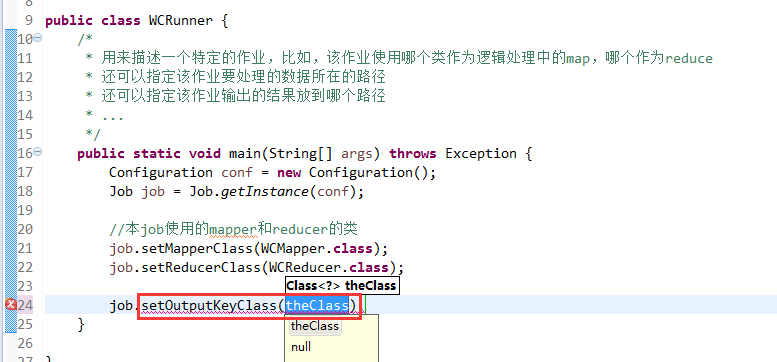
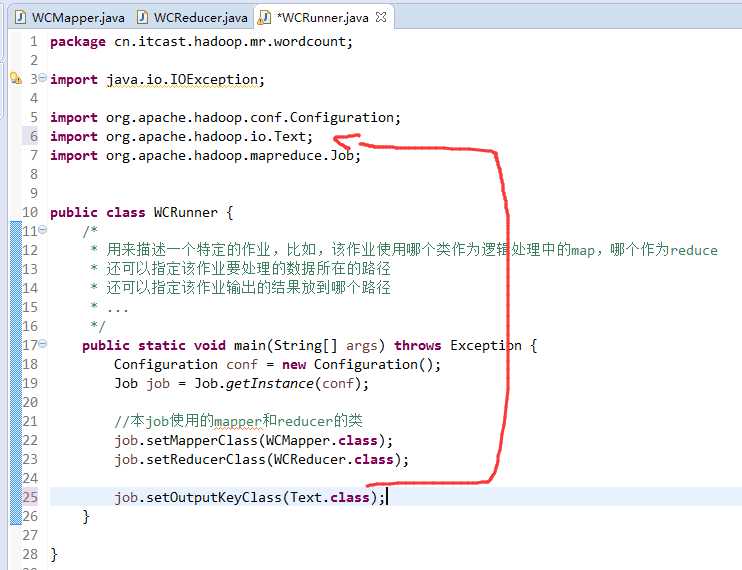


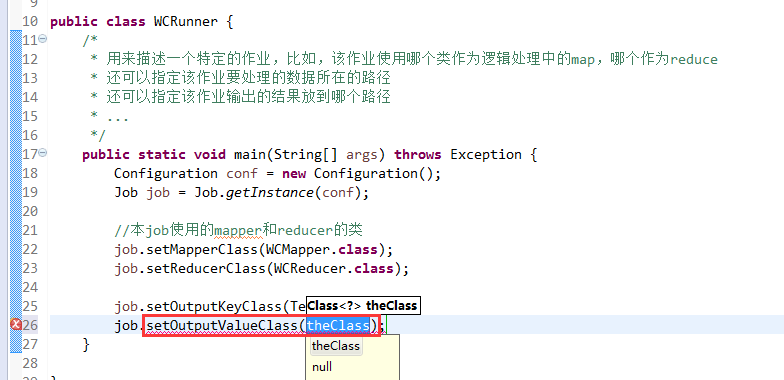
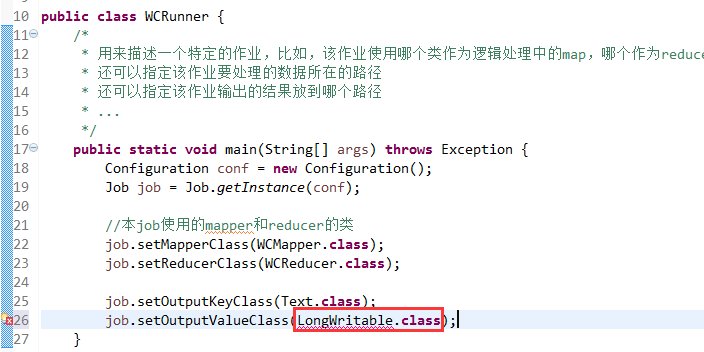
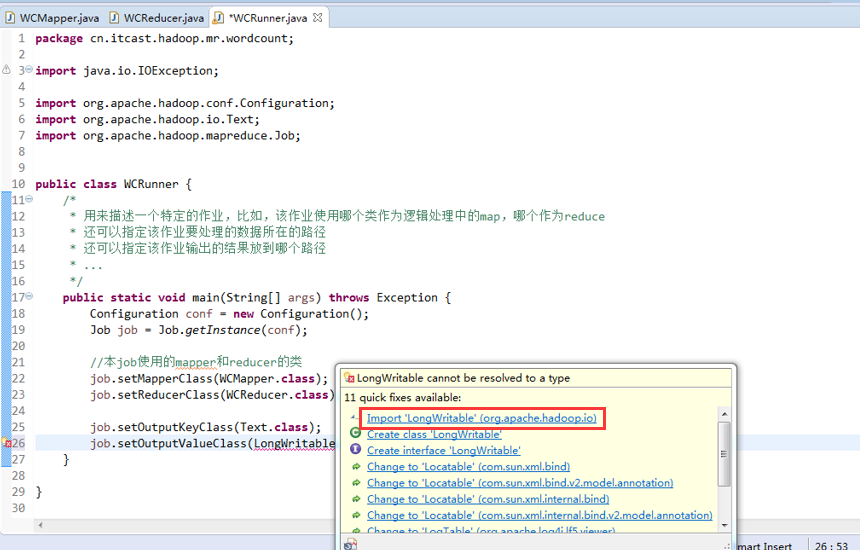
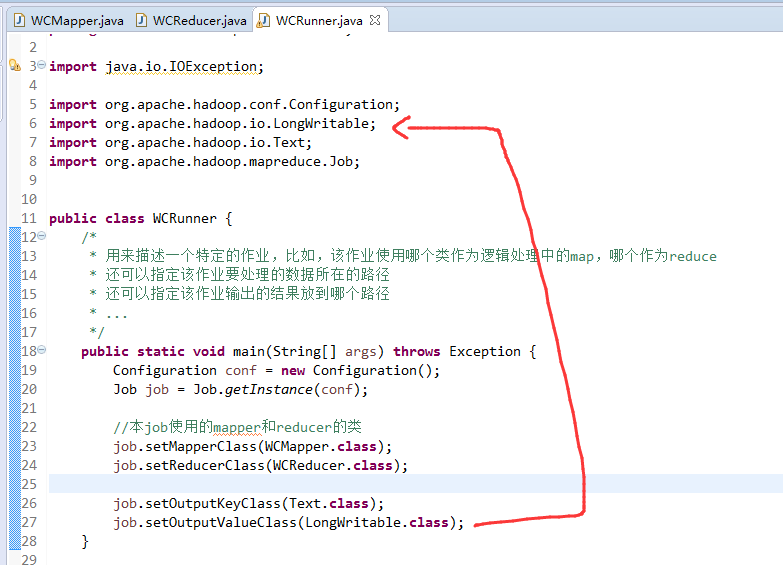
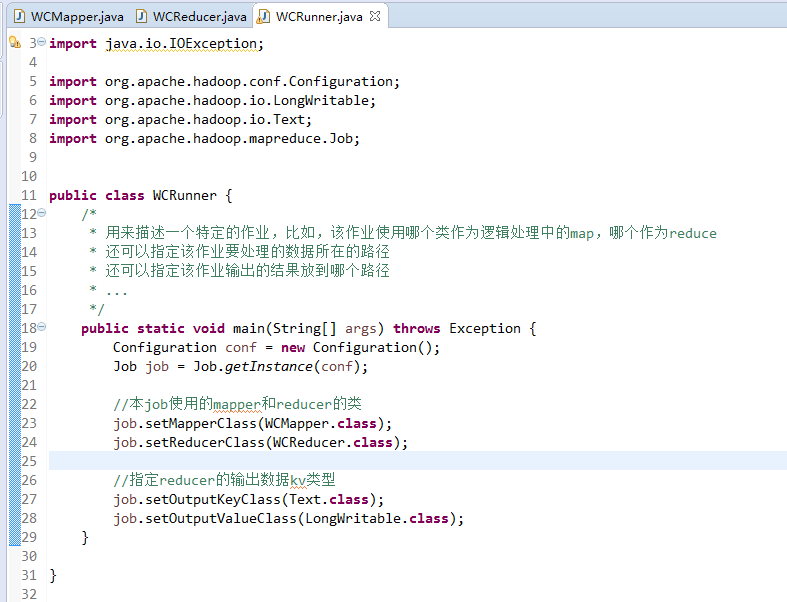
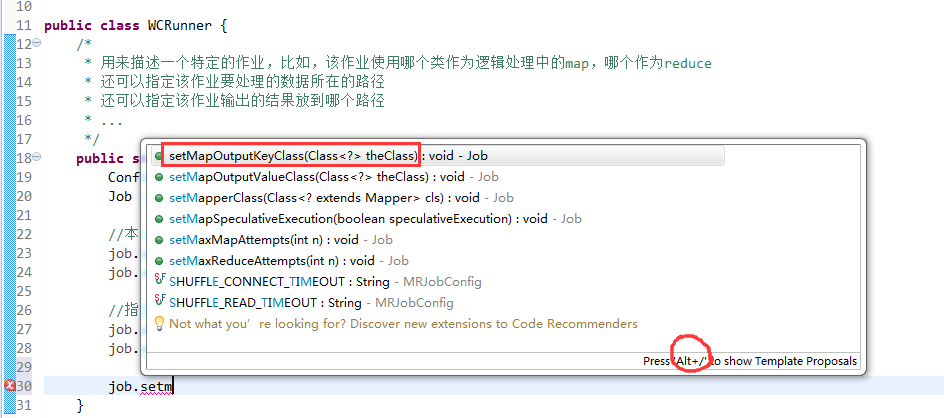
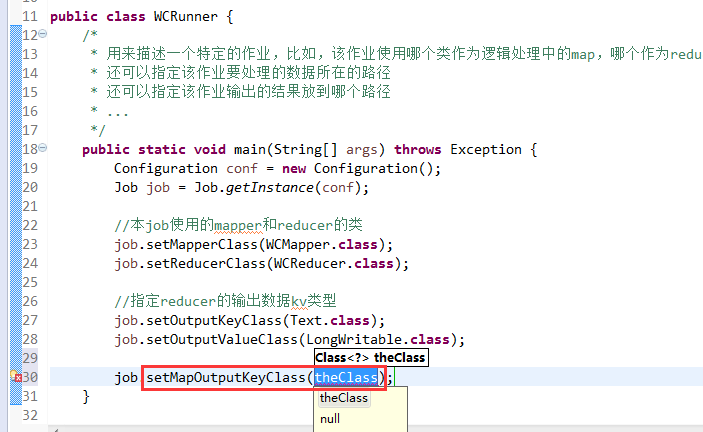


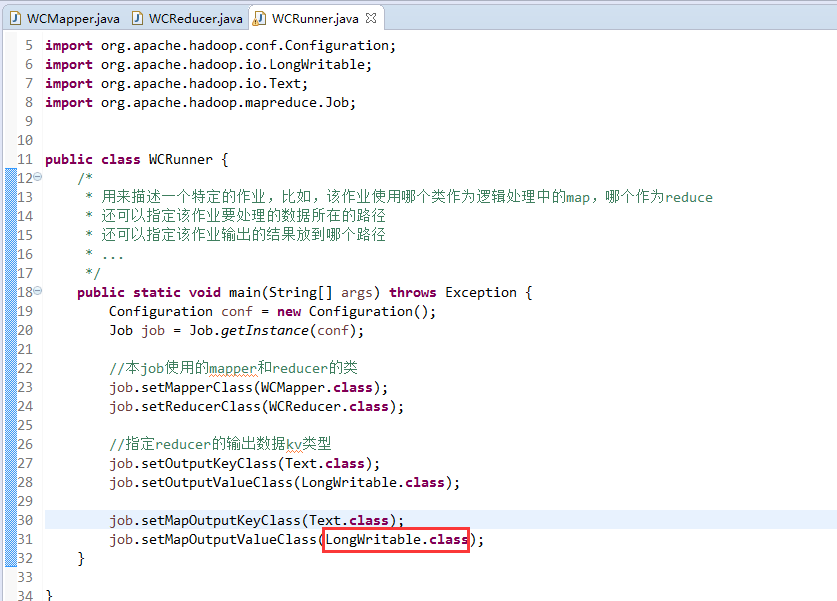

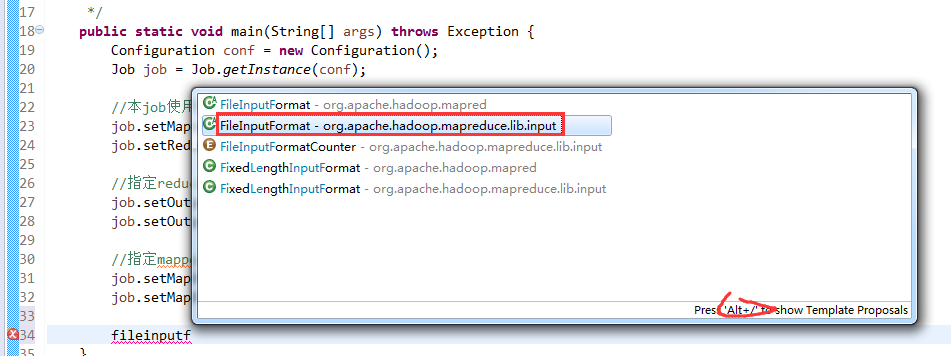
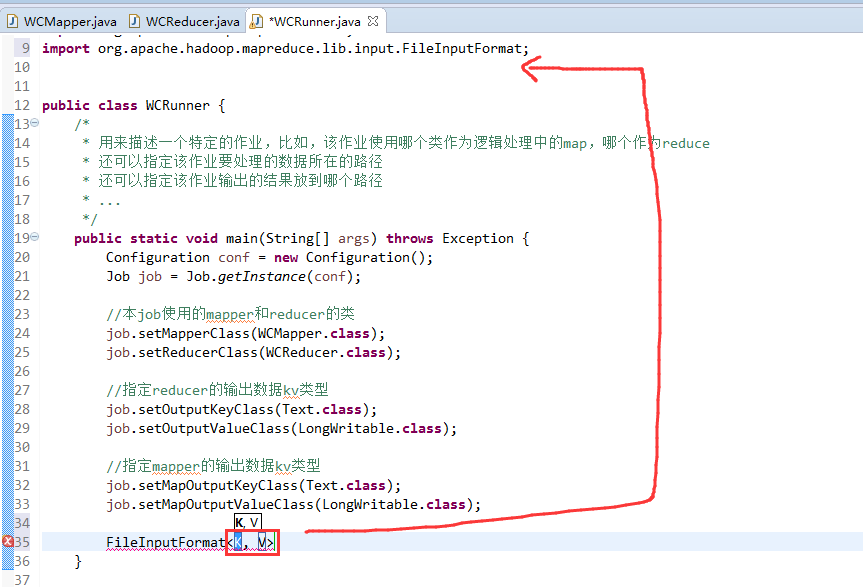
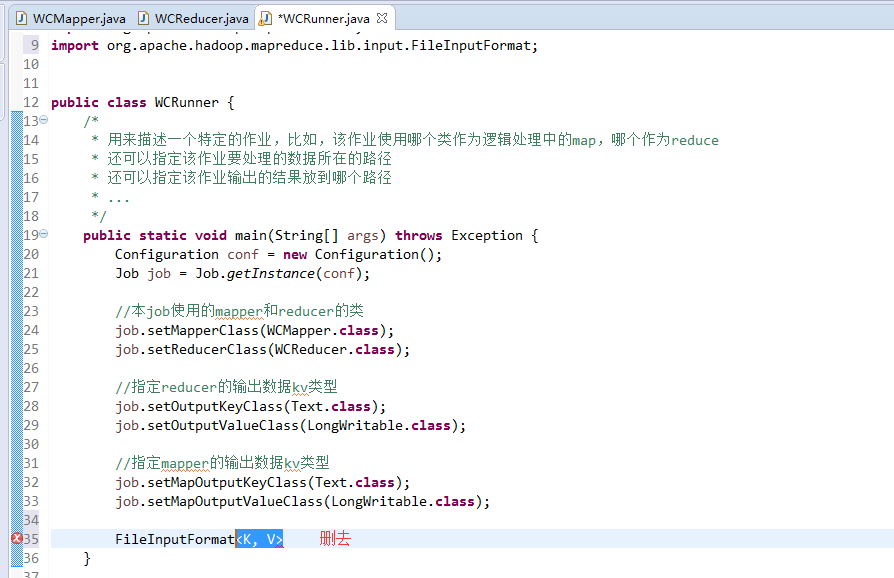
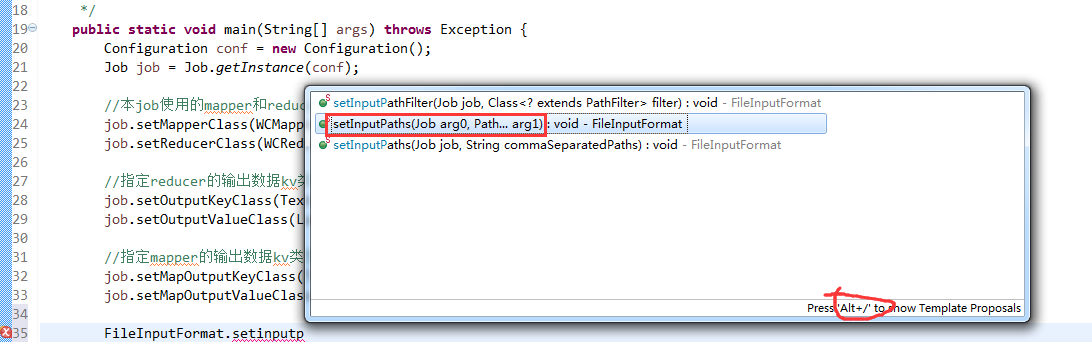
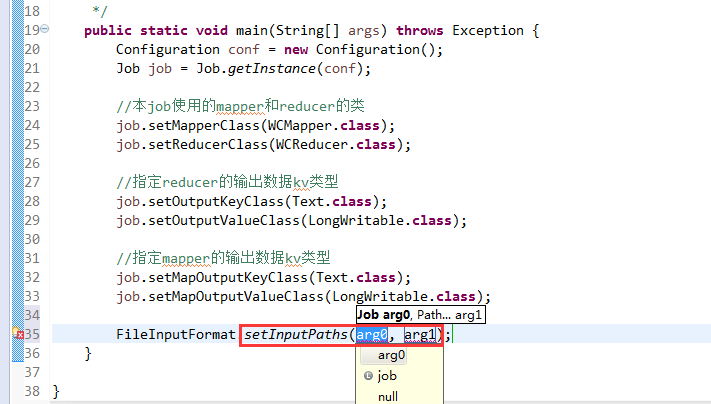
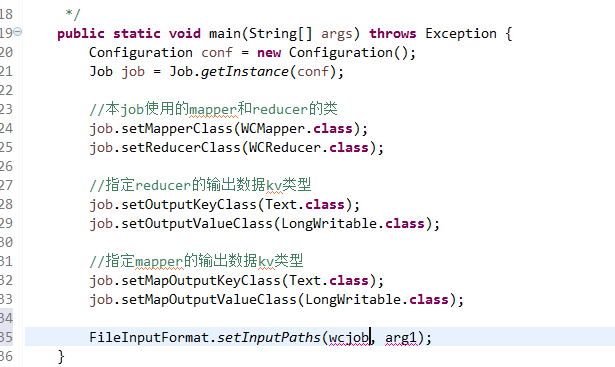
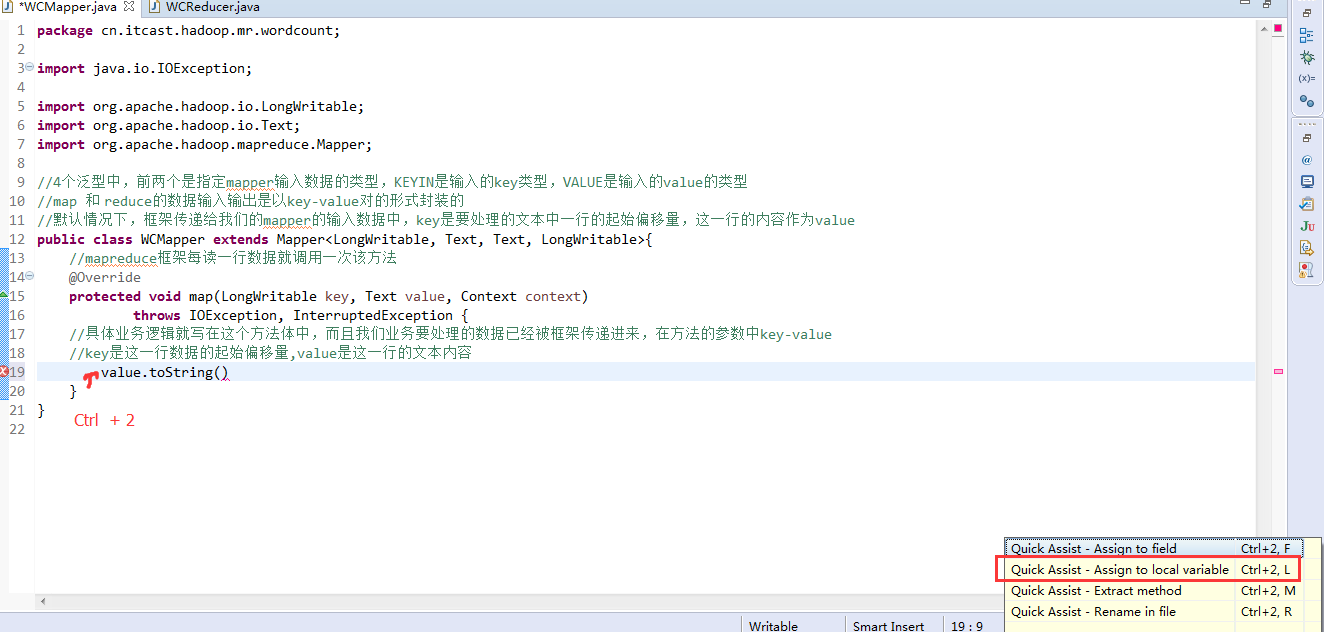
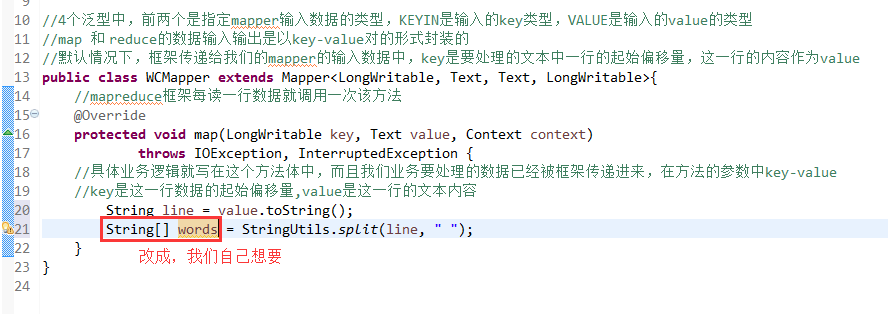
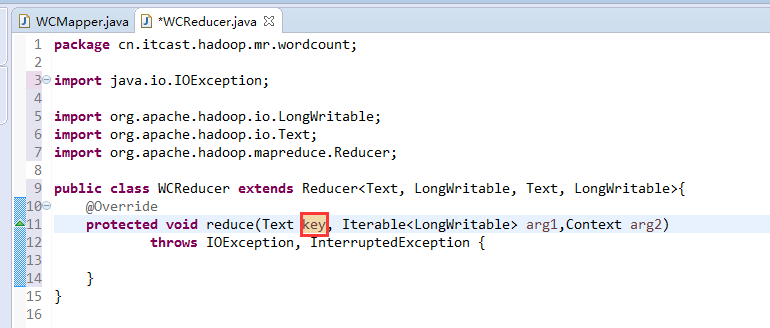
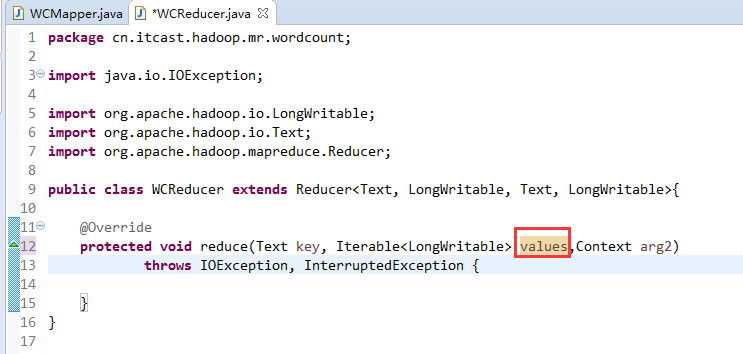
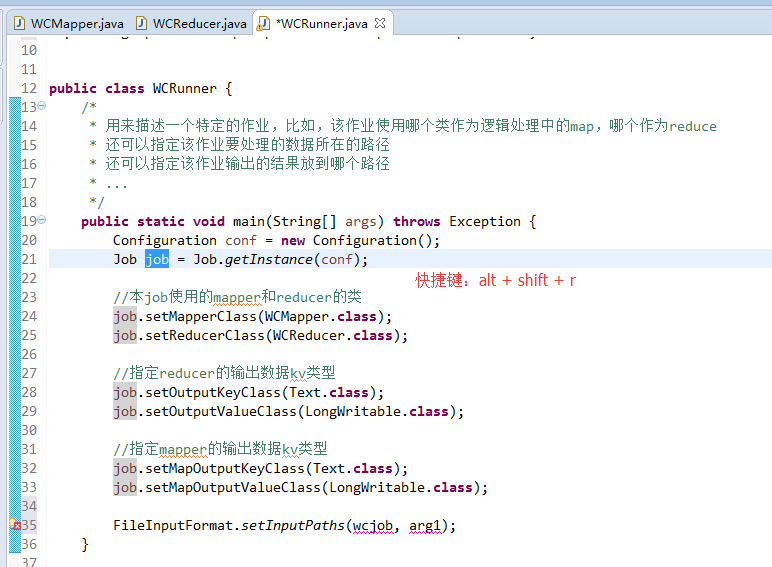
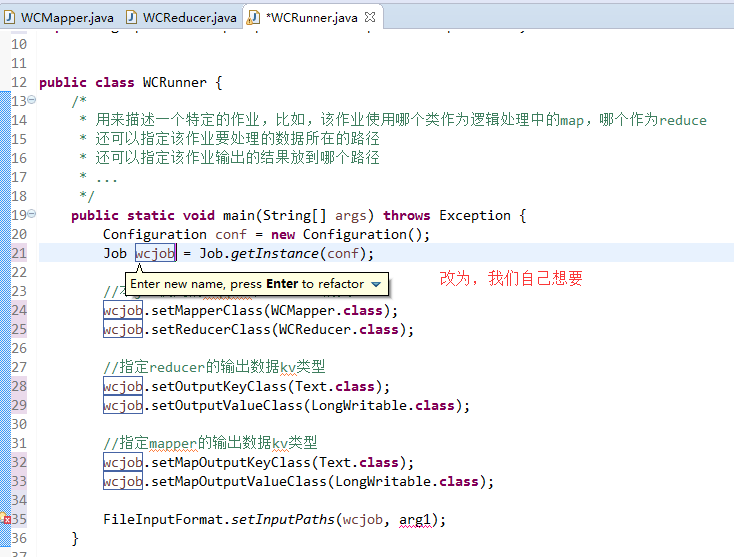
如何批量换变量名快捷键是,alt + shift + r




/home/hadoop/app/hadoop-2.4.1/bin/hadoop fs -mkdir -r /wc/srcdata
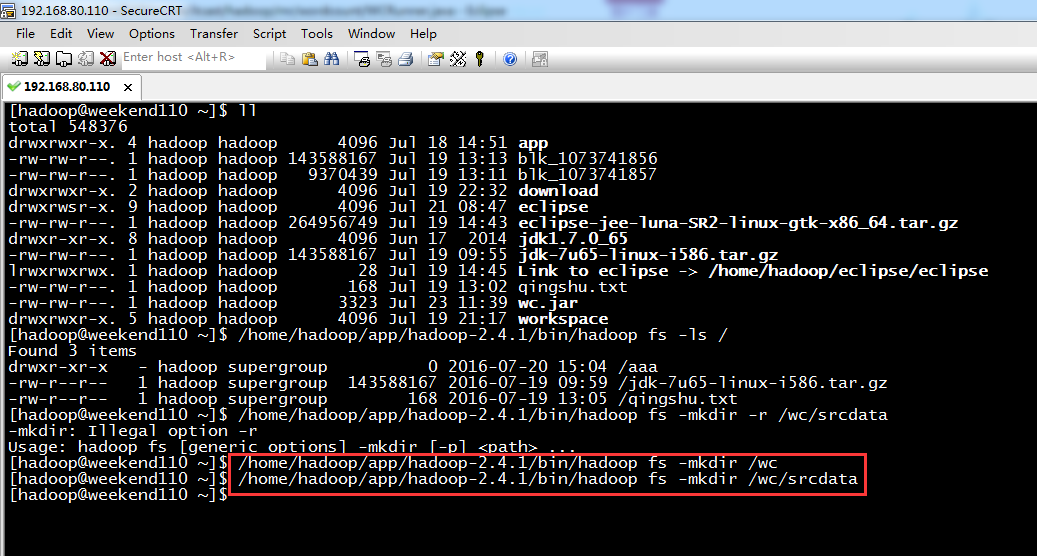






/home/hadoop/app/hadoop-2.4.1/bin/hadoop
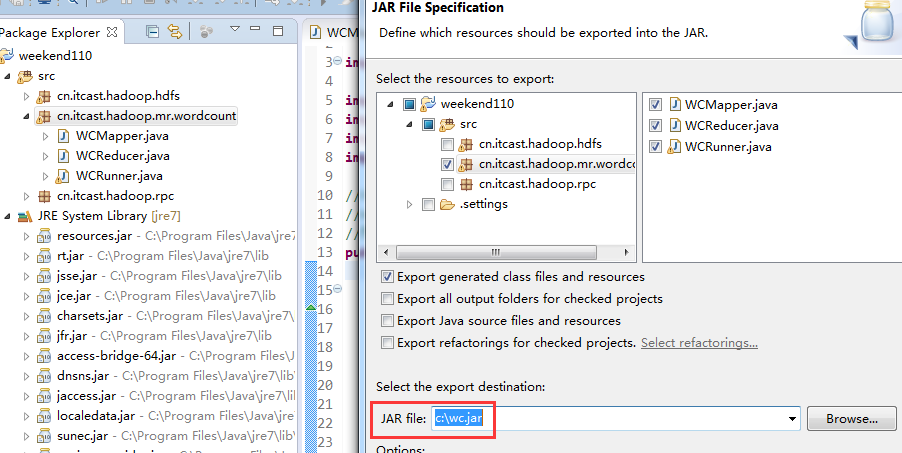
jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner /wc/srcdata/ /wc/output/
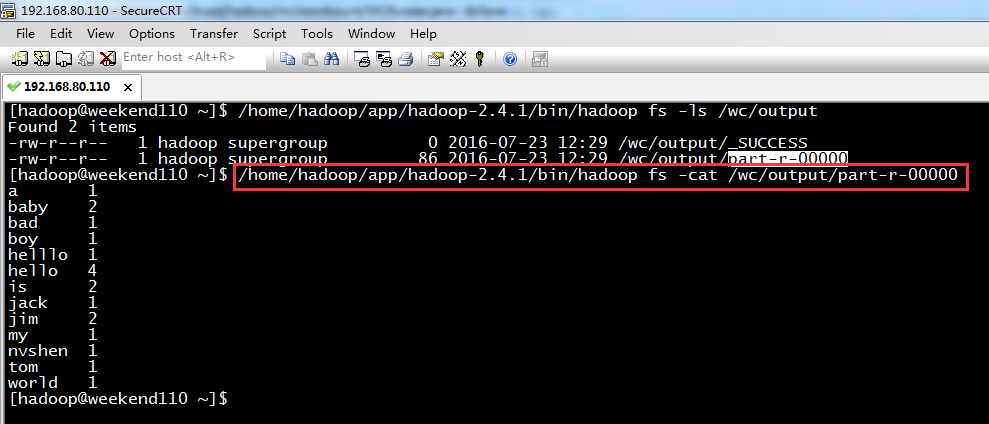
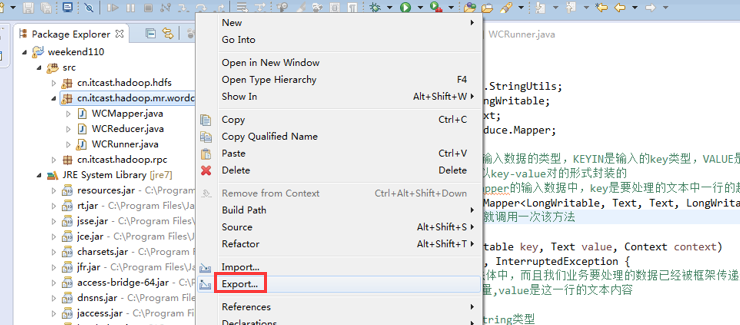
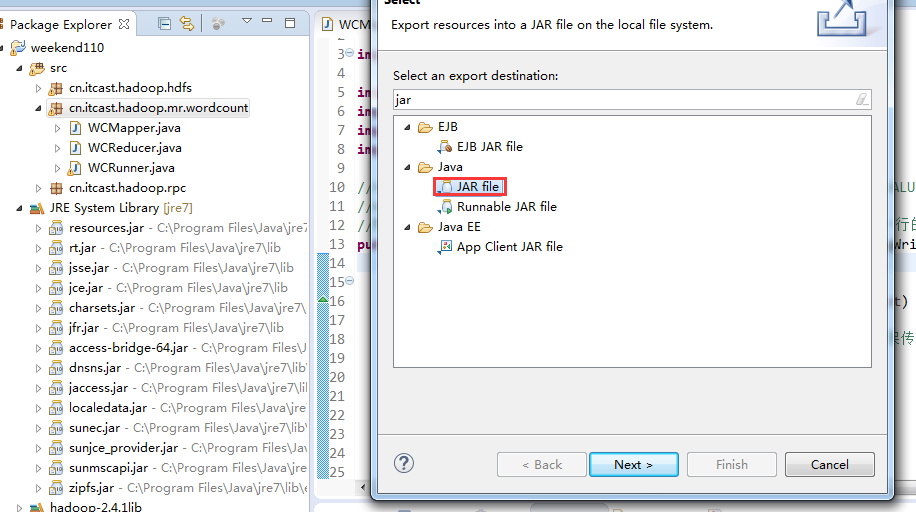
以上是weekend110的wordcount的编写和提交集群运行。
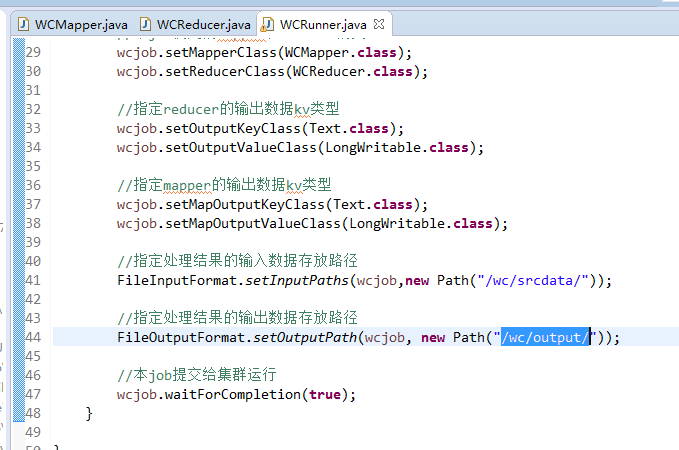
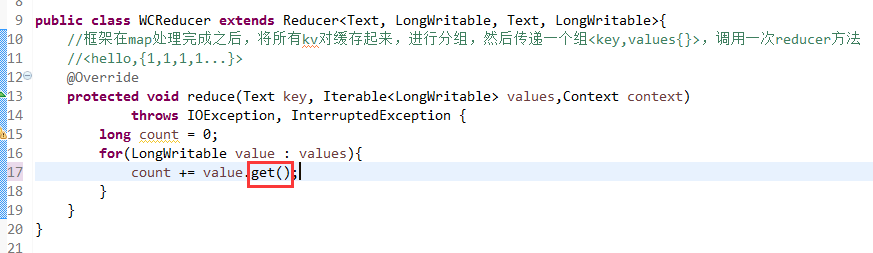
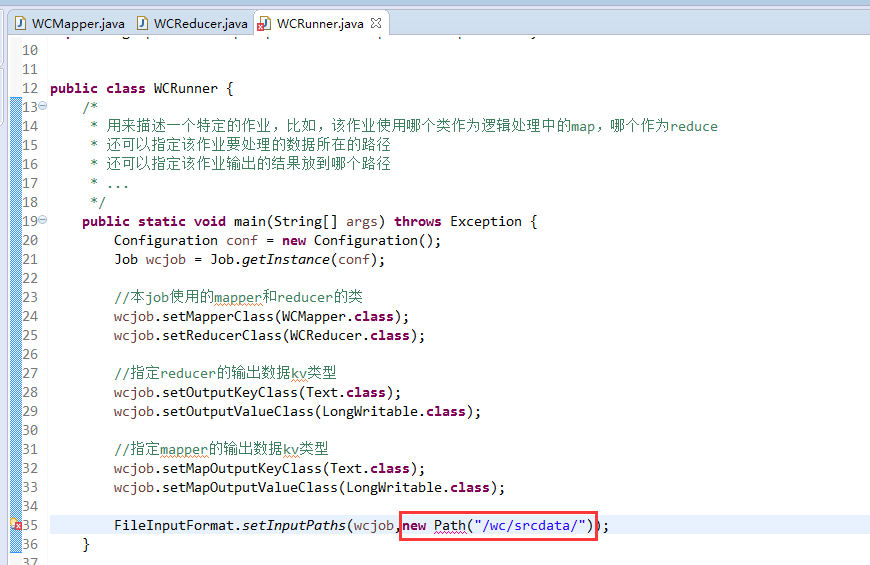
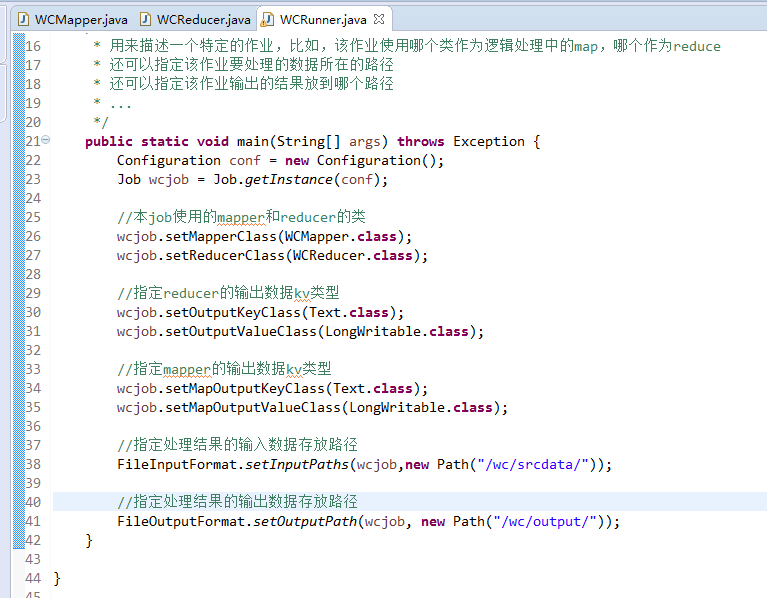
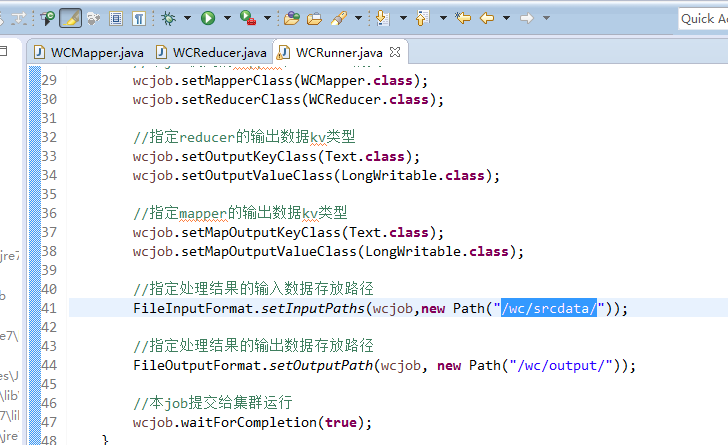
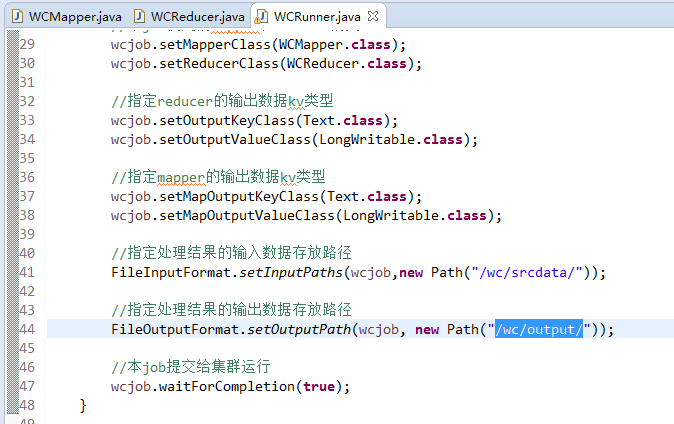
要注意的是,路径。
/wc/srcdata/,其实也就是hdfs://weekend110:9000/wc/srcdata/
下面,weekend110的mr程序的本地运行模式,
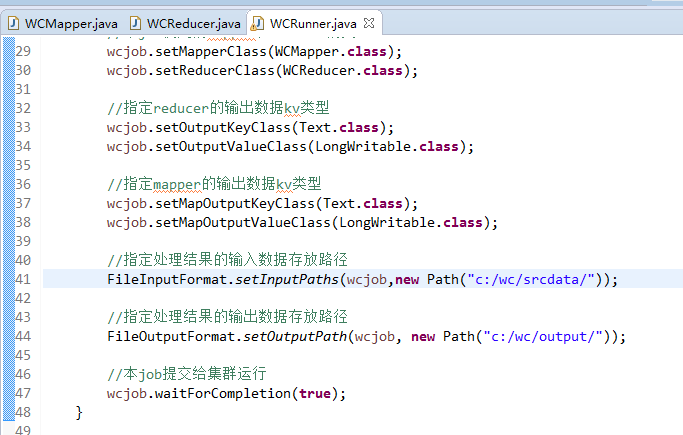
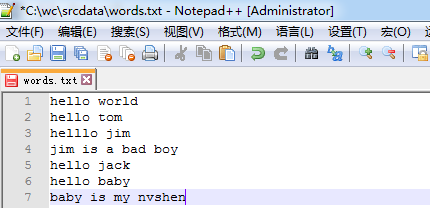


出现错误,
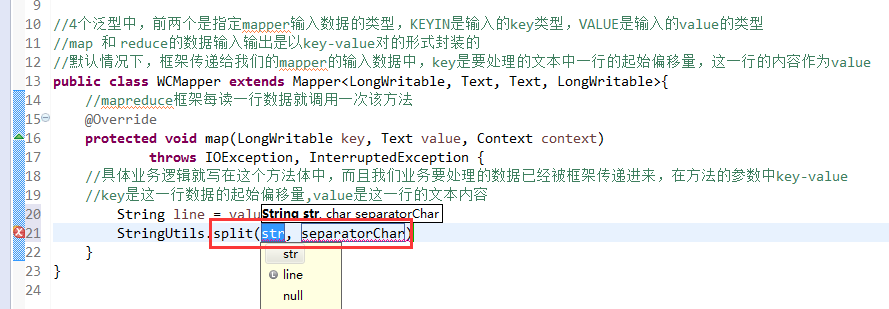
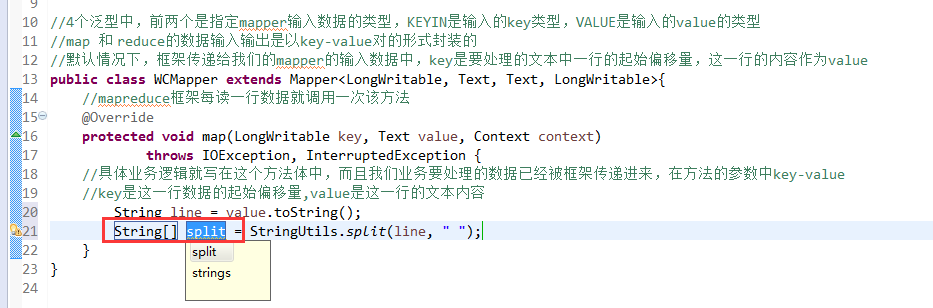
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
http://www.linuxidc.com/Linux/2014-12/111065.htm
参考13,运行报错(11):
缺乏hadoop.dll,下载hadoop.dll放到hadoop/bin目录下即可,
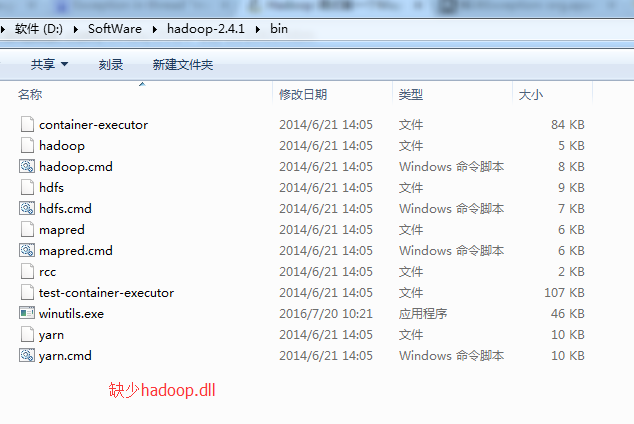
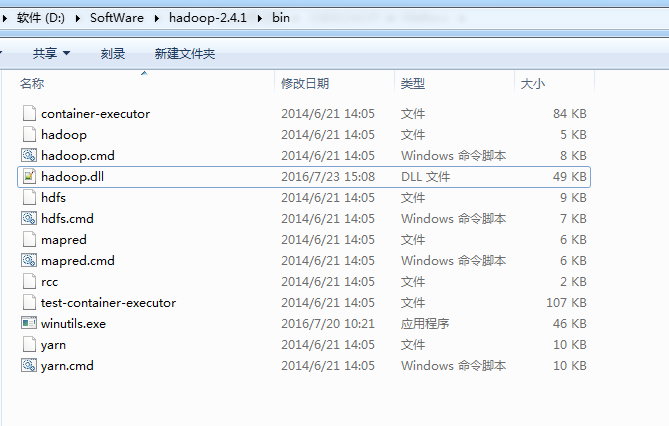
但是之后运行依然报错,还需要手动设置下hadoop在windows下的运行路径,
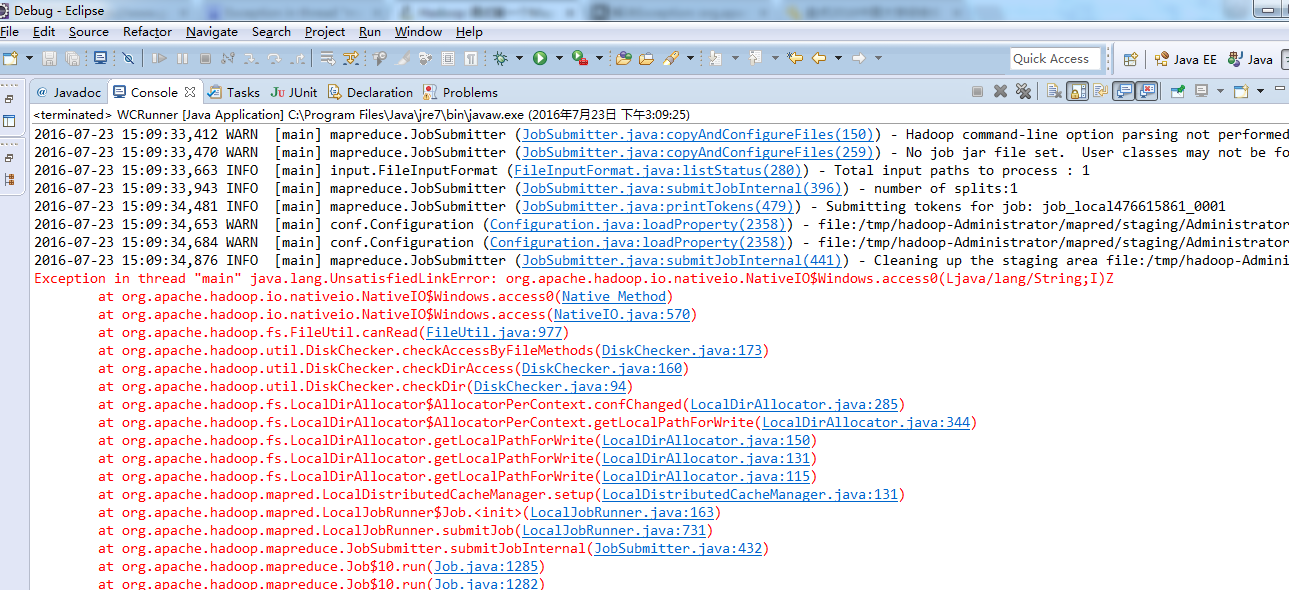
于是在Eclipse运行环境中,在运行的WordCount.java中,右键点击在下拉菜单栏里面选择Run Configurations,然后加上path的设置,Run顺利通过。参数如下图所示:
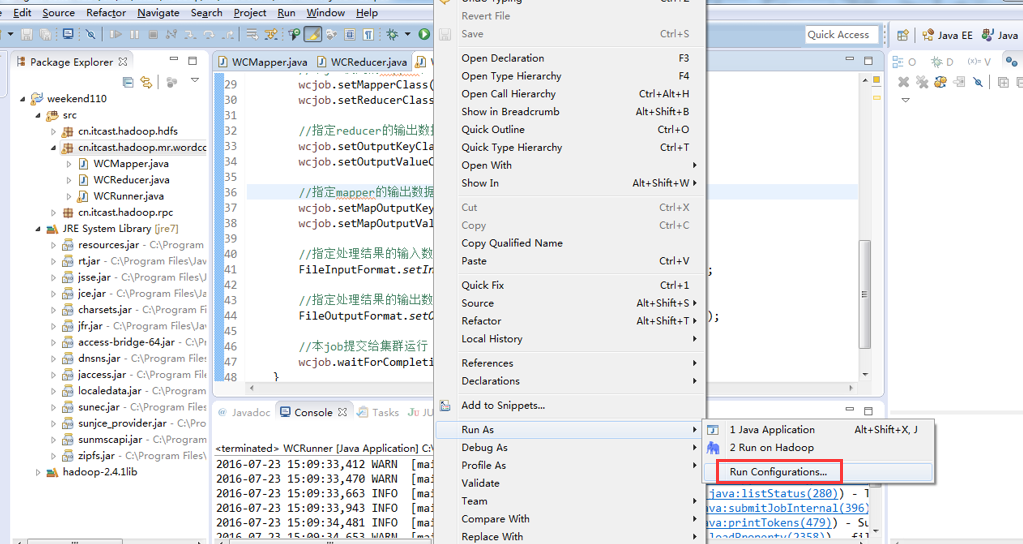
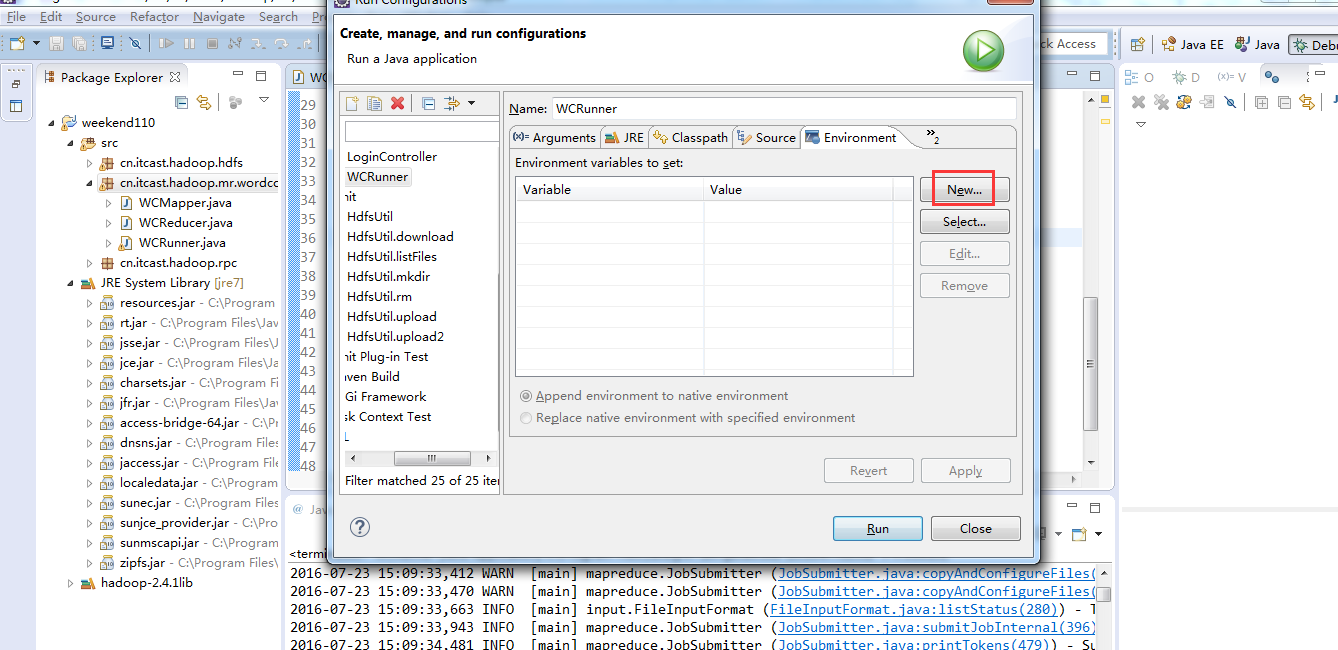
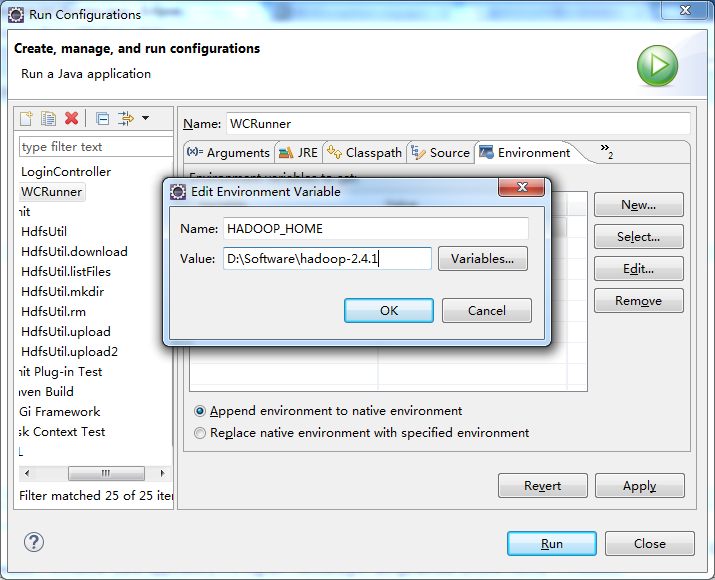

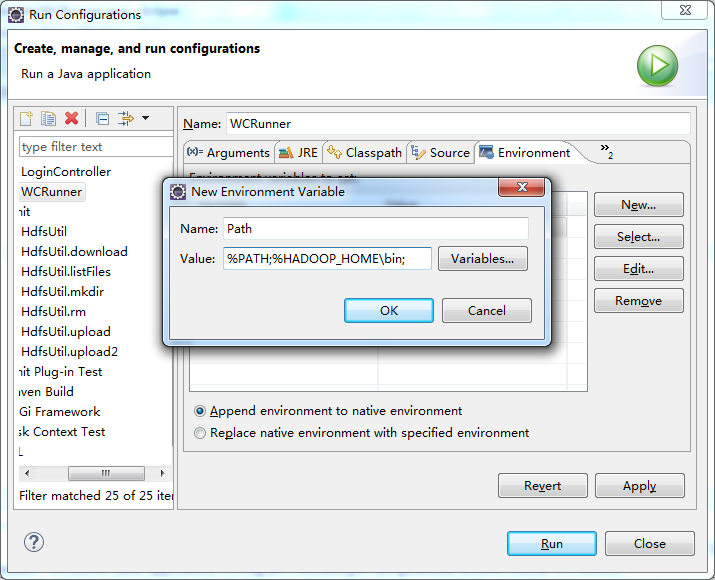
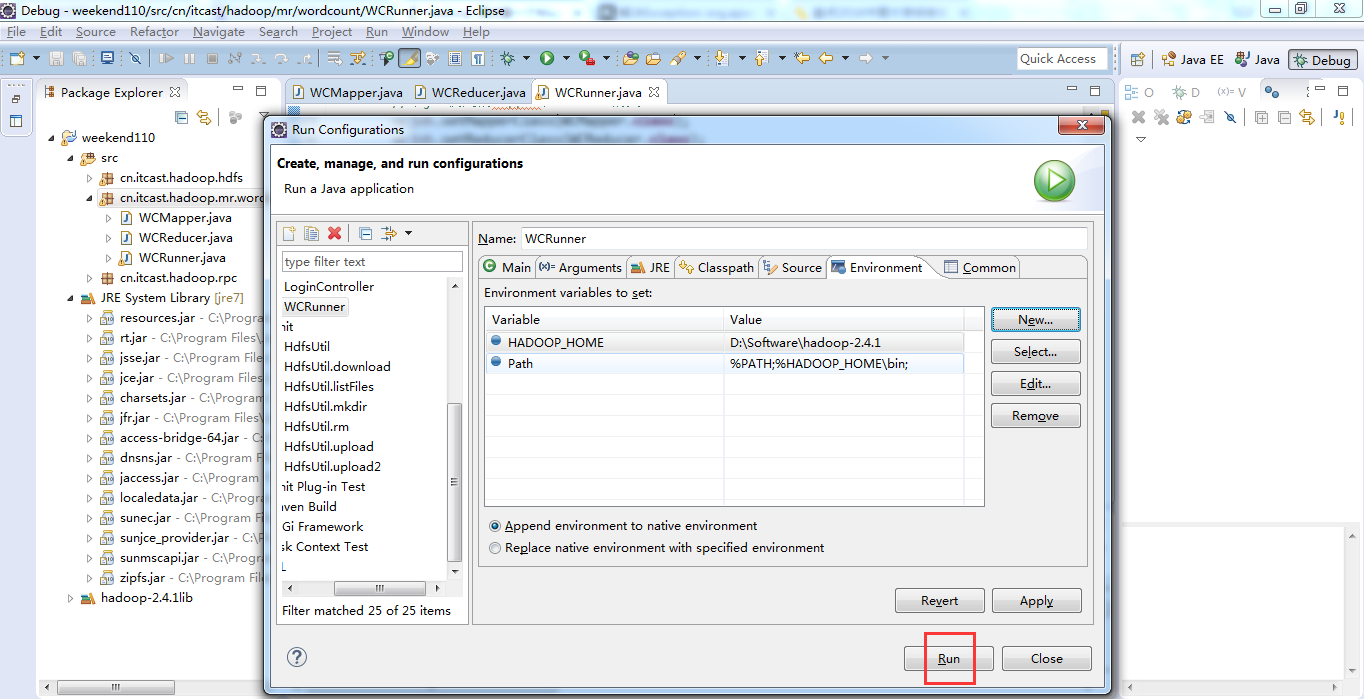
http://www.aboutyun.com/thread-8311-1-1.html

最后,还是报这个错误。
http://blog.csdn.net/congcong68/article/details/42043093
C:WindowsSystem32下缺少hadoop.dll,把这个文件拷贝到C:WindowsSystem32下面即可。
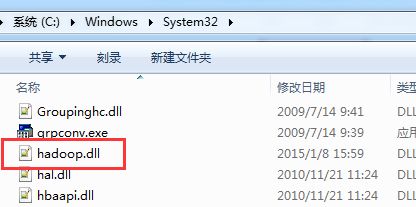
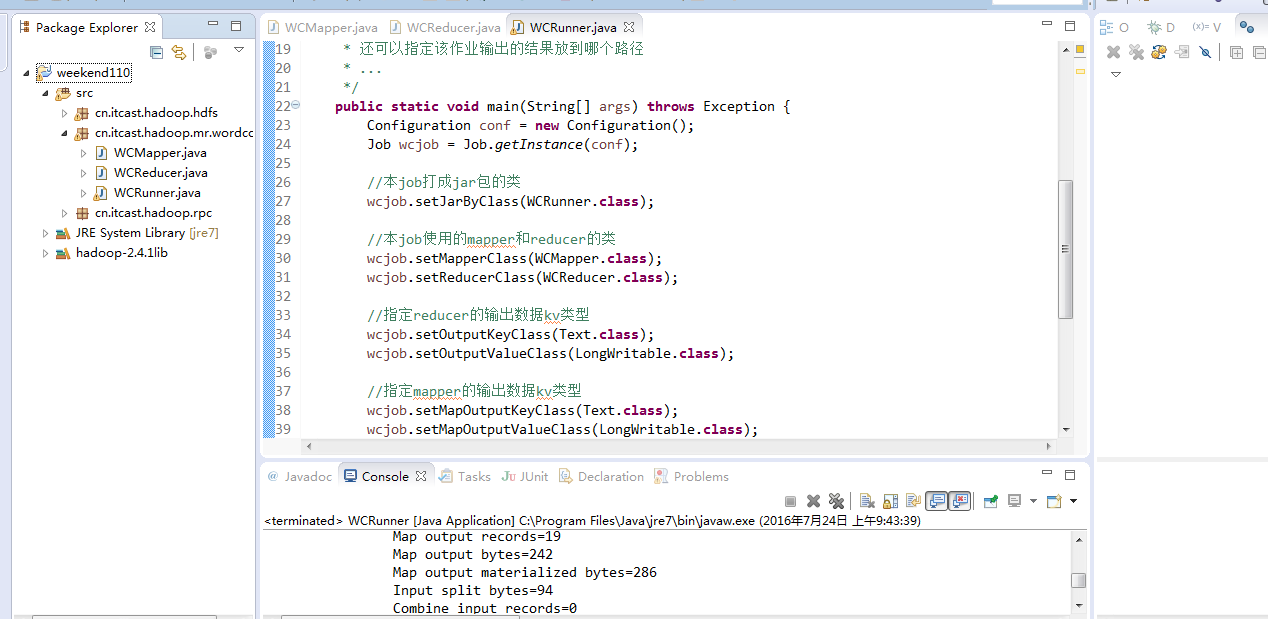
即,经过这折腾,问题得到了解决。


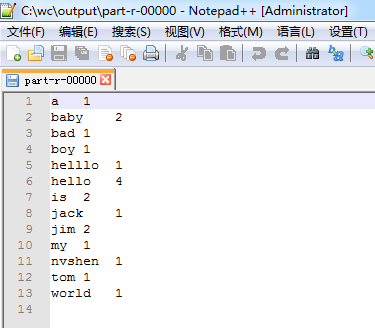
以上是mr程序的本地运行模式,需要注意地方是,
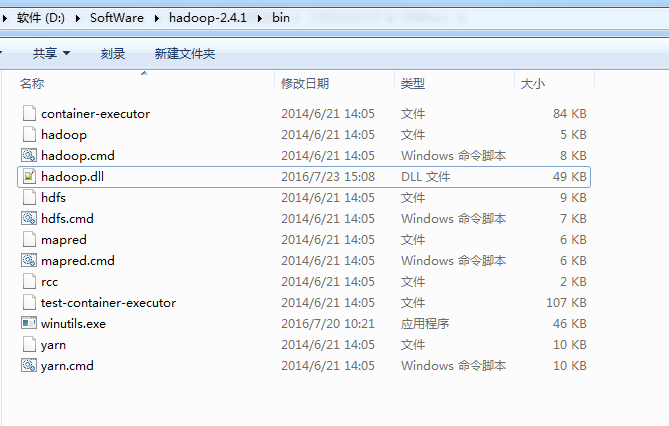
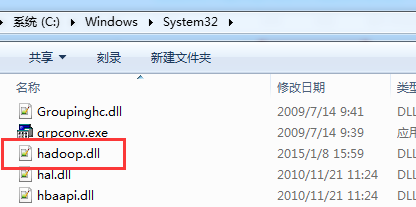
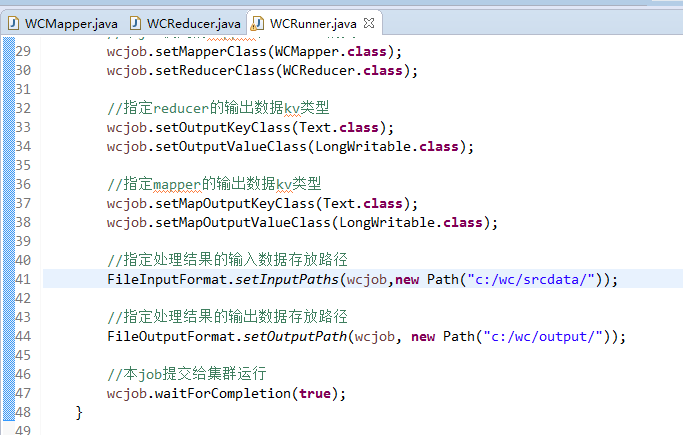
总共就这3个地方。
以上是weekend110的mr程度的本地运行模式