JAVA 是解释程序 解释程序是将源程序的一条语句翻译成对应于机器语言的一条语句 并且立即执行这条语句 接着翻译原程序的下一条语句 并执行这条语句 重复直到完成原程序的全部翻译任务
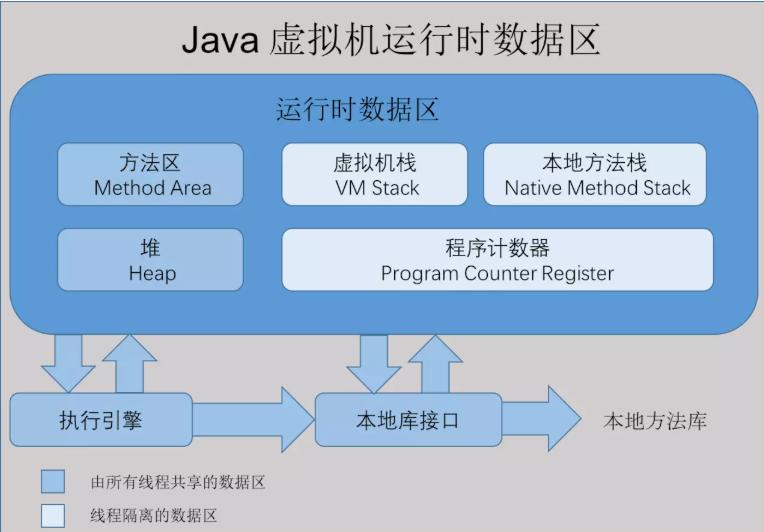
程序计数器
字节码解释器工作是就是通过改变这个计数器的值来选取下一条需要执行指令的字节码指令 分支 循环 跳转 异常处理 线程恢复等基础功能都需要依赖计数器完成
JAVA 虚拟机栈(描述的是 JAVA 方法执行的内存模型)
每个方法在执行时会创建一个栈帧 Stack Frame 存储局部变量表 操作数栈 动态链接 方法出口等信息 每一个方法从调用到执行结束,就对应着一个栈帧从虚拟机栈中从入栈到出栈的过程
局部变量表:包括基本引用类型 returnAddress 类型以及对象引用类型
本地方法栈
为 Native 方法服务
JAVA 堆
主要存放对象实例和数组 内部会划分出多个线程私有的分配缓冲区 (Thread Local Allocation Buffer, TLAB)。可以位于物理上不连续的空间 但是逻辑上要连续
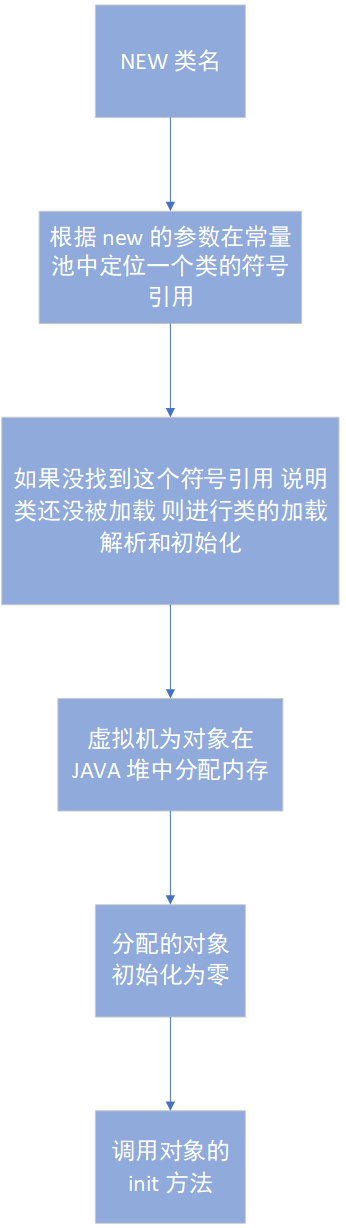
对象和实例: Animal animal = new Animal(); new 的时候在 JAVA 堆中新建了一个对象 这个对象是 Animal 的实例 animal 是对该对象的引用 !万物皆是对象!
如果 JAVA 堆中没有内存完成实例分配 并且堆也没办法扩展的时候 抛出 OutOfMemoryError
方法区
属于共享内存区域 存储已被虚拟机加载的类信息 常量 静态变量 即时编译器编译后的代码等数据
运行时常量池
用于存放编译期生成的各种字面量和符号引用
直接内存
非虚拟机运行时数据区的部分
new 新对象的过程
HotSpot 虚拟机
HotSpot 虚拟机中分为三个区域:对象头 实例数据和对象填充
对象头(Mark Word 和类型指针)
Mark Word 用于存储对象自身的运行时数据 如 HashCode GC 分代年龄 锁状态标志 线程持有的锁 偏向线程 ID 偏向时间戳等等 占用内存大小与虚拟机位长一致
类型指针指向对象的类元数据 虚拟机通过这个指针确定该对象是哪个类的实例
HotSpot 通过 markOop 类型实现 Mark Word 具体实现位于 markOop.hpp 文件中 markOop 中不同的锁标识位 代表着不同的锁状态 不同的锁状态 存储着不同的数据 markOop 中提供了大量方法用于查看当前对象头的状态 以及更新对象头的数据 为 synchronized 锁的实现提供了基础
实例数据
程序代码中所定义的各种类型的字段内容(包含父类继承下来的和子类中定义的)
对象填充
不是必然需要,主要是占位 保证对象大小是某个字节的整数倍
对象的访问定位
在创建一个实例之后 通过虚拟机栈中的 reference 类型数据操作堆上的对象 现在主流的方式有两种:使用句柄访问对象和直接指针访问对象
句柄访问对象:referen 中存的是对象句柄的地址 句柄中包括对象实例数据与类型数据的具体地址信息 相当于二级指针
直接指针访问对象: reference 存的就是对象的地址 相当于一级指针
两种方式有各自的优缺点 当垃圾回收移动对象时 对于方式一而言 reference 中存储的地址是稳定的地址 不需要修改 仅需要修改对象句柄的地址 而对于方式二 则需要修改 reference 中存储的地址 从访问效率上看 方式二优于方式一 因为方式二只进行了一次指针定位 节省了时间开销 而这也是HotSpot采用的实现方式