需求:算 batch*1*32 与 batch*10*32 attention
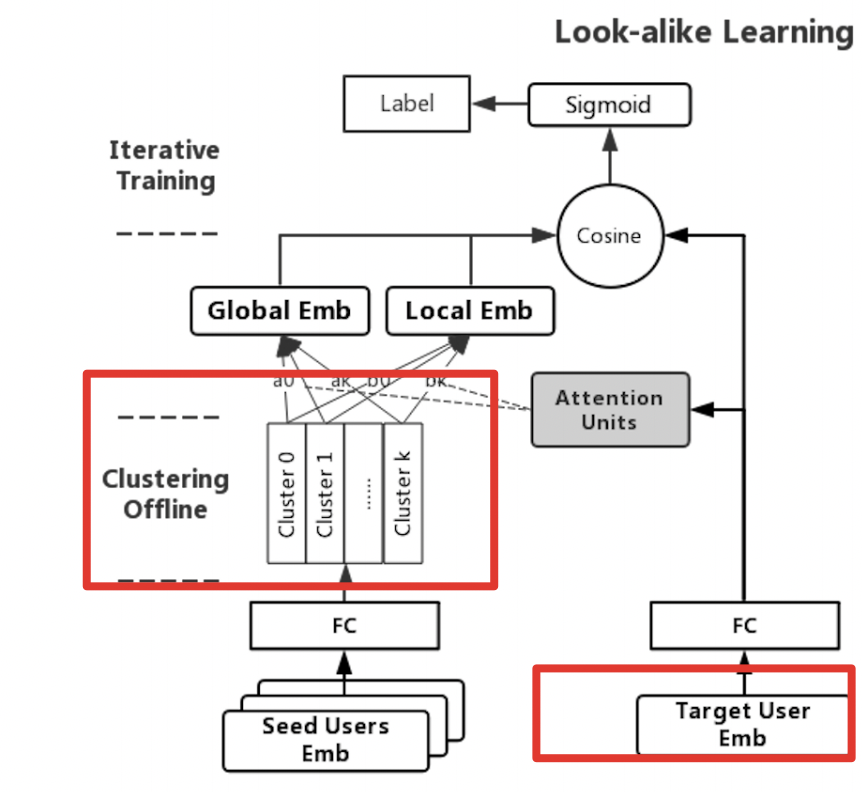
1 def local_attention_unit(self, target_user, user_seeds): 2 user_target_reshape = fluid.layers.unsqueeze(target_user,axes=[1]) 3 user_seeds_reshape = fluid.layers.reshape(user_seeds, shape=[-1, 10, 32]) 4 out = fluid.layers.matmul(user_target_reshape, user_seeds_reshape, transpose_y=True) # -1,1,10 5 out = fluid.layers.softmax(out) #-1,1,10 6 out = fluid.layers.matmul(out,user_seeds_reshape) #-1,1,32 7 out = fluid.layers.reduce_sum(out, dim=1) # batch_size * emb_size 8 return out 9 10 self.lookalike_cluster = fluid.layers.data(name="lookalike_cluster", shape=[-1,320], dtype="float32", lod_level=0, append_batch_size=False) 11 12 self.user_gcf_vec = fluid.layers.data(name="user_gcf_vec", shape=[-1,32], dtype="float32", lod_level=0, append_batch_size=False) 13 14 attention_unit_out = self.local_attention_unit( self.user_gcf_vec, self.lookalike_cluster)
reshape 具体逻辑:
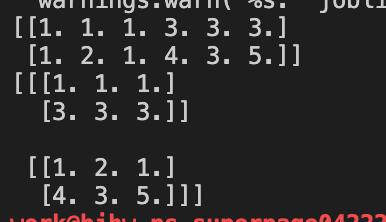
1 import paddle 2 import paddle.fluid as fluid 3 import numpy as np 4 #2*6 5 data_x = np.array([[1.0, 1.0, 1.0,3.0, 3.0, 3.0],[1.0, 2.0, 1.0,4.0, 3.0, 5.0]]) 6 print data_x 7 with fluid.dygraph.guard(): 8 x = fluid.dygraph.to_variable(data_x) 9 out_z2 = fluid.layers.reshape(x, shape=[-1,2,3]) 10 print(out_z2.numpy())