作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
《我不是药神》是这几年来我所看的电影里感触最大的,甚至成为豆瓣上多年来仅有的六部9.0评分以上的华语电影之一。
影片讲述了神油店老板程勇从一个交不起房租的男性保健品商贩,一跃成为印度仿制药“格列宁”独家代理商的故事

获取用户名和短评
name=x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()'.format(i)) content=x.xpath('//*[@id="comments"]/div[{}]/div[2]/p/text()'.format(i))
主要代码
var logMap = {} var fs = require('fs'); var iconv = require('iconv-lite'); var logger = fs.createWriteStream('./urlLog.log', { flags: 'a' // 'a' means appending (old data will be preserved) }) function logPageFile(url) { if (!logMap[url]) { logMap[url] = true; logger.write(url + ' '); } } function postData(post_data, path, cb) { // // Build the post string from an object // var post_data = JSON.stringify({ // 'data': data // }); // An object of options to indicate where to post to var post_options = { host: '127.0.0.1', port: '9999', path: '/' + path, method: 'POST', headers: { 'Content-Type': 'application/json', 'Content-Length': Buffer.byteLength(post_data) } }; var http = require('http'); // Set up the request var post_req = http.request(post_options, function (res) { res.setEncoding('utf8'); res.on('data', cb); }); logger.write('request post data 1 ') // post the data post_req.write(post_data); logger.write('request post data 2 ') post_req.end(); } module.exports = { summary: 'a rule to modify response', * beforeSendResponse(requestDetail, responseDetail) { if (/movie/1200486/i.test(requestDetail.url)) { logger.write('matched: ' + requestDetail.url + ' '); if (responseDetail.response.toString() !== "") { logger.write(responseDetail.response.body.toString()); var post_data = JSON.stringify({ 'url': requestDetail.url, 'body': responseDetail.response.body.toString() }); logger.write("post comment to server -- ext"); postData(post_data, 'douban_comment', function (chunk) { }); } } }, };
import requests from bs4 import BeautifulSoup import time import jieba from wordcloud import WordCloud from PIL import Image import numpy as np import matplotlib.pyplot as plot def getHtml(url): try: r = requests.get(url,headers={'User-Agent': 'Mozilla/5.0'}) r.raise_for_status() r.encoding = "utf-8" return r.text except: print("Failed!!!") f = open("E:/movieComment.txt",'wb+') def getData(html): soup = BeautifulSoup(html,"html.parser") comment_list = soup.find('div',attrs={'class':'mod-bd'}) for comment in comment_list.find_all('div',attrs={'class':'comment-item'}): comment_content = comment.find('span',attrs={'class':'short'}).get_text() f.write(comment_content.encode('UTF-8')) def seg_sentence(): #创建停用词列表 filefath = 'E:/stopwords.txt' stopwords = [line.strip() for line in open(filefath,'r').readlines()] #实现句子的分词 final = '' fn1 = open("E:/movieComment.txt", 'r',encoding='utf-8').read() #加载爬取的内容 sentence_seged = jieba.cut(fn1,cut_all=False) #结巴分词:精确模式 fn2 = open("E:/new.txt", "w", encoding='utf-8') for word in sentence_seged: if word not in stopwords: if word != ' ': final +=word final +=" " fn2.write(final) #写入去掉停用词的内容 def wordcloud(): # 加载图片 image = Image.open("E:/wc.jpg", 'r') img = np.array(image) # 词云 cut_text = open('E:/new.txt', 'r', encoding='utf-8').read() # 加载去掉停用词的内容 wordcloud = WordCloud( mask=img, # 使用该参数自动忽略height,width height=2000, # 设置图片高度 width=4000, # 设置图片宽度 background_color='white', max_words=1000, # 设置最大词数 max_font_size=400, font_path="C:WindowsFontsmsyh.ttc", # 如有口型乱码问题,可进入目录更换字体 ).generate(cut_text) # 显示图片 plot.imshow(wordcloud, interpolation='bilinear') plot.axis('off') # 去掉坐标轴 plot.show() #直接显示 #plot.savefig('E:/wc1.jpg') #存为图片 def main(): # 翻页处理 : max(start)=200 k = 0 #start = k i = 0 while k <200: url = 'https://movie.douban.com/subject/26752088/comments?start=' + str(k) + '&limit=20&sort=new_score&status=P' k += 20 i += 1 print("正在爬取第" + str(i) + "页的数据") #time.sleep(2) # 设置睡眠时间 html = getHtml(url) getData(html) seg_sentence() wordcloud() if __name__ == "__main__": main()
生成新的new.txt文件,内容如下


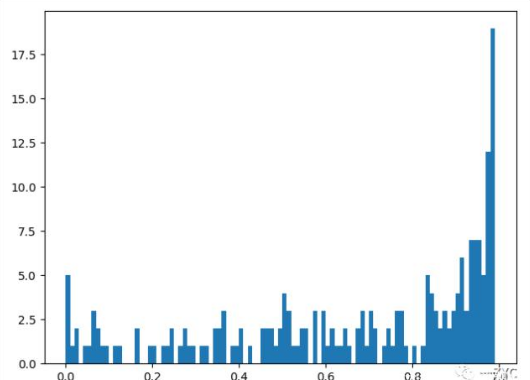
当值大于 0.5 时代表句子的情感极性偏向积极,当分值小于 0.5 时,情感极性偏向消极,当然越偏向两边,情绪越偏激。从上图情感分析来看,积极的情绪已经远远超过消极的情绪,还是受到大家的好评。
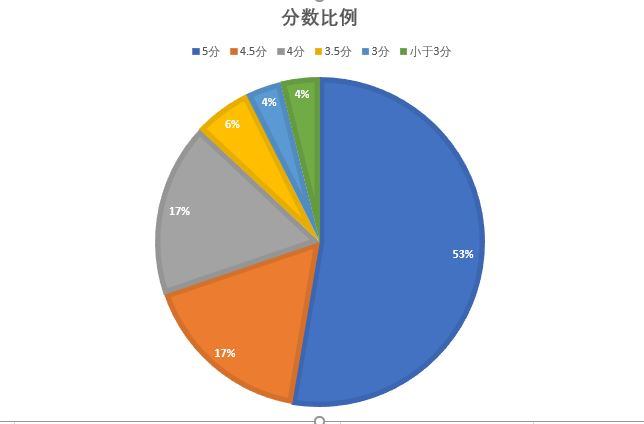
从饼状图上能够清楚地看到这部电影的评分5分(满星)的用户占了一半多,有87%的用户给了4分以上的评价。
去除一些恶意的差评,将小于3分的人数与5分人数抵消,给满分的用户还有一半,这足以说明这部电影口碑极好,深受喜欢。
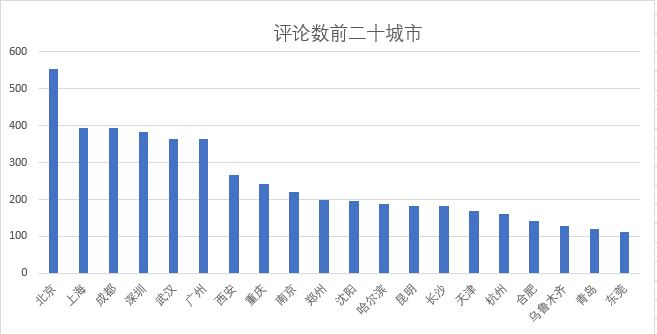
从得到的数据分析观影评论人数最多的二十个城市,发现主要是国内一些比较发达的省会城市,主要原因是影院数量多,生活水平高,并且从侧面反映了一个城市的人口流量和生活水平。
令人意外的是东莞作为广东第二个进入前二十的城市,这让我感到有点意外,同时也说明了东莞的城市转型在高速进行中,不再是以前那个工厂市了。东莞市现在是值得投资影院发展得一个不错选择。
词云图

从词云上来看,出现中国、故事、没有、徐峥,煽情,现实、导演、真实等词。
这几年有关“现实”、“真实”等的电影都是备受关注,同时也出现评价的两极化,要么就神深得人心,要么就备受争议,因为现实电影总是最容易引起普通大众的认同和共鸣。
徐峥作为主演和监制,在词云中占据重要比例这表明了用户对他的肯定与喜爱,同时说明所塑造的人物深入人心。。
而“电影”一词的频繁出现表明了这部电影的重要性。
《我不是药神》戳中的是每个人的痛点,谁能保证这一辈子自己和家人不生病呢?
一旦遇上大病,动辄上万的高昂医药费让普通人家根本无力承担。一人生病,全家拖垮,真不是危言耸听。
“我不想死,我想活着”“如果他结婚早点,说不定我还能当上爷爷”
“我吃了三年的药,吃掉了房子,吃垮了家人”
“5000?3000我们也吃不起啊”
“没有药啊,就成这个样子了。”
“今后都会越来越好吧,希望这一天早点到来。”
“现在没人弄假药了,正版药进医保了。”
真的希望中国人看得起病,吃的起药,一病毁全家的情况不要再出现了,那一天快点到来吧!