matplotlib API入门
使用matplotlib的办法最常用的方式是pylab的ipython,pylab模式还会向ipython引入一大堆模块和函数提供一种更接近与matlab的界面,matplotlib API函数位于matplotlib.pyplot模块中,其通常的引入约定是:import matplot.pyplot as plt
1、Figure和Subplot
matplotlib的图像都位于Figure对象中,你可以用plt.figure创建一个新的Figure,不能通过空Figure绘图,必须用add_subplot创建一个或多个sub_plot才行
>>> import matplotlib.pyplot as plt
>>> fig=plt.figure()
>>> ax1=fig.add_subplot(2,2,1)
>>> ax2=fig.add_subplot(2,2,2)
你可以在matplotlib的文档中找到各种图表类型,由于根据特定布局创建Figure和subplot是一件常见的任务,于是便出现一个更为方便的方法:plt.subplots,它可以创建一个新的Figure,且返回一个含有已创建的subplot对象的numpy数组。
pandas中的绘图函数
1、线型图
Series和DataFrame都有一个用于生成各类图标的plot方法,默认情况下,他们所生成的是线型图,该Series的索引会被传给matplotlib,并用于绘制x轴
>>> from pandas import *
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> s=Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10))
>>> s.plot()
>>> plt.show(s.plot())
DataFrame的plot方法会在一个subplot中为各列绘制一条直线,并自动创建图例:
>>> df=DataFrame(np.random.randn(10,4).cumsum(0),columns=['A','B','C','D'],index=np.arange(0,100,10))
>>> plt.show(df.plot())
2、柱状图
在生成的线型图的代码中加上kind='bar'(垂直树状图)或 kind='barch'(水平柱状图)即可生成柱状图,此时,Series和DataFrame的索引将会被用作X或Y的刻度。
data=Series(np.random.rand(16),index=list('abcdefghijklmnop'))
>>> data.plot(kind='bar',ax=axes[0],color='k',alpha=0.7)
<matplotlib.axes._subplots.AxesSubplot object at 0x06FA9FD0>
>>> data.plot(kind='bar',ax=axes[1],color='k',alpha=0.7)
<matplotlib.axes._subplots.AxesSubplot object at 0x049D02D0>
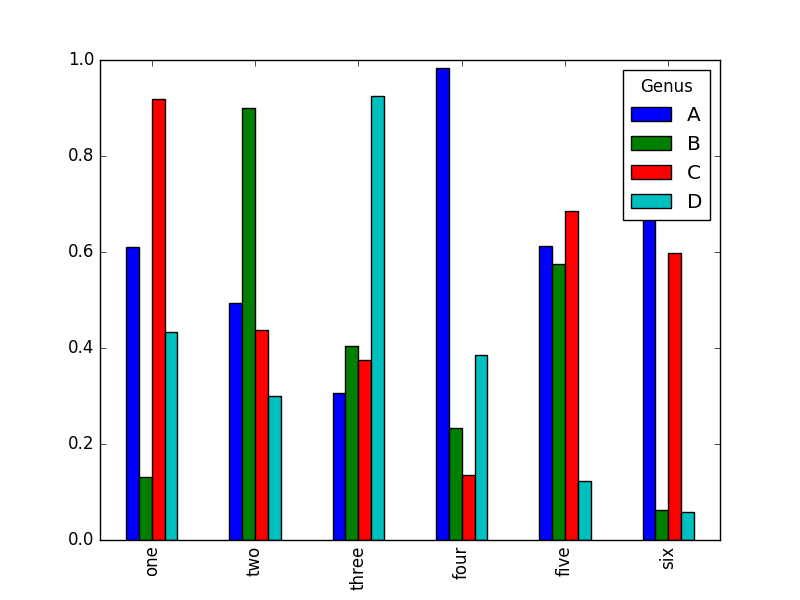
对于DataFrame,柱状图会将每一行的值分为一组
>>> df=DataFrame(np.random.rand(6,4),index=['one','two','three','four','five','six'],columns=['A','B','C','D'])
>>> df.columns.name='Genus'
>>> df
Genus A B C D
one 0.610197 0.132144 0.919492 0.432829
two 0.493323 0.899049 0.438195 0.300159
three 0.305448 0.404252 0.374776 0.924542
four 0.982561 0.233063 0.135196 0.385672
five 0.613274 0.574884 0.684504 0.123448
six 0.791576 0.062249 0.597673 0.058899
>>> plt.show(df.plot(kind='bar'))
3、直方图和密度图
直方图是一种可以对值频率进行离散化显示的柱状图,另一种是密度图,它是通过计算可能会产生观测数据的连续概率分布的估计而产生的。一般过程是将该分布近似为一组核分布,因此,密度图也被称作KDE图,调用plt时加上kind='kde'即可生成一张密度图。
4、散布图
散布图是观察两个一维数据序列之间的关系的有效手段,matplotlib的scatter方法是绘制散布图的主要方法。
>>> from pandas import *
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> macro=read_csv(r'D:书籍与代码资料利用python进行数据分析代码和数据集ch08macrodata.csv')
>>> data=macro[['cpi','m1','tbilrate','unemp']]
>>> trans_data=np.log(data).diff().dropna()
>>> trans_data[-5:]
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560
>>> plt.scatter(trans_data['m1'],trans_data['unemp'])
<matplotlib.collections.PathCollection object at 0x0525C6D0>
>>> plt.show()

在探索式的数据分析中,同时观察一组变量的散布图是很有意义的,这也被称为散布矩阵;pandas提供了一个能从DataFrame创建散布图矩阵的scatter_matrix函数。
Python图形化工具生态系统介绍
Chaco:适合用复杂的图形化方法表达数据的内部关系,对交互支持较多与适合
mayayi:基于C++图形库的图形工具包