最近在看Linux进程间通信,看到共享内存了,思索一个问题,进程创建的共享内存是系统中哪一块内存呢?
从stackoverflow中找到了答案:Shared memory in process address space?
问题1:我从操作系统书中了解到Linux的进程结构包括:代码段、数据段、堆段、栈段,当进程创建共享内存时,创建的共享内存属于哪部分?在堆吗?
问题2:内核知道系统中每个进程的PCB格式信息,并将此PCB保存在进程表中。进程表双向链表是什么?
答案1:我猜你的问题是关于进程内存布局。如果是这样,Linux和Solaris进程具有以下部分:
Text
Data
BSS
Heap
MMS (memory mapping segment)
Stack
堆和栈之间的内存(所谓内存映射段(MMS)),负责共享内存映射。不仅如此,共享库,打开的文件也映射到该部分内存中。(多个进程的逻辑地址指向同一块物理地址)
你也可以通过pmap命令检查Linux上的进程内存布局,或者读取进程映射文件/proc//maps。下面是pmap实用程序在Linux机器上检查的DB2进程内存布局的一个片段(查看堆栈和shmid,共享内存ID,条目):
0000000000400000 52K r-x-- /opt/ibm/db2/bin/db2vend
000000000060d000 4K rwx-- /opt/ibm/db2/bin/db2vend
000000000c33e000 132K rwx-- [ anon ]
0000000200000000 35520K rwxs- [ shmid=0x57a58007 ]
000000323f200000 112K r-x-- /lib64/ld-2.5.so
and more more more shared libraries
00002b55bb45b000 4K r-x-- /lib64/libnss_files-2.5.so
00002b55bb45c000 4K rwx-- /lib64/libnss_files-2.5.so
00002b55bb45d000 39252K rwxs- [ shmid=0x57a50006 ]
00002b55bdab2000 1152K rwx-- [ anon ]
00007ffffaf35000 84K rwx-- [ stack ]
ffffffffff600000 8192K ----- [ anon ]
答案2:
进程链表
进程链表是一种双向链表数据结构(list_head),简单的说一下双向链表。每一个双向链表,都有一组操作,插入和删除一个元素,扫描链表等等。双向链表和链表相同,但双向链表除了有指向下一个元素的指针,还有指向上一个元素的指针,所以被称为双向链表。
list_head 结构
struct list_head {
struct list_head *next, *prev;
};
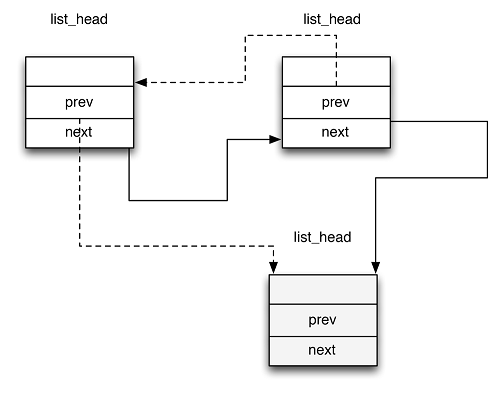
进程链表是一个双向链表(list_head),进程链表把所有进程的描述符链接起来。每个task_struct 结构都包含一个list_head类型的tasks字段,这个类型的prev和next字段分别指向前面和后面的task_struct元素。
进程链表的表头是init_task描述符,就是0进程(process 0)或swapper进程的进程描述符。init_task的tasks.prev字段指向链表中最后插入的进程描述符的tasks字段。SET_LINKS和REMOVE_LINKS宏分别用于从进程链表中插入和删除一个进程描述符。另外for_each_process宏用来扫描整个进程链表。
TASK_RUNNING状态的进程链表
当内核寻找一个在CPU上运行的进程,必须考虑可运行的进程。早先的Linux把所有可运行的进程都放在一个叫做运行队列(runqueue)的链表中,由于维持链表中的进程优先级排序开销过大,因此早起的调度程序不得不为了某些特殊的功能扫描整个链表。在Linux 2.6实现的运行队列则有所不同。其目的是让调度程序能在固定的时间内选出『最佳』可运行进程,与队列中可运行的进程数无关。
提高调度程序运行速度的诀窍是建立多个可运行进程链表,每种进程优先级对应一个不同的链表。
每个task_struct描述符包含一个list_head类型的字段run_list。如果进程的优先级等于k1,run_list字段把该进程加入优先权为k的可允许进程链表中。在多CPU系统中,每个CPU都有自己的运行队列,这是一个通过使数据结构更复杂来改善性能的典型例子。
进程描述符的prio字段存放进程的动态优先级,而array字段是一个指针,指向当前运行队列的prio_array_t的数据结构。
参考:
http://guojing.me/linux-kernel-architecture/posts/process-list/