xml
1. 概念
- Extensible Markup Language 可扩展标记语言
可扩展:标签都是自定义的. - 功能:
- 存储数据
- 配置文件
- 在网络中传输
- 存储数据
- xml 与 html 的区别
他们连是俩兄弟,- html 标签都是预定义, xml 都是自定义的.
- html 语法很松散,xml 语法很严格,xml 跟 properties竞争.
- html 是展示数据,xml 是存储数据的.
w3c 万维网联盟 ,W3C是World Wide Web Consortium(万维网联盟)的缩写,像HTML、XHTML、CSS、XML的标准就是由W3C来定制。
2. 语法
2.1 基本语法:
- xml 文档的后缀名 .xml
- xml 第一行必须定义为文档声明
- xml 文档中有且仅有一个根标签
- 属性值必须使用引号(单双都可)引起来
- 标签必须正确关闭
- xml 标签名称区分大小写
2.2 快速入门:
<!--?xml version='1.0'?-->
<users>
<user id="1">
<name>张三</name>
<age>21</age>
<gender>male</gender>
</user>
<user id="2">
<name>李四</name>
<age>18</age>
<gender>female</gender>
</user>
</users>
2.3 组成部分:
- 文档声明
- 格式:
- 属性列表:
version:版本号[必须写]
encoding:编码方式.告知解析引擎当前文档使用的字符集,默认使用:iso-8859-1
standalone:是否独立.(取值有两个,yes 不依赖其他文件,no)
- 指令(了解):结合 css的
- 标签:标签名称自定义的
规则:- 名称不能包含字母,数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字母 xml (或者 XML Xml等等)开始
- 名称不能包含空格
- 属性
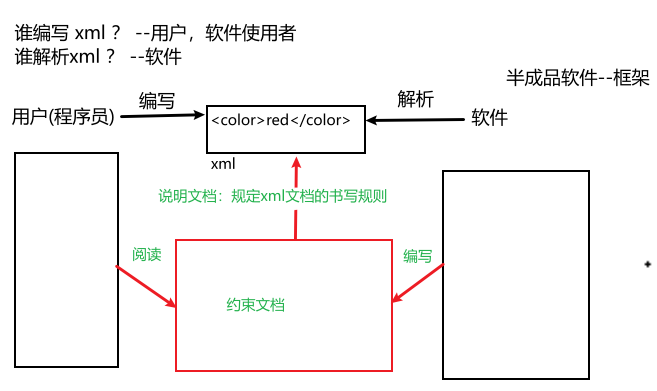
约束(id 属性值唯一)约束:规定 xml文档的书写规则
最为框架的使用者(程序员):- 能够在 xml中引入约束文档
- 能够简单的读懂约束文档
- 文本
CDATA区:在该区域中的数据会被原样展示<!--[CDATA[ (需要显示的文本) if (a < b && a --> c){} ]]>
2.4 分类
- DTD:一种简单的约束技术.后缀 .dtd
- SCHEMA:一种复杂的约束技术.后缀 .xsd
- DTD:
- 引入 dtd文档到 xml文档中
- 内部 dtd:将约束规则定义在 xml文档中
<!--ELEMENT 自定义子标签名 (参数)--> ]> - 外部 dtd:将约束的规则定义在外部的 dtd文件中.
- 本地: <!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">
- 网络: <!DOCTYPE 根标签名 PUBLIC "dtd文件名字" "dtd文件的位置URL">
- 内部 dtd:将约束规则定义在 xml文档中
- 引入 dtd文档到 xml文档中
- Schema:
- 填写 xml文档的根元素
- 引入 xsi 前缀 xmIns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- 引入 xsd 文件命名空间 xsi:schemaLocation="http://www.itcast/cn/xml student.xsd"
- 为每个 xsd约束声明一个前缀,作为标识符 xmIns="http://www.itcast.cn/xml"
3. 解析
操作 xml文档,将文档中的数据读取到内存中
3.1 操纵 xml文档
- 解析(读取):将文档中的数据读取到内存中
- 写入:将内存中的数据保存到 xml文档中.持久化的存储
3.2 解析 xml的方式:
- DOM:将标记语言文档一次性加载进内存,在内存中形成一颗 dom树
优点:操作方便,可以对文档进行 crud所操作
缺点:消耗内存 - SAX: 逐行读取,基于事件驱动的.
优点:不占内存
缺点:只能读取,不能 增删改
3.3 xml常见的解析器:
- jaxp:sun 公司提供的解析器,支持 dom和 sax两种思想
- dom4j:一款非常优秀的解析器
- jsoup:一款 java的 html解析器,可直接解析某个 url地址,html文本内容.提供省立的 api,取出和操作数据.
- pull: android操作系统内置的解析器,sax方式的.
3.4 原生 jdk自带的解析 xml
3.4.1 相关的类型
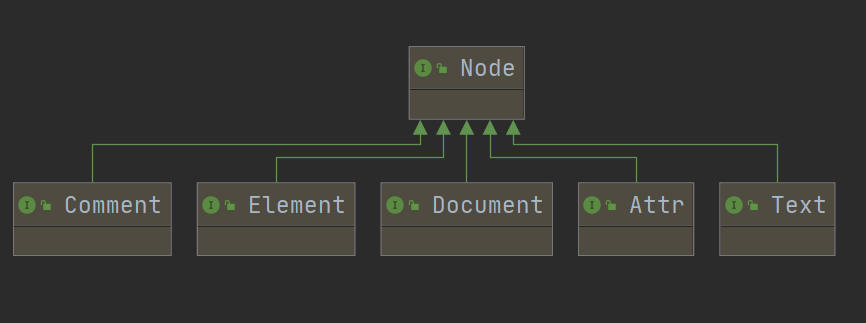
- 包:org.w3c.dom
Node接口:所有类型的根接口---节点元素Element接口:所有的标签Text接口:所有的文本Comment接口:所有的注释Attr接口:所有的属性Document接口:文档本身
3.4.2 类型常用方法
Doument 方法 文档本身
NodeList getElementsByTagName(标签名) 获取文档中指定的所有标签对应的集合
Node createElement(String) 创建一个标签
Element 方法 元素
NodeList getElementsByTagName(标签名) 获取当前标签对象中指定的子标签对应的集合
String getTextContent(); 获取文本内容
void setTextContext(String) 设置文本内容
NamedNodeMap getAttributes();获取所有的属性
String getAttribute(String) 获取属性值
void setAttribute(String,String) 添加、修改属性值
void removeAttribute(String) 删除属性
Node getParaentNode() 获取父标签
Node appendChild(node) 在当前标签下添加一个子标签 返回的子标签
void removeChild(node) 删除当前标签的参数子标签
void removeAttribute(String) 删除属性
Node 方法 节点元素
String getNodeName(); 获取元素名字
int getNodeType(); 获取元素的类型: Document是9 Comment是8 Element是1 Attr是2 Text是3
Attr 方法 属性
String getName() 获取属性名
String getValue() 获取属性值
NamedNodeMap 和 NodeList 方法
int getLength() 获取长度
Node item(int index)获取node元素
3.4.3 准备
<?xml version="1.0" encoding="utf-8"?><!--声明区:设置当前 xml的版本和编码集-->
<class><!--数据区:当前 xml中的数据-->
<students id="s_01">
<studnet id="stu_011">
<name>小美</name>
<gender>女</gender>
<score>60</score>
<party>false</party>
</studnet>
<studnet id="stu_012">
<name>小丽</name>
<gender>女</gender>
<score>86</score>
<party>true</party>
</studnet>
<studnet id="std_013">
<name>小梅</name>
<gender>女</gender>
<score>96</score>
<party>true</party>
</studnet>
</students>
</class>
public class Demo1 {
public static void main(String[] args) {
String path = "day09-reflection"+File.separator+"src"+File.separator+"student.xml";
System.out.println(new File(path).getAbsolutePath());
Document document = xmlDom(path);
System.out.println("XmlDocument = " + document);
}
@Test
public void test1() {
//【idea中】 注意 junit 的绝对路径在当前 module下,main方法的绝对路径在当前 父目录
String path = "src" + File.separator + "student.xml";
Document document = xmlDom(path);
System.out.println("XmlDocument = " + document);
}
/**
* 由xml路径 获取document对象 [import org.w3c.dom.Document;]
*
* @param path xml路径
* @return document对象
*/
public static Document xmlDom(String path) {
File file = new File(path);
if (file.exists()) { //如果文件存在
//获取文档解析器工厂对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder;
try {
//获取文档解析器对象
builder = factory.newDocumentBuilder();
//通过解析器对象的 parse 由xml获得 document对象
return builder.parse(file);
} catch (Exception e) {
e.printStackTrace();
}
}
return null;
}
}
3.4.4 查询
/**
* 遍历整个 xml文件
*
* @param node document 对象
*/
public static void showXmlDocument(Node node) {
System.out.println("元素:" + node.getNodeName() + ":" + node.getNodeType());
//判断类型
if (node instanceof Document) {
System.out.println("当前元素是:文档");
//获取其所有的子标签
NodeList chNodes = node.getChildNodes();
if (chNodes != null) {
for (int i = 0; i < chNodes.getLength(); i++) {
Node ch = chNodes.item(i);
showXmlDocument(ch); //递归遍历
}
}
} else if (node instanceof Element) {
Element element = (Element) node;
System.out.println("当前元素是:标签");
//获取属性
NamedNodeMap nodeMap = element.getAttributes();
if (nodeMap != null) {
for (int i = 0; i < nodeMap.getLength(); i++) {
showXmlDocument(nodeMap.item(i)); //递归遍历
}
}
//判断是否有子标签
if (element.hasChildNodes()) {
NodeList nList = element.getChildNodes();
for (int i = 0; i < nList.getLength(); i++) {
showXmlDocument(nList.item(i)); //递归遍历
}
} else {
//获取文本内容
System.out.println("当前标签的文本内容:" + element.getTextContent());
}
} else if (node instanceof Attr) {
Attr attr = (Attr) node;
System.out.println("属性:" + attr.getName() + "==" + attr.getValue());
} else if (node instanceof Comment) {
Comment com = (Comment) node;
System.out.println("注释:" + com.getNodeValue());
}
}
3.4.5 修改
/**
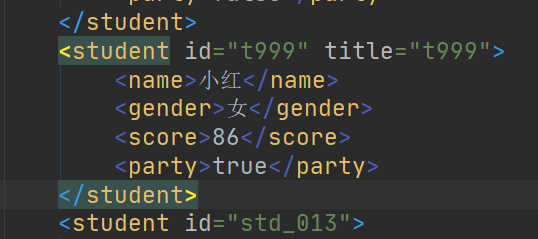
* 把 students id="s_01" 的 student id="stu_012" 小丽改为 小红
* @param path xml路径
*/
public void updateXml(String path) {
Document doc = xmlDom(path);//由xml路径 获取document对象
//获取所有的 students 标签
NodeList list = doc.getElementsByTagName("students");
for (int i = 0; i < list.getLength(); i++) {
Element element = (Element) list.item(i);
//获取其id属性
String id = element.getAttribute("id");
if (id.equals("s_01")) {
//获取其中素有的 name标签
NodeList nameList = element.getElementsByTagName("name");
for (int k = 0; k < nameList.getLength(); k++) {
//获取 的下一个 name标签
Element eleName = (Element) nameList.item(k);
//获取其文本内容
String name = eleName.getTextContent().trim();
if ("小丽".equals(name)) {
//获取当前 name标签的父标签 student标签
Element elePare = (Element) eleName.getParentNode();
//获取此父亲标签的 sex子标签
Element eleNewName = (Element) elePare.getElementsByTagName("name").item(0);
//修改完毕内容
eleNewName.setTextContent("小红");
//给当前学生标签添加 属性
elePare.setAttribute("title", "t999");
//更改学生标签的属性
elePare.setAttribute("id", "t999");
break;
}
}
}
}
//把更改后的 document对象的信息刷新到 xml文件中
updateXmlFlush(path, doc);
}
/**
* 把 更新后的 document对象刷新到 xml中
*
* @param path xml路径
* @param doc document 对象
*/
public static void updateXmlFlush(String path, Document doc) {
File file = new File(path);
if (file.exists()) {
try {
//创建 Transformer 工厂对象
TransformerFactory factory = TransformerFactory.newInstance();
//创建 Transformer 对象
Transformer tf = factory.newTransformer();
//设置编码集合 【默认utr-8】
tf.setOutputProperty(OutputKeys.ENCODING, "utf-8");
//调用 transform 方法把 doc信息刷新到 xml中
// transform(Source xmlSource, Result outputTarget)
tf.transform(new DOMSource(doc), new StreamResult(file));
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.4.6 添加
/**
* xml 添加
*
* @param student 学生对象
* @param path xml路径
*/
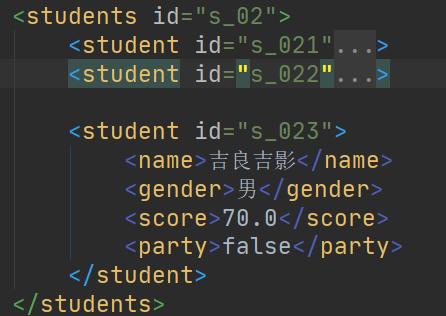
public static void xmlAdd(Student student, String path) {
Document doc = xmlDom(path);
//获取第二个 students 标签
Element eleStuds = (Element) doc.getElementsByTagName("students").item(1);
// 创建 student 标签
Element eleStud = doc.createElement("student");
//添加 id属性
eleStud.setAttribute("id", "s_023");
//创建子标签
Element name = doc.createElement("name");
Element gender = doc.createElement("gender");
Element score = doc.createElement("score");
Element party = doc.createElement("party");
//设置文本内容
name.setTextContent(student.getName());
gender.setTextContent(student.getGender() + "");
score.setTextContent(student.getScore() + "");
party.setTextContent(student.getParty() + "");
//把子标签添加到父标签下
eleStud.appendChild(name);
eleStud.appendChild(gender);
eleStud.appendChild(score);
eleStud.appendChild(party);
//把 student 添加到 students标签下
eleStuds.appendChild(eleStud);
//把更改后的 document对象的信息刷新到 xml中
updateXmlFlush(path, doc);
}
// xmlAdd(new Student("吉良吉影", '男', 70.f, false), path);
3.4.7 删除
/**
* @param path xml路径
*/
public static void xmlDeleteNode(String path) {
//把参数student对象的信息添加到第一个班级标签下
Document doc = xmlDom(path);
//删除第一个student标签的title属性
Element eleStu = (Element) doc.getElementsByTagName("student").item(0);
eleStu.removeAttribute("title");
//删除第二个student标签
Element eleStu2 = (Element) doc.getElementsByTagName("student").item(1);
eleStu2.getParentNode().removeChild(eleStu2);//通过父标签 删除子标签
//吧更改后的document对象的信息刷新到xml中
updateXmlFlush(path, doc);
}
3.5 jsoup 使用
3.5.1 快速入门
步骤:
- 导入 jar包(jsoup-1.11.2.jar)
- 获取 document对象
- 获取对应的标签
- 获取数据
public class JsoupDemo1{
public static void main(String[] args) throws IOException{
//2. 获取 document对象,根据 xml文档获取
//2.1 利用反射获取获得一个流传入路径拿到 student.xml的 相对路径
String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath();
//2.2 解析 xml文档,加载文档进内存,获取 dom树 -->document
Document document = Jsoup.parse(new File(path,"utf-8");
//3. 获取元素对象 element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size);
//3.1 获取第一个name 的 element对象
Element element =elements.get(0);
System.out.println(name);
}
}
3.5.2 对象的使用
Jsoup:工具类,可以解析 html或 xml文档,返回 document
- parse:静态方法,解析 html或 xml文档,返回 document
parse(File in,String charsetName);解析 xml或 html文件的. parse(String html);解析 xml或 html字符串的 parse(URL url,int timeoutMillis);通过网络路径获取指定的 html或 xml的文档对象(这种可以做爬虫的小程序,比价网)
document:文档对象,代表内存中的 dom树
- 获取 element对象
getElementById(String id); 根据id属性值获取唯一的element对象 getElementByTag(String tagName);根据标签名称获取元素对象集合 getElementByAttribute(String key);根据属性名称获取元素对象集合 getElementsByAttributeValue(String key,String value);根据对象的属性名和属性值获取对象集合
elements:元素 element对象的集合,可以当作ArrayList
element:元素对象
- 获取子元素对象
getElementById(String id); 根据id属性值获取唯一的element对象 getElementByTag(String tagName);根据标签名称获取元素对象集合 getElementByAttribute(String key);根据属性名称获取元素对象集合 getElementsByAttributeValue(String key,String value);根据对象的属性名和属性值获取对象集合 - 获取属性值
String attr(String key);根据属性名称获取属性值 - 获取文本内容
String text();获取文本内容 String html();获取标签体的所有内容(包括标签的字符串内容)
node:节点对象(是document和element 的爹)
3.5.3 根据选择器查询
1· selector:选择器
Document 中的 select方法
Elements select (String cssQuery);
语法:参考 Selector类中定义的语法
- XPath:XPath即为 xml路径语言,一种用来确定 xml(标准通用标记语言的子集),文档中某部分位置的语言
- 使用 Jsoup的 Xpath需要额外导入 JsoupXpath-0.3.2.jar包
步骤:- 获取指定的 xml的 path
- 获取 document对象
- 根据 document对象,创建 JXDocument对象
- 结合 xpath语法查询
- 使用 Jsoup的 Xpath需要额外导入 JsoupXpath-0.3.2.jar包
//1.获取student.xml的path
String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath();
//2.获取Document对象
Document document = Jsoup.parse(new File(path), "utf-8");
//3.根据document对象,创建JXDocument对象
JXDocument jxDocument = new JXDocument(document);
//4.结合xpath语法查询
//4.1查询所有student标签
List<JXNode> jxNodes = jxDocument.selN("//student");
for (JXNode jxNode : jxNodes) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.2查询所有student标签下的name标签
List<JXNode> jxNodes2 = jxDocument.selN("//student/name");
for (JXNode jxNode : jxNodes2) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.3查询student标签下带有id属性的name标签
List<JXNode> jxNodes3 = jxDocument.selN("//student/name[@id]");
for (JXNode jxNode : jxNodes3) {
System.out.println(jxNode);
}
System.out.println("--------------------");
//4.4查询student标签下带有id属性的name标签 并且id属性值为itcast
List<JXNode> jxNodes4 = jxDocument.selN("//student/name[@id='itcast']");
for (JXNode jxNode : jxNodes4) {
System.out.println(jxNode);
}