环境和原理说明
测试设备: 小米11, QCOM888.
使用 NDK-r22 编译器. 使用 OpenCV 的 Mat, imread/imwrite 等基础设施,以及作为对照比较性能。
使用 C++ 模板技术: 由于确定了是 RGB 因此编译器确定通道数量为3;同时想支持 BGR,因此增加 bIdx 这一模板参数。
测试图片: W=7680, H=4320,3通道。
RGB 转 Gray 的公式是 Gray = R2Y * R + G2Y * G + B2Y * B, 其中
R2Y = 0.299;
G2Y = 0.587;
B2Y = 0.114;
naive 实现
template<int bIdx>
void cvtcolor_bgr_to_gray(const cv::Mat& src, cv::Mat& dst)
{
if (src.depth() != CV_8U)
{
CV_Error(cv::Error::StsBadArg, "only support uchar type");
}
if (src.channels() != 3)
{
CV_Error(cv::Error::StsBadArg, "src is not 3 channels");
}
if (bIdx != 0 && bIdx != 2)
{
CV_Error(cv::Error::StsBadArg, "bIdx should be 0 or 2");
}
const int srcw = src.cols;
const int srch = src.rows;
const int channels = 3;
dst.create(src.size(), CV_8UC1);
for (int i = 0; i < srch; i++)
{
for (int j = 0; j < srcw; j++)
{
uchar b = src.ptr(i, j)[bIdx];
uchar g = src.ptr(i, j)[1];
uchar r = src.ptr(i, j)[2-bIdx];
dst.ptr(i, j)[0] = (0.299*r + 0.587*g + 0.114*b);
}
}
}
优化策略和实现
加速策略包括:
- 编译期确定 src channels 等于3,编译期确定 bIdx (naive实现)
也尝试了编译期确定 srch, srcw, 但没有加速效果 - 像素访问从 Mat.ptr(i, j) 改为指针 (cvtcolor_bgr_to_gray_v1)
- 提速明显
- 定点化到 uint16 (shift=8) (cvtcolor_bgr_to_gray_v2)
- 提速明显
- ARM NEON Intrinsics (cvtcolor_bgr_to_gray_v3)
- 几乎不提速
- 多线程(使用 cv::parallel_for_ + lambda 实现, 也可以用 OpenMP) (cvtcolor_bgr_to_gray_v4)
- 小幅加速
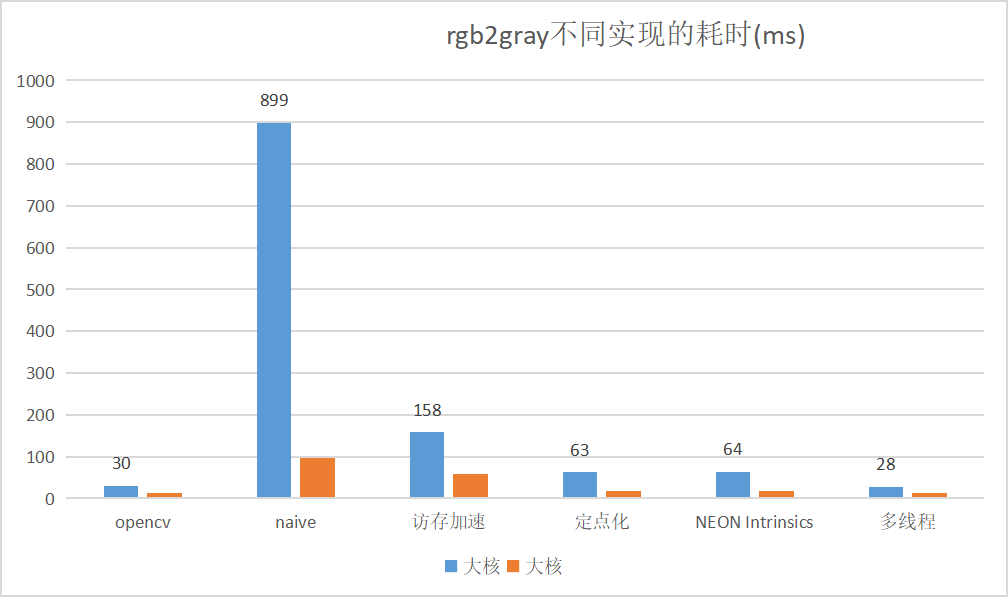
naive 实现和最优实现的速度差很多,同时也要注意大小核心的性能相差很多:
v4 的代码:
template<int bIdx = 0>
void cvtcolor_bgr_to_gray_v4(const cv::Mat& src, cv::Mat& dst)
{
if (src.depth() != CV_8U)
{
CV_Error(cv::Error::StsBadArg, "only support uchar type");
}
if (src.channels() != 3)
{
CV_Error(cv::Error::StsBadArg, "src is not 3 channels");
}
if (bIdx != 0 && bIdx != 2)
{
CV_Error(cv::Error::StsBadArg, "bIdx should be 0 or 2");
}
const int srcw = src.cols;
const int srch = src.rows;
const int channels = 3;
dst.create(src.size(), CV_8UC1);
const uchar* src_line = src.data;
const int src_step = src.step1();
uchar* dst_line = dst.data;
const int dst_step = dst.step1();
const uint8_t R2Y_fx_u8 = 77; // 0.299 * (1 >> 8)
const uint8_t G2Y_fx_u8 = 150; // 0.587 * (1 >> 8)
const uint8_t B2Y_fx_u8 = 29; // 0.114 * (1 >> 8)
const uint16_t R2Y_fx = R2Y_fx_u8;
const uint16_t G2Y_fx = G2Y_fx_u8;
const uint16_t B2Y_fx = B2Y_fx_u8;
const uint16_t shift = 8;
const uint16_t half_fx = (1 << (shift - 1));
#if __ARM_NEON
uint8x8_t v_R2Y_fx = vdup_n_u8(R2Y_fx_u8);
uint8x8_t v_G2Y_fx = vdup_n_u8(G2Y_fx_u8);
uint8x8_t v_B2Y_fx = vdup_n_u8(B2Y_fx_u8);
uint16x8_t v_half_fx = vdupq_n_u16(half_fx);
#endif // __ARM_NEON
cv::parallel_for_(cv::Range(0, srch), [&](const cv::Range& range)
{
for (int i = range.start; i < range.end; i++)
{
const uchar* src_pixel = src_line;
uchar* dst_pixel = dst_line;
#if __ARM_NEON
int nn = srcw >> 3;
int remain = srcw - (nn << 3);
#else
int remain = srcw;
#endif // __ARM_NEON
#if __ARM_NEON
for (int j = 0; j < nn; j++)
{
uint8x8x3_t v_src = vld3_u8(src_pixel);
uint16x8_t v_b2p = vmull_u8(v_src.val[0], v_B2Y_fx);
uint16x8_t v_g2p = vmull_u8(v_src.val[1], v_G2Y_fx);
uint16x8_t v_r2p = vmull_u8(v_src.val[2], v_R2Y_fx);
uint16x8_t v_gray = vaddq_u16(vaddq_u16(vaddq_u16(v_b2p, v_g2p), v_r2p), v_half_fx);
uint8x8_t v_gray_u8 = vshrn_n_u16(v_gray, 8);
vst1_u8(dst_pixel, v_gray_u8);
src_pixel += 8*channels;
dst_pixel += 8;
}
#endif // __ARM_NEON
for (; remain >= 0; remain--)
{
uchar b = src_pixel[0];
uchar g = src_pixel[1];
uchar r = src_pixel[2];
//uint16_t gray = (77 * r + 151 * g + 28 * b + (1 << 7)) >> 8;
uint16_t gray = (R2Y_fx * r + G2Y_fx * g + B2Y_fx * b + half_fx) >> shift;
*dst_pixel++ = cv::saturate_cast<uint8_t>(gray);
src_pixel += channels;
}
src_line += src_step;
dst_line += dst_step;
}
});
}