- 1. 函数返回类对象时,发生(调用)了什么?
- 2. 类定义体内定义和实现的函数,会被自动用inline修饰
- 3. 结构体/类 定义 字节对齐
- 4. this指针
- 5. 仅仅是函数返回值不同,不叫做函数重载
- 6. 默认构造函数
- 7. C++编译器何时产生默认构造函数?
- 8. C++编译器不报warning,但仍然有UB的一个例子
- 9. 虚析构函数(virtual destructor)和动态绑定
- 10. explict关键字,用于单参数构造函数
- 11. unique_ptr和shared_ptr的使用
- 12. 虚函数和纯虚函数
- 13. enum class类型
- 14. =default修饰的构造函数声明
- 15. VS2017报错,变量dv::size_t不是类型名
- 16. VS2017的Intellisence和编译器,明显不是同一个东西
- 17. static局部变量无法设断点吗?为什么?
- 18. 读取中文名(UTF-8编码)文件或内容失败
- 19. VS可执行程序无法执行
- 20. Dism++清理C盘后,VS2013的工程显示不可用
- 21. 非法内存地址,无法用nullptr检查出来
- 22. VS错误C1071,“在注释中遇到意外的文件结束”
- 23. GCC/G++和GLIBCXX版本对照关系
- 24.注意第二处报错
- 25. 标准库的头文件在哪里?
- 26. 在C++代码中尽量不要用纯C的头文件
用纯C写码一年有余,基本的指针操作也算熟悉了。现在考虑用C++,一来是能用引用、STL、C++11提升开发效率,二来是ncnn、opencv等优秀开源项目大多是C++写就,不用C++就真的没法搞懂它们。这里记录C++相关的基础知识。
1. 函数返回类对象时,发生(调用)了什么?
class CTest {
public:
CTest() {
cout << "CTest construct" << endl;
data = new char[10];
strncpy(data, "hello", 10);
}
CTest(const CTest& test) {
cout << "copy construct" << endl;
data = new char[10];
memcpy(data, test.data, 10);
}
~CTest() {
cout << "CTest destruct" << endl;
delete data;
data = NULL;
}
CTest& operator=(const CTest& m) {
cout << "CTest operator=" << endl;
return *this;
}
public:
char* data;
};
CTest GetTest() {
CTest test;
return test;
}
void test_case1() {
cout << "========== test case 1" << endl;
CTest qwq;
qwq = GetTest();
}
void test_case2() {
cout << "========== test case 2" << endl;
CTest qwq = GetTest();
}
int main(int argc, char** argv) {
test_case1();
test_case2();
return 0;
}

解读:
test case1是,先创建对象,再从函数返回类对象并且赋值给已创建的对象,因此,函数GetTest()内的最后会调用拷贝构造函数(产生临时对象),赋值给qwq则调用operator=函数。
test case2是,函数返回时不产生临时对象,而直接调用拷贝构造函数从而生成qwq。
其他参考:C++中函数返回值是一个对象时的问题
2. 类定义体内定义和实现的函数,会被自动用inline修饰
把简短却又频繁出现的函数语句调用,用宏封装,这是C的做法。好处是减少了代码量,起到了一定的抽象作用,并且没有额外开销;缺点是需要小心的写一些括号来避免调用出错,并且该语句没法断开。
inline则相当于这种功能诉求的改进实现,在使用inline关键字后,如果编译器编译选项开启了inline优化,那么函数将就地展开,没有函数调用栈展开的开销。
对于类的成员函数,如果是在类体内部直接实现的,那么这个函数就默认带有inline属性,即使你不明确写出来。这是编译器默默开启的。
3. 结构体/类 定义 字节对齐
默认是按照类(或结构体)定义中占用最长的那个成员的长度作为基准长度来对齐的,而不是无脑的“4字节对齐”。e.g.:
#include <stdio.h>
#include <iostream>
using namespace std;
class Hock{
short age;
char data;
};
int main() {
cout << sizeof(Hock) << endl;
return 0;
}
输出4。
4. this指针
在C++的类成员函数中,可以使用this指针来明确说明,用的变量是“当前对象的变量”,用的函数是“当前类的函数”。
那么,this作为一个指针,指向的地址到底是多少呢?实际上,当前成员函数被一个特定的类对象调用,不妨称为intance,这个instance的地址(&instance),就是this的值。
如何验证呢?在成员函数中调用this->xxx(成员函数或成员变量),并且设定断点(或者直接打印),查看this的值和instance的地址,看是否相同。可以打印输出比较,也可以在VS的watch窗口中比较。
5. 仅仅是函数返回值不同,不叫做函数重载
例如:
int get_max(int a, int b) {
return a>b?a:b;
}
float get_max(int a, int b) {
return a>b?a:b;
}
C++编译器会报错:
main.cpp:20:7: error: functions that differ only in their return type cannot be overloaded
float get_max(int a, int b) {
~~~~~ ^
main.cpp:17:5: note: previous definition is here
int get_max(int a, int b) {
~~~ ^
1 error generated.
6. 默认构造函数
默认构造函数是可以无实参调用的构造函数(以空参数列表定义,或为每个形参提供默认实参而定义)。拥有公开默认构造函数的类型是可默认构造 (DefaultConstructible) 的。
以前一直以为,如果没有定义默认构造函数,编译器会自动帮你定义。其实不对。
事实:如果没有定义默认构造函数,编译器会自动帮你声明一个,但是不一定帮你定义它。除非:
- 类的成员变量m是一个类对象,并且m有显示的定义构造函数
- 类继承自父类,并且父类有显示定义构造函数
- ...
感觉过于复杂,详细细节要参考默认构造函数,不过,比较好的实践是,每个class、struct、union定义的时候,都明确定义构造函数.
7. C++编译器何时产生默认构造函数?
为什么提出这个问题:脑中残存的C++课程记忆让我觉得“如果定义class时没有定义默认构造函数那么编译器会帮我们定义一个”,但是如下的代码编译会报错:
class Blob {
public:
int age;
};
void test_case() {
Blob a;
cout << a.age << endl;
}
一番搜索后了解到,如果定义class时没有定义默认构造函数,编译器只有在如下4种情况下,才会帮我们定义默认构造函数:
-
类A内数据成员是对象b,并且对象b的类B中,人工定义了默认构造函数:
-
类A的基类Base中,人工定义了默认构造函数:
-
类A内定义了虚函数:
因为类A有了虚函数后,它就是一个虚类,会维护一个虚函数表(vftable),编译器生成A的构造函数是为了类A的所有实例都能初始化这个虚函数表的指针(vfptr) -
以上三种情况的复合使用。
例如:类A使用了虚继承:
class A: public virtual C{}
了解虚继承机制的读者应该不会陌生,这张表叫虚基类表,它记录了类继承的所有的虚基类子对象在本类定义的对象内的偏移位置(至于虚继承机制的实现,我们以后详细探讨)。为了保证虚继承机制的正确工作,对象必须在初始化阶段维护一个指向该表的一个指针,称为虚表指针(vbptr)。编译器因为它提供A的默认构造函数的理由和虚函数时类似。
再比如,类A的成员b对应的类B没有人工定义默认构造函数,但是类B的成员c对应的类C有人工定义默认构造函数。
c++什么时候会生成默认构造函数
c++什么时候会生成默认构造函数
更正:上述4点总结其实是错的。正确的详细说法看cppreferencfe上原版的 Default constructors 。简单说就是,只要没有写=deleted,你的class定义即使没有自行实现默认构造函数,编译器也会帮你偷偷的实现一个空体、空初始化列表的构造函数。
8. C++编译器不报warning,但仍然有UB的一个例子
#include <stdio.h>
#include <iostream>
#include <string>
using namespace std;
class Blob {
public:
int age;
void hello() { printf("hello
"); }
};
void test_case() {
Blob a;
a.hello(); //(1)
cout << a.age << endl;
}
int main() {
test_case();
return 0;
}
在VS2017中:
如果注释掉(1),会编译报错说“变量a没有初始化”;开启(1)则编译链接通过。结果输出垃圾值。
但如果换成g++(ideone在线编译的,ubuntu系统?g++-8?)或者llvm(macOS下的g++),编译链接都没有错误。macOS下即使开启了-Wall也仍然没有报错,甚至开启-Wpedantic也是什么错误都没输出。
9. 虚析构函数(virtual destructor)和动态绑定
virtual的意思是虚拟的,C++的OOP中的virtual用于“多态”。普通成员函数的多态比较好理解,但是析构函数为啥也要用virtual来修饰呢?
所谓动态绑定,就是说用基类指针指向派生类对象。如果此时指向的是new出来的空间上的对象,而没有使用virtual析构函数,那么派生类的析构函数就不会被调用,也就不是真的“动态绑定”了。
样例代码:
#include <iostream>
#include <string>
using namespace std;
class Base {
public:
~Base() {
cout << "Base()" << endl;
}
};
class Derived: public Base {
public:
Derived(): name_(new string("NULL")) {}
Derived(const string& n): name_(new string(n)) {}
~Derived() {
delete name_;
cout << "~Derived(): name_ has been deleted." << endl;
}
private:
string* name_;
};
int main() {
Base* base[2] = {
new Derived(),
new Derived("Bob")
};
for (int i = 0; i < 2; i++) {
delete base[i];
}
return 0;
}
如上所示,因为没有使用virtual析构函数,导致没有调用Derive类的析构函数,造成name_指向的内存没有被释放(内存泄漏)。其实不仅是内存泄漏,还有可能有其他问题,包括文件句柄没有关闭、没有上锁等等。
10. explict关键字,用于单参数构造函数
C++中的explicit关键字只能用于修饰只有一个参数的类构造函数, 它的作用是表明该构造函数是显示的, 而非隐式的.
explicit关键字只需用于类内的单参数构造函数前面。由于无参数的构造函数和多参数的构造函数总是显示调用,这种情况在构造函数前加explicit无意义。
google的c++规范中提到explicit的优点是可以避免不合时宜的类型变换,缺点无。所以google约定所有单参数的构造函数都必须是显示的,只有极少数情况下拷贝构造函数可以不声明称explicit。例如作为其他类的透明包装器的类。
effective c++中说:被声明为explicit的构造函数通常比其non-explicit兄弟更受欢迎。因为它们禁止编译器执行非预期(往往也不被期望)的类型转换。除非我有一个好理由允许构造函数被用于隐式类型转换,否则我会把它声明为explicit,鼓励大家遵循相同的政策。
11. unique_ptr和shared_ptr的使用
因为没怎么用过,主要看这两篇博客的讲解,很详细。
C++ 智能指针 unique_ptr 详解与示例
C++ 智能指针 shared_ptr 详解与示例
12. 虚函数和纯虚函数
概括起来就这么几条:
- 在类成员方法的声明(不是定义)语句前面加个单词:virtual,她就会摇身一变成为虚函数。
- 在虚函数的声明语句末尾中加个 =0 ,她就会摇身一变成为纯虚函数。
- 子类可以重新定义基类的虚函数,我们把这个行为称之为复写(override)。
- 不管是虚函数还是纯虚函数,基类都可以为提供他们的实现(implementation),如果有的话子类可以调用基类的这些实现。
- 子类可自主选择是否要提供一份属于自己的个性化虚函数实现。
- 子类必须提供一份属于自己的个性化纯虚函数实现。
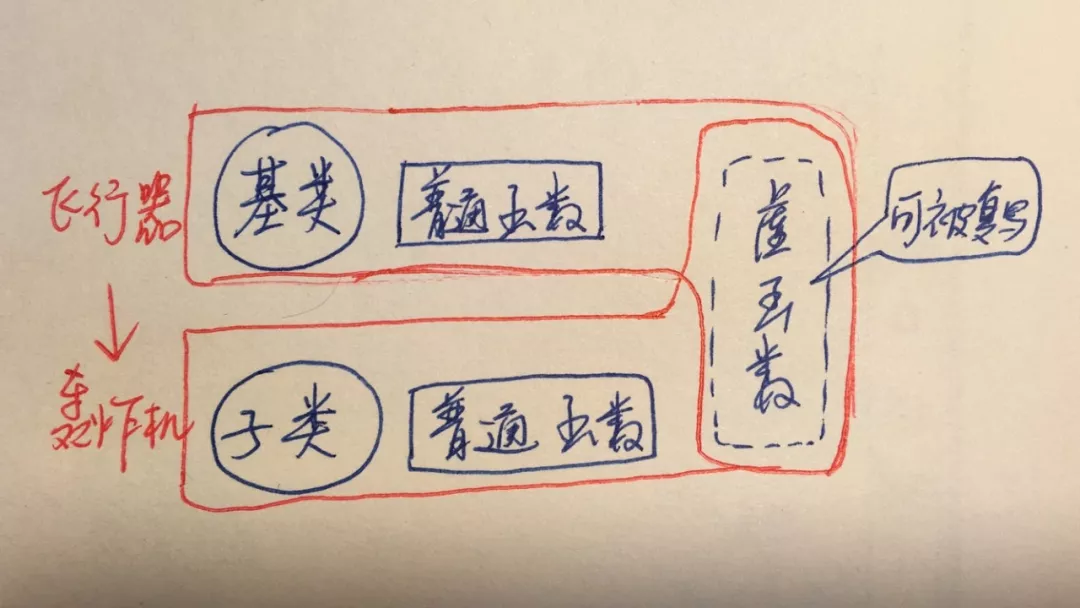
第一,当基类的某个成员方法,在大多数情形下都应该由子类提供个性化实现,但基类也可以提供一个备选方案的时候,请将其设计为虚函数。例如飞行器的加油动作,每种不同的飞行器原则上都应该有自己的个性化的加充然后的方式,但也不免可以有一种通用的然后和加充方式。
第二,当基类的某个成员方法,必须由子类提供个性化实现的时候,请将其设计为纯虚函数。例如飞行器的飞行动作,逻辑上每种飞行器都必须提供为其特殊设计的个性化飞行行为,而不应该有任何一种“通用的飞行方式”。
第三,使用一个基类类型的指针或者引用,来指向子类对象,进而调用经由子类复写了的个性化的虚函数,这是C++实现多态性的一个最经典的场景。
第四,基类提供的纯虚函数的实现版本,并非为了多态性考虑,因为指向子类对象的基类指针和引用无法调用该版本。纯虚函数在基类中的实现跟多态性无关,它只是提供了一种语法上的便利,在变化多端的应用场景中留有后路。
第五,虚函数和普通的函数实际上是存储在不同的区域的,虚函数所在的区域是可被覆盖(也称复写override)的,每当子类定义相同名称的虚函数时就将原来基类的版本给覆盖了,另一侧面也说明了为什么基类中声明的虚函数在后代类中不需要另加声明一律自动为虚函数,因为它所存储的位置不会发生改变。而普通函数的存储区域不会覆盖,每个类都有自己独立的区域互不相干。
13. enum class类型
enum类型是枚举类型,可以整型提升,可以直接使用对应的值而不需要作用域限定符,因此如果两个枚举类定义中有同样变量名则冲突;
enum class相当于强类型的枚举类型,不能直接做整型提升(实在需要,static_cast<int>()可用),需要使用类名作用域限定符来使用,因而两个enum class定义中同样的变量名不会冲突;
14. =default修饰的构造函数声明
从C++11起,可以使用=default来给构造函数“赋值”。作用:
- 编译器自动生成对应的构造函数,避免程序员手工去实现
- 生成的构造函数,不仅仅是空函数体
{}这么简单:生成的构造函数会对成员变量做初始化。 - 随着copy/move constructore的出现,也出现了很多复杂的规则,使用
=default和=delete会简化(避免接触使用?)这些规则,让事情更简单。
举例:
#include <iostream>
using namespace std;
class A
{
public:
int x;
A(){}
};
class B
{
public:
int x;
B()=default;
};
int main()
{
int x = 5;
new(&x)A(); // Call for empty constructor, which does nothing
cout << x << endl;
new(&x)B; // Call for default constructor
cout << x << endl;
new(&x)B(); // Call for default constructor + Value initialization
cout << x << endl;
return 0;
}
输出:
5
5
0
其中的语法说明:
would you please explain this syntax -> new(&x)A();
We are creating new object in the memory started from address of variable x (instead of new memory allocation). This syntax is used to create object at pre-allocated memory. As in our case the size of B = the size of int, so new(&x)A() will create new object in the place of x variable.
The new syntax “= default” in C++11
15. VS2017报错,变量dv::size_t不是类型名
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
namespace dv {
template<typename _Tp, size_t fixed_size = 1024 / sizeof(_Tp) + 8> class AutoBuffer >
{
public:
AutoBuffer();
explicit AutoBuffer(size_t size);
};
}
代码如上,是在自定义的namespace中,发现用到了size_t类型不识别。(第一个编译报错)。
然而,这个问题并不是std::size_t可以解决的。
实际上是因为AutoBuffer的后面多了一个>,但是第一个编译报错居然不是>。>的报错在第二个:

教训:涉及模板或其他C++相关的内容时,编译报错,不一定是看第一个,有可能是第二个。
16. VS2017的Intellisence和编译器,明显不是同一个东西
测试代码:
#include <iostream>
#include <string>
#include <vector>
#include <fstream>
#include <list>
#include <algorithm>
#define IMPL_2 1
#if IMPL_2
template<typename T>
T* find_value(const std::vector<T>& data, const T& value) //这里,cosnt修饰了data,应该去掉,才能保证编译正确。
{
for (int i = 0; i < data.size(); i++)
{
if (data[i] == value) {
return &data[i]; //这里,编译会报错。但是编辑器里面并不显示错误。intelligence/intellicode辣鸡。
}
}
}
#endif
void find_value_test()
{
std::vector<int> data = { 1, 4, 2, 5, 9, 0, 6 };
int value = 5;
int* p = find_value(data, value);
if (p != NULL) {
std::cout << "found value " << value << " in data vector. Its pointer is " << p << std::endl;
}
else {
std::cout << "not found value " << value << " in data vector" << std::endl;
}
}
17. static局部变量无法设断点吗?为什么?
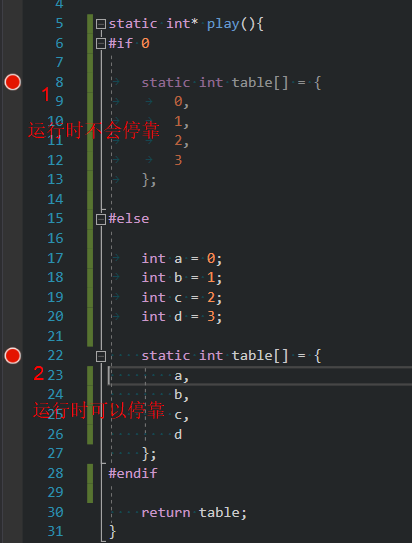
如图,分成两种情况。case1,用常量赋值。static变量肯定是在内存的常量区的。
变量存储在常量区意味着:变量的生命周期是整个可执行程序的周期,而不是单次函数调用之内;只不过是出了函数就没有访问权限而已了。
而下断点的条件是,在变量初始化之前。很明显,程序一旦启动,static局部变量就初始化了,因此case1是“断点下晚了”。
补充说明:进程的内存可以换分为:
- 静态区:例如static变量,全局变量
- 动态区,包括堆,栈
case2:因为是用局部变量a,b,c,d来初始化,a~d是在函数运行时才“活着”,因此可以下断点。
18. 读取中文名(UTF-8编码)文件或内容失败
典型的场景是,Windows下读取含有中文的txt文件,或从txt文件中读取含有中的一行/字符串:如果源码(.cpp)文件是UTF-8,并且txt也是UTF-8的,很可能提示“打不开文件”等报错。why?
首先要肯定一点,代码文件、txt文件,都用UTF-8了,这是非常值得肯定的,提供了统一格式。要怪也就怪Windows系统和Visual Studio吧,对UTF-8的支持还是不够好。
但是代码还是要写,数据还是要处理;而且希望是代码能在Linux/Windows下都用同一套,不要每次都手动去处理编解码问题。那就统一用utf8_to_ok()函数做转换。样例代码:
#include <stdio.h>
#include <iostream>
#include <string>
#ifdef _MSC_VER
#include <Windows.h>
#endif
string utf8_to_ok(const char* str)
{
#ifdef _MSC_VER
string result;
WCHAR *strSrc;
LPSTR szRes;
int i = MultiByteToWideChar(CP_UTF8, 0, str, -1, NULL, 0);
strSrc = new WCHAR[i + 1];
MultiByteToWideChar(CP_UTF8, 0, str, -1, strSrc, i);
i = WideCharToMultiByte(CP_ACP, 0, strSrc, -1, NULL, 0, NULL, NULL);
szRes = new CHAR[i + 1];
WideCharToMultiByte(CP_ACP, 0, strSrc, -1, szRes, i, NULL, NULL);
result = szRes;
delete[]strSrc;
delete[]szRes;
return result;
#else
string result(str);
return result;
#endif
}
static void dump_str(const string& str) {
for (int i = 0; i < str.size(); i++) {
//printf("%02x ", str[i]);
printf("%02X ", (unsigned char)str[i]);
}
cout << endl;
}
int main() {
string str = "口罩.txt";
dump_str(str);
str = utf8_to_ok(str.c_str());
ifstream fin(str);
if (!fin.is_open()) {
fprintf(stderr, "failed to open file %s in line %d
", str.c_str(), __LINE__);
}
else {
while (getline(fin, str)) {
cout << utf8_to_ok(str.c_str()) << endl;
}
}
fin.close();
return 0;
}
解释:
- Windows MSVC平台,ifstream, getline等函数,不支持UTF-8(或者说不是完整支持UTF-8)
- Windows MSVC平台:源文件应当使用UTF-8,txt文件应当使用UTF-8,
utf8_to_ok()转换string对象为GB编码格式。 - Linux/MacOSX平台,
utf8_to_ok()把string复制一份返回,性能可能轻微有影响
19. VS可执行程序无法执行
问题是出现在编译运行一个很老很老的代码(08年的),用的VC6.0,编译0error,但是运行不起来。
随后尝试用VS2013升级工程打开,终于看到友好一点的消息了,是因为链接的输出(xxx.exe)和TargetPath的值(xxxx.exe),所在的绝对路径不一致。
而这种不一致,导致了根本没有xxx.exe生成。改成一致后,程序可以运行了。
20. Dism++清理C盘后,VS2013的工程显示不可用
大概是Windows10升级导致的。
重装了nuget插件后好了。

21. 非法内存地址,无法用nullptr检查出来
例如地址为0x00000001,明显是非法地址(NULL区,x86 windows的前64KB范围内);会进入else分支导致crash。
int test4() {
int* data = (int*)0x00000001;
if (data == nullptr) {
cout << "data is nullptr" << endl;
}
else {
cout << "data is not nullptr" << endl;
cout << data[0] << endl;
}
return 0;
}
22. VS错误C1071,“在注释中遇到意外的文件结束”
写中文注释并非不可取,但是应该确保:
- .cpp/.h文件是UTF-8编码格式
/**/内的注释,应当确保英文字符和*挨着,而不应该让中文字符和*挨着
例如:
/* 这是一段好的注释 */
/* 这个注释也还可以.*/
/*这个注释则很糟糕*/
举例:在复制基于重载算法的内存泄漏检测和内存越界检测一文的代码时,VS2017运行报错了。。
参考:“在注释中遇到意外的文件结束”--记一个令人崩溃的bug
23. GCC/G++和GLIBCXX版本对照关系
GNU官方提供了对照表,到里面搜GLIBCXX即可:https://gcc.gnu.org/onlinedocs/libstdc++/manual/abi.html
当然,上述表格略显粗糙。还是针对自己手中的各种文件做检查吧:
ubuntu16.04, GCC/G++-5.4
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21 | grep 'GLIBCXX'
输出:
GLIBCXX_3.4
GLIBCXX_3.4.1
GLIBCXX_3.4.2
GLIBCXX_3.4.3
GLIBCXX_3.4.4
GLIBCXX_3.4.5
GLIBCXX_3.4.6
GLIBCXX_3.4.7
GLIBCXX_3.4.8
GLIBCXX_3.4.9
GLIBCXX_3.4.10
GLIBCXX_3.4.11
GLIBCXX_3.4.12
GLIBCXX_3.4.13
GLIBCXX_3.4.14
GLIBCXX_3.4.15
GLIBCXX_3.4.16
GLIBCXX_3.4.17
GLIBCXX_3.4.18
GLIBCXX_3.4.19
GLIBCXX_3.4.20
GLIBCXX_3.4.21
GLIBCXX_DEBUG_MESSAGE_LENGTH
再来看一下gcc/g++-4.9的C++标准库(之前为了搞SNPE装的):
(base) arcsoft-43% strings /usr/lib/gcc/x86_64-linux-gnu/4.9/libstdc++.so | grep 'GLIBCXX'
GLIBCXX_3.4
GLIBCXX_3.4.1
GLIBCXX_3.4.2
GLIBCXX_3.4.3
GLIBCXX_3.4.4
GLIBCXX_3.4.5
GLIBCXX_3.4.6
GLIBCXX_3.4.7
GLIBCXX_3.4.8
GLIBCXX_3.4.9
GLIBCXX_3.4.10
GLIBCXX_3.4.11
GLIBCXX_3.4.12
GLIBCXX_3.4.13
GLIBCXX_3.4.14
GLIBCXX_3.4.15
GLIBCXX_3.4.16
GLIBCXX_3.4.17
GLIBCXX_3.4.18
GLIBCXX_3.4.19
GLIBCXX_3.4.20
GLIBCXX_3.4.21
GLIBCXX_DEBUG_MESSAGE_LENGTH
24.注意第二处报错
编译报错,习惯了找第一个报错。今天又遇到一个,第二次报错才是真正的错因。个人的lufter项目,在VS2017下编译运行良好,utils.cmake也没有查出来“忘记包含stddef.h”的情况下(用于找size_t类的定义),linux下报错:

25. 标准库的头文件在哪里?
VS2017,在E:softMicrosoft Visual Studio2017CommunityVCToolsMSVC14.16.27023include
Ubuntu G++,在/usr/include/c++/5
26. 在C++代码中尽量不要用纯C的头文件
来举一个例子说明问题的严重性:abs()函数的参数和返回值,可以是什么类型?
math.h对应C标准库,只能是int abs(int x),也就是参数和返回值必须是int类型,传入float或double类型的参数会报错(VS2017验证)。
cmath对应C++标准库,提供的abs()函数在C标准库的基础上(因为cmath包含了math.h),新增了如下重载函数:
// <stdlib.h> has abs(long) and abs(long long)
_Check_return_ inline double abs(_In_ double _Xx) noexcept
{
return (_CSTD fabs(_Xx));
}
_Check_return_ inline float abs(_In_ float _Xx) noexcept
{
return (_CSTD fabsf(_Xx));
}
_Check_return_ inline long double abs(_In_ long double _Xx) noexcept
{
return (_CSTD fabsl(_Xx));
}
因此可以在C++中包含了cmath的情况下,使用abs(3.14)这样的表达式。
进一步在VS2013下进行了验证,发现并不报错。。如果你还在用VS2013,那么看到本案例你应该考虑换一下了

而为什么VS2013里可以用abs(double)呢?因为在math.h中利用extern C++给出了C++重载函数实现:
