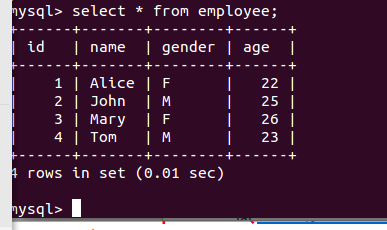
今天主要学习实验五中编程实现利用DataFrame读写Mysql的数据。
(1) 在 MySQL 数据库中新建数据库 sparktest,新建表 employee,插入两行数据
配置Spark通过jdbc来连接mysql数据库进行读写操作。
插入如表 6-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。

打包运行遇到之前同样问题: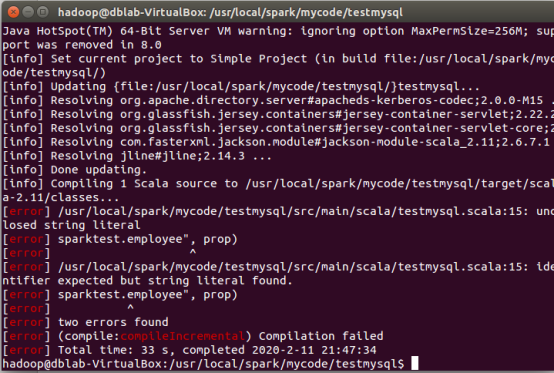
同样是利用spark-shell一行一行的来运行程序
注:进行spark-shell交互式编程的时候,需要通过
bin/spark-shell --jars /usr/local/spark/jars/mysql-connector-java-5.1.44-bin.jar mysql连接的jar包开打shell,否则会因找不到此jar包而连接数据库失败
源代码:
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
object TestMySQL {
def main(args: Array[String]) {
val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("gender", StringType, true),StructField("age",IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p(0).toInt,p(1).trim, p(2).trim,p(3).toInt))
val employeeDF = spark.createDataFrame(rowRDD, schema)
val prop = new Properties()
prop.put("user", "****")
prop.put("password", "***********")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest",
sparktest.employee", prop)
val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "***********").load()
jdbcDF.agg("age" -> "max", "age" -> "sum")
} }