简绍
应用程序和系统日志可以帮助我们了解集群内部的运行情况,日志对于我们调试问题和监视集群情况也是非常有用的。而且大部分的应用都会有日志记录,对于传统的应用大部分都会写入到本地的日志文件之中。对于容器化应用程序来说则更简单,只需要将日志信息写入到 stdout 和 stderr 即可,容器默认情况下就会把这些日志输出到宿主机上的一个 JSON 文件之中,同样也可以通过 docker logs 或者 kubectl logs 来查看到对应的日志信息。
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。Elasticsearch 通常与 Kibana 一起部署。
Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
Fluentd是一个流行的开源数据收集器,我们将在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
拓扑图

ps: 因为我的物理机资源有限,并且还要在集群中部署myweb、prometheus、jenkins等,所以这里我只部署EFK,正常情况,这套方案也足够使用了。
配置启动一个可扩展的 Elasticsearch 集群,然后在 Kubernetes 集群中创建一个 Kibana 应用,最后通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。
检查集群状态
ceph集群
# ceph -s
cluster:
id: ed4d59da-c861-4da0-bbe2-8dfdea5be796
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum bs-k8s-harbor,bs-k8s-gitlab,bs-k8s-ceph
mgr: bs-k8s-ceph(active), standbys: bs-k8s-harbor, bs-k8s-gitlab
osd: 6 osds: 6 up, 6 in
data:
pools: 1 pools, 128 pgs
objects: 92 objects, 285 MiB
usage: 6.7 GiB used, 107 GiB / 114 GiB avail
pgs: 128 active+clean
原因:这是因为未在池上启用应用程序。
解决:
# ceph osd lspools
6 webapp
# ceph osd pool application enable webapp rbd
enabled application 'rbd' on pool 'webapp'
# ceph -s
......
health: HEALTH_OK
kubernetes集群
# kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6cf5b744d7-rxt86 1/1 Running 0 47h
kube-system calico-node-25dlc 1/1 Running 2 2d4h
kube-system calico-node-49q4n 1/1 Running 2 2d4h
kube-system calico-node-4gmcp 1/1 Running 1 2d4h
kube-system calico-node-gt4bt 1/1 Running 1 2d4h
kube-system calico-node-svcdj 1/1 Running 1 2d4h
kube-system calico-node-tkrqt 1/1 Running 1 2d4h
kube-system coredns-76b74f549-dkjxd 1/1 Running 0 47h
kube-system dashboard-metrics-scraper-64c8c7d847-dqbx2 1/1 Running 0 46h
kube-system kubernetes-dashboard-85c79db674-bnvlk 1/1 Running 0 46h
kube-system metrics-server-6694c7dd66-hsbzb 1/1 Running 0 47h
kube-system traefik-ingress-controller-m8jf9 1/1 Running 0 47h
kube-system traefik-ingress-controller-r7cgl 1/1 Running 0 47h
myweb rbd-provisioner-9cf46c856-b9pm9 1/1 Running 1 7h2m
myweb wordpress-6677ff7bd-sc45d 1/1 Running 0 6h13m
myweb wordpress-mysql-6d7bd496b4-62dps 1/1 Running 0 5h51m
# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
20.0.0.201 563m 14% 1321Mi 103%
20.0.0.202 359m 19% 1288Mi 100%
20.0.0.203 338m 18% 1272Mi 99%
20.0.0.204 546m 14% 954Mi 13%
20.0.0.205 516m 13% 539Mi 23%
20.0.0.206 375m 9% 1123Mi 87%
创建namespace
这里我准备将所有efk放入assembly名称空间下。 assembly:组件
# vim namespace.yaml
[root@bs-k8s-master01 efk]# pwd
/data/k8s/efk
[root@bs-k8s-master01 efk]# cat namespace.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: namespace.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: v1
kind: Namespace
metadata:
name: assembly
创建动态RBD StorageClass
创建assembly pool
bs-k8s-ceph
# ceph osd pool create assembly 128
pool 'assembly' created
# ceph auth get-or-create client.assembly mon 'allow r' osd 'allow class-read, allow rwx pool=assembly' -o ceph.client.assemply.keyring
创建Storageclass
bs-k8s-master01
# ceph auth get-key client.assembly | base64
QVFBWjIzRmVDa0RnSGhBQWQ0TXJWK2YxVThGTUkrMjlva1JZYlE9PQ==
# cat ceph-efk-secret.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: ceph-jenkins-secret.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: v1
kind: Secret
metadata:
name: ceph-admin-secret
namespace: assembly
data:
key: QVFBaUptcGU0R3RDREJBQWhhM1E3NnowWG5YYUl1VVI2MmRQVFE9PQ==
type: kubernetes.io/rbd
---
apiVersion: v1
kind: Secret
metadata:
name: ceph-assembly-secret
namespace: assembly
data:
key: QVFBWjIzRmVDa0RnSGhBQWQ0TXJWK2YxVThGTUkrMjlva1JZYlE9PQ==
type: kubernetes.io/rbd
# kubectl apply -f ceph-efk-secret.yaml
secret/ceph-admin-secret created
secret/ceph-assembly-secret created
# cat ceph-efk-storageclass.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: ceph-jenkins-storageclass.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ceph-efk
namespace: assembly
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: ceph.com/rbd
reclaimPolicy: Retain
parameters:
monitors: 20.0.0.205:6789,20.0.0.206:6789,20.0.0.207:6789
adminId: admin
adminSecretName: ceph-admin-secret
adminSecretNamespace: assembly
pool: assembly
fsType: xfs
userId: assembly
userSecretName: ceph-assembly-secret
imageFormat: "2"
imageFeatures: "layering"
# kubectl apply -f ceph-efk-storageclass.yaml
storageclass.storage.k8s.io/ceph-efk created
ceph rbd和kubernetes结合需要第三方插件
# cat external-storage-rbd-provisioner.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: external-storage-rbd-provisioner.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: v1
kind: ServiceAccount
metadata:
name: rbd-provisioner
namespace: assembly
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-provisioner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["services"]
resourceNames: ["kube-dns"]
verbs: ["list", "get"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-provisioner
subjects:
- kind: ServiceAccount
name: rbd-provisioner
namespace: assembly
roleRef:
kind: ClusterRole
name: rbd-provisioner
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: rbd-provisioner
namespace: assembly
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: rbd-provisioner
namespace: assembly
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: rbd-provisioner
subjects:
- kind: ServiceAccount
name: rbd-provisioner
namespace: assembly
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: rbd-provisioner
namespace: assembly
spec:
replicas: 1
selector:
matchLabels:
app: rbd-provisioner
strategy:
type: Recreate
template:
metadata:
labels:
app: rbd-provisioner
spec:
containers:
- name: rbd-provisioner
image: "harbor.linux.com/rbd/rbd-provisioner:latest"
imagePullPolicy: IfNotPresent
env:
- name: PROVISIONER_NAME
value: ceph.com/rbd
imagePullSecrets:
- name: k8s-harbor-login
serviceAccount: rbd-provisioner
nodeSelector: ## 设置node筛选器,在特定label的节点上启动
rbd: "true"
# kubectl apply -f external-storage-rbd-provisioner.yaml
serviceaccount/rbd-provisioner created
clusterrole.rbac.authorization.k8s.io/rbd-provisioner unchanged
clusterrolebinding.rbac.authorization.k8s.io/rbd-provisioner configured
role.rbac.authorization.k8s.io/rbd-provisioner created
rolebinding.rbac.authorization.k8s.io/rbd-provisioner created
deployment.apps/rbd-provisioner created
# kubectl get pods -n assembly
NAME READY STATUS RESTARTS AGE
rbd-provisioner-9cf46c856-6qzll 1/1 Running 0 71s
创建Elasticsearch
创建elasticsearch-svc.yaml
定义了一个名为 elasticsearch 的 Service,指定标签app=elasticsearch,当我们将 Elasticsearch StatefulSet 与此服务关联时,服务将返回带有标签app=elasticsearch的 Elasticsearch Pods 的 DNS A 记录,然后设置clusterIP=None,将该服务设置成无头服务。最后,我们分别定义端口9200、9300,分别用于与 REST API 交互,以及用于节点间通信。
# cat elasticsearch-svc.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: elasticsearch-svc.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: assembly
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
# kubectl apply -f elasticsearch-svc.yaml
service/elasticsearch created
已经为 Pod 设置了无头服务和一个稳定的域名.elasticsearch.assmbly.svc.cluster.local,接下来通过 StatefulSet 来创建具体的 Elasticsearch 的 Pod 应用.
Kubernetes StatefulSet 允许为 Pod 分配一个稳定的标识和持久化存储,Elasticsearch 需要稳定的存储来保证 Pod 在重新调度或者重启后的数据依然不变,所以需要使用 StatefulSet 来管理 Pod。
创建动态pv
# cat elasticsearch-pvc.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-18
#FileName: elasticsearch-pvc.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ceph-elasticsearch
namespace: assembly
labels:
app: elasticsearch
spec:
storageClassName: ceph-efk
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
#kubectl apply -f ceph-efk-storageclass.yaml
# cat elasticsearch-statefulset.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: elasticsearch-storageclass.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: assembly
spec:
serviceName: elasticsearch
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
imagePullSecrets:
- name: k8s-harbor-login
containers:
- name: elasticsearch
image: harbor.linux.com/efk/elasticsearch-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
# - name: discovery.zen.ping.unicast.hosts
# value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
# - name: discovery.zen.minimum_master_nodes
# value: "2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumes:
- name: data
persistentVolumeClaim:
claimName: ceph-elasticsearch
nodeSelector: ## 设置node筛选器,在特定label的节点上启动
elasticsearch: "true"
节点打标签
# kubectl label nodes 20.0.0.204 elasticsearch=true
node/20.0.0.204 labeled
# kubectl apply -f elasticsearch-statefulset.yaml
# kubectl get pods -n assembly
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 2m15s
rbd-provisioner-9cf46c856-6qzll 1/1 Running 0 37m
Pods 部署完成后,我们可以通过请求一个 REST API 来检查 Elasticsearch 集群是否正常运行。使用下面的命令将本地端口9200转发到 Elasticsearch 节点(es-cluster-0)对应的端口
# kubectl port-forward es-cluster-0 9200:9200 --namespace=assembly
Forwarding from 127.0.0.1:9200 -> 9200
# curl http://localhost:9200/_cluster/state?pretty
{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 234,
"cluster_uuid" : "PopKT5FLROqyBYlRvvr7kw",
"version" : 2,
"state_uuid" : "ubOKSevGRVe4iR5JXODjDA",
"master_node" : "vub5ot69Thu8igd4qeiZBg",
"blocks" : { },
"nodes" : {
"vub5ot69Thu8igd4qeiZBg" : {
"name" : "es-cluster-0",
"ephemeral_id" : "9JjNmdOyRomyYsHAO1IQ5Q",
"transport_address" : "172.20.46.85:9300",
"attributes" : { }
}
},
创建Kibana
Elasticsearch 集群启动成功了,接下来可以来部署 Kibana 服务,新建一个名为 kibana.yaml 的文件。
# cat kibana.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: kibana.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: assembly
labels:
app: kibana
spec:
ports:
- port: 5601
type: NodePort
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: assembly
labels:
app: kibana
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
imagePullSecrets:
- name: k8s-harbor-login
containers:
- name: kibana
image: harbor.linux.com/efk/kibana-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
nodeSelector: ## 设置node筛选器,在特定label的节点上启动
kibana: "true"
节点打标签
# kubectl label nodes 20.0.0.204 kibana=true
node/20.0.0.204 labeled
# kubectl apply -f kibana.yaml
service/kibana created
deployment.apps/kibana created
# kubectl get pods -n assembly
NAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 8m4s
kibana-598987f498-k8ff9 1/1 Running 0 70s
rbd-provisioner-9cf46c856-6qzll 1/1 Running 0 43m
定义了两个资源对象,一个 Service 和 Deployment,为了测试方便,我们将 Service 设置为了 NodePort 类型,Kibana Pod 中配置都比较简单,唯一需要注意的是我们使用 ELASTICSEARCH_URL 这个环境变量来设置Elasticsearch 集群的端点和端口,直接使用 Kubernetes DNS 即可,此端点对应服务名称为 elasticsearch,由于是一个 headless service,所以该域将解析为 Elasticsearch Pod 的 IP 地址列表
# kubectl get svc --namespace=assembly
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 50m
kibana NodePort 10.68.123.234 <none> 5601:22693/TCP 2m22s
代理kibana
这里我让kibana走traefik代理
# cat kibana-ingreeroute.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: kibana-ingreeroute.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: kibana
namespace: assembly
spec:
entryPoints:
- web
routes:
- match: Host(`kibana.linux.com`)
kind: Rule
services:
- name: kibana
port: 5601
# kubectl apply -f kibana-ingreeroute.yaml
ingressroute.traefik.containo.us/kibana created

traefik代理成功,本地主机hosts解析
web访问成功!
创建Fluentd
Fluentd是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以这里使用 Fluentd 来作为日志收集工具。
工作原理
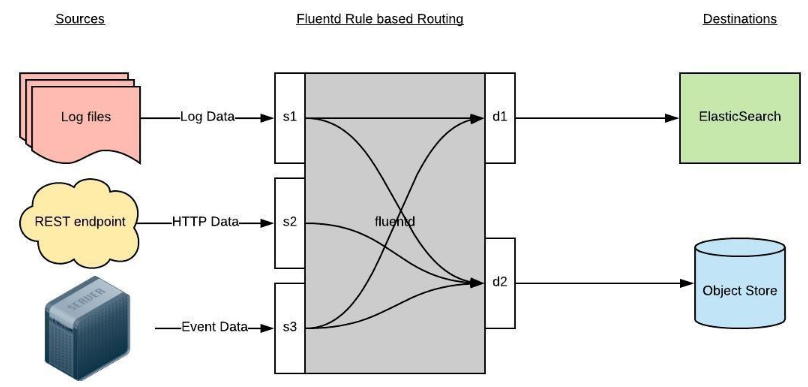
Fluentd 通过一组给定的数据源抓取日志数据,处理->转换成结构化的数据格式将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下:
首先 Fluentd 从多个日志源获取数据
结构化并且标记这些数据
然后根据匹配的标签将数据发送到多个目标服务去
Fluentd拓扑图
配置
通过一个配置文件来告诉 Fluentd 如何采集、处理数据的
日志源配置
比如这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag raw.kubernetes.*
format json
read_from_head true
</source>
上面配置部分参数说明如下:
- id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
- type:Fluentd 内置的指令,
tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据。 - path:
tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。 - pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
- tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置
上面是日志源的配置,接下来看看如何将日志数据发送到 Elasticsearch:
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
type_name fluentd
host "#{ENV['OUTPUT_HOST']}"
port "#{ENV['OUTPUT_PORT']}"
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"
queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"
overflow_action block
</buffer>
- match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成
**。 - id:目标的一个唯一标识符。
- type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
- log_level:指定要捕获的日志级别,我们这里配置成
info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。 - host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
- logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为
true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。 - Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,这样,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。
首先,通过 ConfigMap 对象来指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件。
# cat fluentd-configmap.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: fluentd-configmap.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: assembly
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host elasticsearch
port 9200
logstash_format true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
# kubectl apply -f fluentd-configmap.yaml
configmap/fluentd-config created
上面配置文件中配置了 docker 容器日志目录以及 docker、kubelet 应用的日志的收集,收集到数据经过处理后发送到 elasticsearch:9200 服务。
然后新建一个 fluentd-daemonset.yaml 的文件
# cat fluentd-daemonset.yaml
##########################################################################
#Author: zisefeizhu
#QQ: 2********0
#Date: 2020-03-13
#FileName: fluentd-daemonset.yaml
#URL: https://www.cnblogs.com/zisefeizhu/
#Description: The test script
#Copyright (C): 2020 All rights reserved
###########################################################################
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: assembly
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: assembly
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: assembly
labels:
k8s-app: fluentd-es
version: v2.0.4
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.0.4
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.0.4
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: fluentd-es
imagePullSecrets:
- name: k8s-harbor-login
containers:
- name: fluentd-es
image: harbor.linux.com/efk/fluentd-elasticsearch:v2.0.4
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /data/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-config
nodeSelector: ## 设置node筛选器,在特定label的节点上启动
fluentd: "true"
节点打标签
# kubectl apply -f fluentd-daemonset.yaml
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s.io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created
daemonset.apps/fluentd-es created
# kubectl label nodes 20.0.0.204 fluentd=true
node/20.0.0.204 labeled
# kubectl label nodes 20.0.0.205 fluentd=true
node/20.0.0.205 labeled
# kubectl label nodes 20.0.0.206 fluentd=true
node/20.0.0.206 labeled
# kubectl get pods -n assembly -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
es-cluster-0 1/1 Running 0 30m 172.20.46.85 20.0.0.204 <none> <none>
fluentd-es-5fgt7 1/1 Running 0 5m36s 172.20.46.87 20.0.0.204 <none> <none>
fluentd-es-l22nj 1/1 Running 0 5m22s 172.20.145.9 20.0.0.205 <none> <none>
fluentd-es-pnqk8 1/1 Running 0 5m18s 172.20.208.29 20.0.0.206 <none> <none>
kibana-598987f498-k8ff9 1/1 Running 0 23m 172.20.46.86 20.0.0.204 <none> <none>
rbd-provisioner-9cf46c856-6qzll 1/1 Running 0 65m 172.20.46.84 20.0.0.204 <none> <none>

前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,这里只需要在文本框中输入logstash-*即可匹配到 Elasticsearch pod中的所有日志数据,然后点击下一步,进入以下页面:
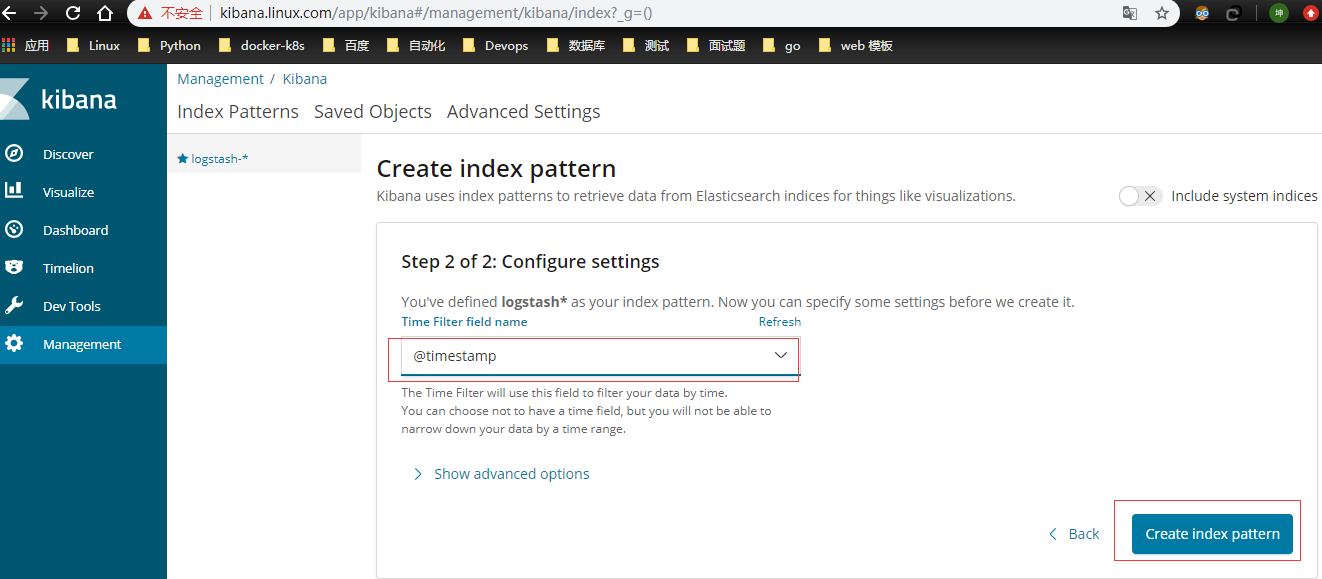
在该页面中配置使用哪个字段按时间过滤日志数据,在下拉列表中,选择@timestamp字段,然后点击Create index pattern,创建完成后,点击左侧导航菜单中的Discover,然后就可以看到一些直方图和最近采集到的日志数据了

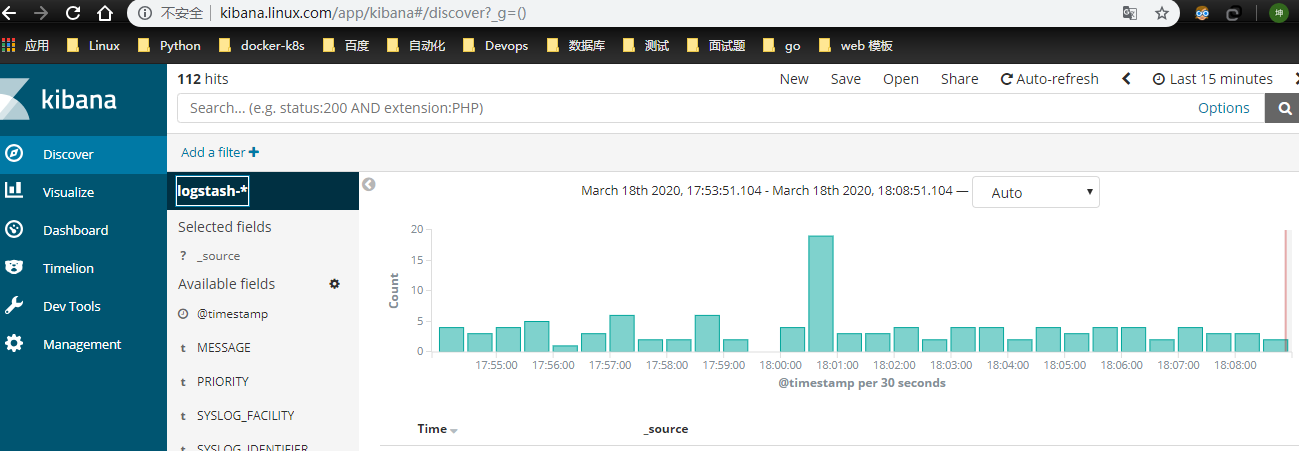
至此完成了efk的部署
启动池
# ceph osd pool application enable assembly rbd
enabled application 'rbd' on pool 'assembly'