Some people prefer count(1) over count(*) and using count(1) to optimize his statements, but actually they have not difference.
Here is test code and data(using the TRAN for execute more speed only):
BEGIN TRAN
CREATE TABLE TestCount(C1 VARCHAR(400),C2 VARCHAR(300),C3 VARCHAR(150) NOT NULL,C4 VARCHAR(80),C5 VARCHAR(38) NOT NULL,C6 INT) DECLARE @COUNT INT =1 SET NOCOUNT ON WHILE @COUNT<=1500000 BEGIN INSERT TestCount SELECT NEWID(),NEWID(),NEWID(),NEWID(),NEWID(),@COUNT SET @COUNT=@COUNT+1 END
commit
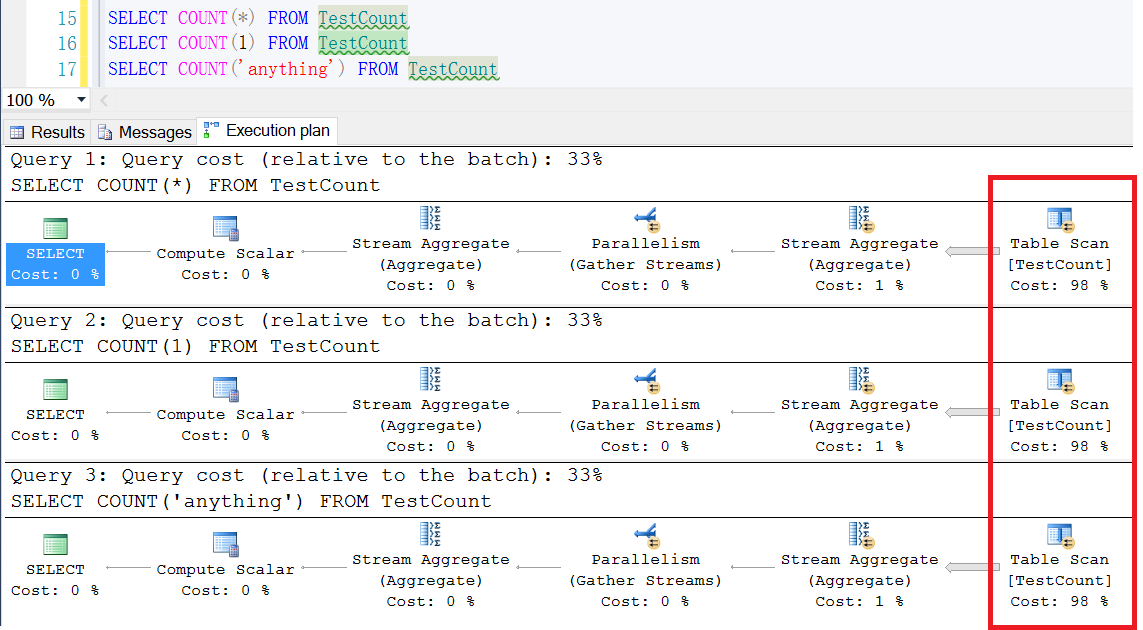
As to count(1),count(*),count('anything'), they are the same about results and execultion plan(it used "table scan", because the table is heap)
As to count(column)
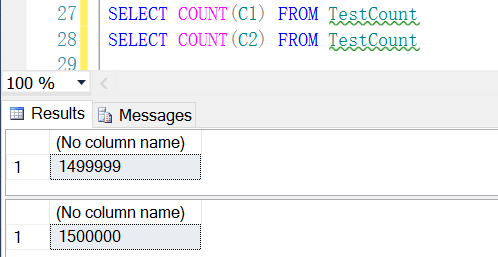
It noly count the rows of is not null for the columns:
UPDATE TOP (1) TestCount SET c1 =NULL
How to execute count(*) of execution engine
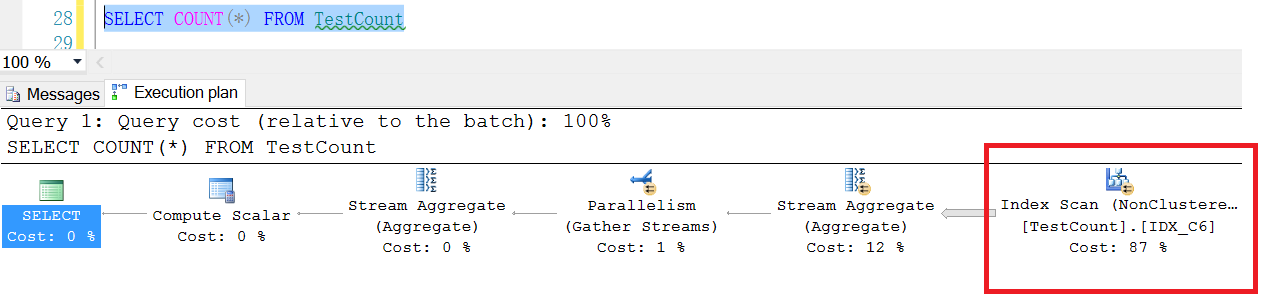
Execution engine will use a have index's column to count count(*)(if the table have index), of cause, for performance reasons, engine will prefer the narrowest index.
CREATE NONCLUSTERED INDEX IDX_C5 ON TestCount(C5)

add a index in C6(the column type is int, is 4 bytes)
CREATE NONCLUSTERED INDEX IDX_C6 ON TestCount(C6)
Engine used more narrow index to count.
comparison of count(wide index column), count(narrow index column) and count(no index column)
CREATE NONCLUSTERED INDEX IDX_C2 ON TestCount(C2)
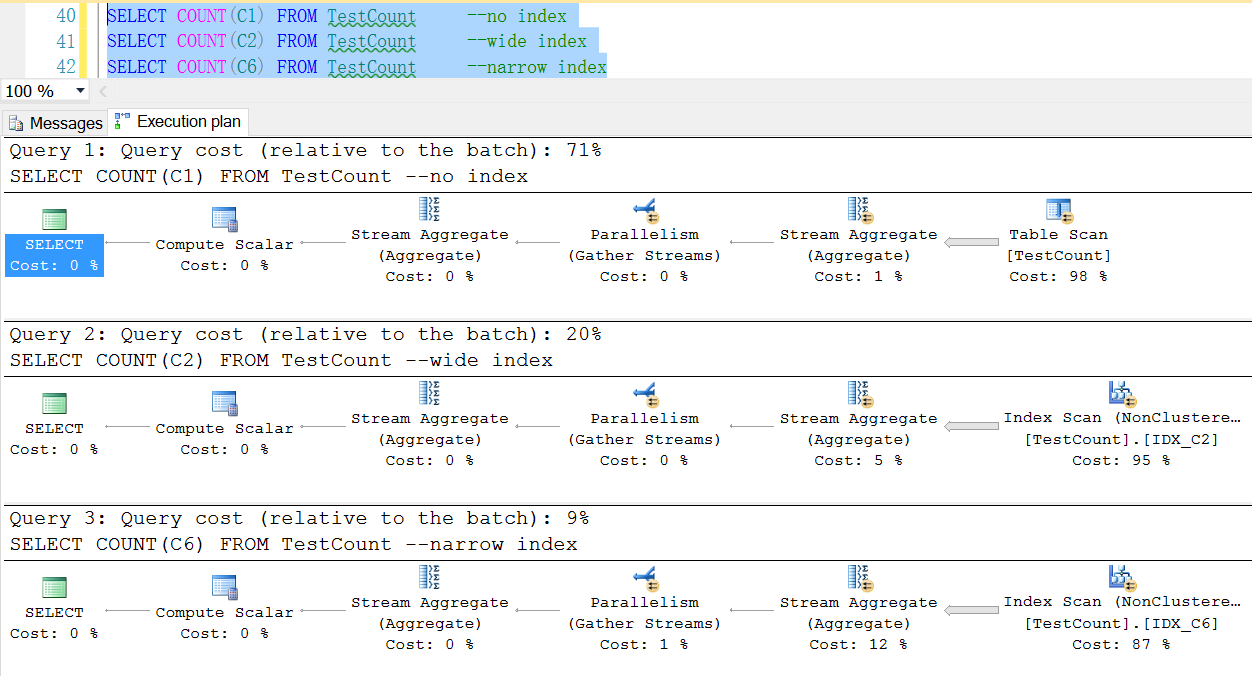
So, count(no index column) performance is poor and index the more narrow the better, the performance more batter too.
Now, we will compare more detail between count(1) and count(*), we already know their "query cost" is same and the table has 3 index: C2/C5/C6
Scan page is same and IO cast is same too
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT COUNT(1) FROM TestCount SET STATISTICS IO OFF SET STATISTICS TIME OFF ------------------------ PRINT 'NEXT plan' ------------------------ SET STATISTICS IO ON SET STATISTICS TIME ON SELECT COUNT(*) FROM TestCount SET STATISTICS IO OFF SET STATISTICS TIME OFF
