1 简介
- BERT全称Bidirectional Enoceder Representations from Transformers,即双向的Transformers的Encoder。是谷歌于2018年10月提出的一个语言表示模型(language representation model)。
1.1 创新
- 预训练方法(pre-trained):
- 用Masked LM学习词语在上下文中的表示;
- 用Next Sentence Prediction来学习句子级表示。
1.2 成功
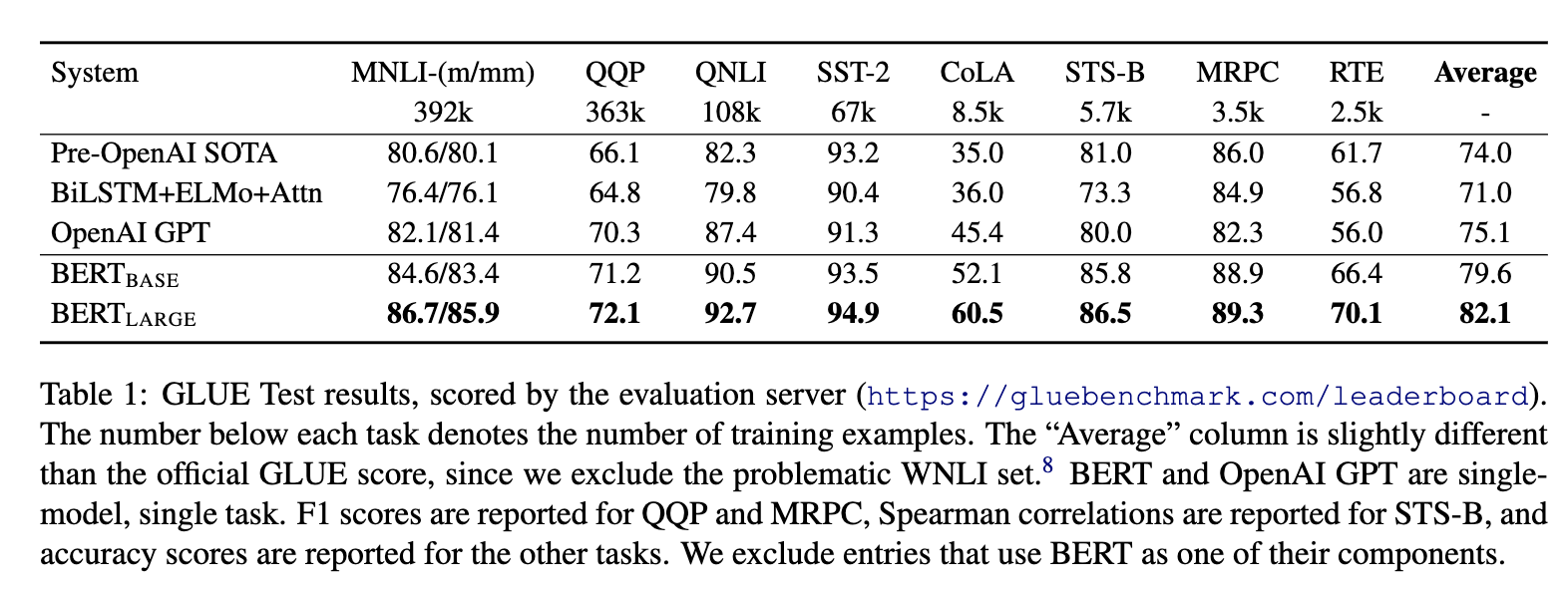
- 强大,效果好。出来之时,在11种自然语言处理任务上霸榜。
2 模型
2.1 基本思想
-
Bert之前的几年,人们通过DNN对语言模型进行“预训练”,得到词向量,然后在一些下游NLP任务(问题回答,自然语言推断,情感分析等)上进行了微调,取得了很好的效果。
-
对于下游任务,通常并不是直接使用预训练的语言模型,而是使用语言模型的副产物--词向量。实际上,预训练语言模型通常是希望得到“每个单词的最佳上下文表示”。如果每个单词只能看到自己“左侧的上下文”,显然会缺少许多语境信息。因此需要训练从右到左的模型。这样,每个单词都有两个表示形式:从左到右和从右到左,然后就可以将它们串联在一起以完成下游任务了。
-
综上,从直觉上讲,如果可以训练一个高度双向的语言模型,那将非常棒。
2.2 建模目标
可以和同是双向的ELMo对比一下:
- ELMo:
- (P(w_i|w_1, w_2, ..., w_{i-1})) 和 (P(w_i|w_{i+1}, w_{i+2},...,w_n))作为目标函数,独立训练处两个representation然后拼接。
- BERT的目标函数:
- (P(w_i|w_1, ..., w_{i-1}, w_{i+1},...,w_n))以此训练LM。
2.3 词嵌入(Embedding)
-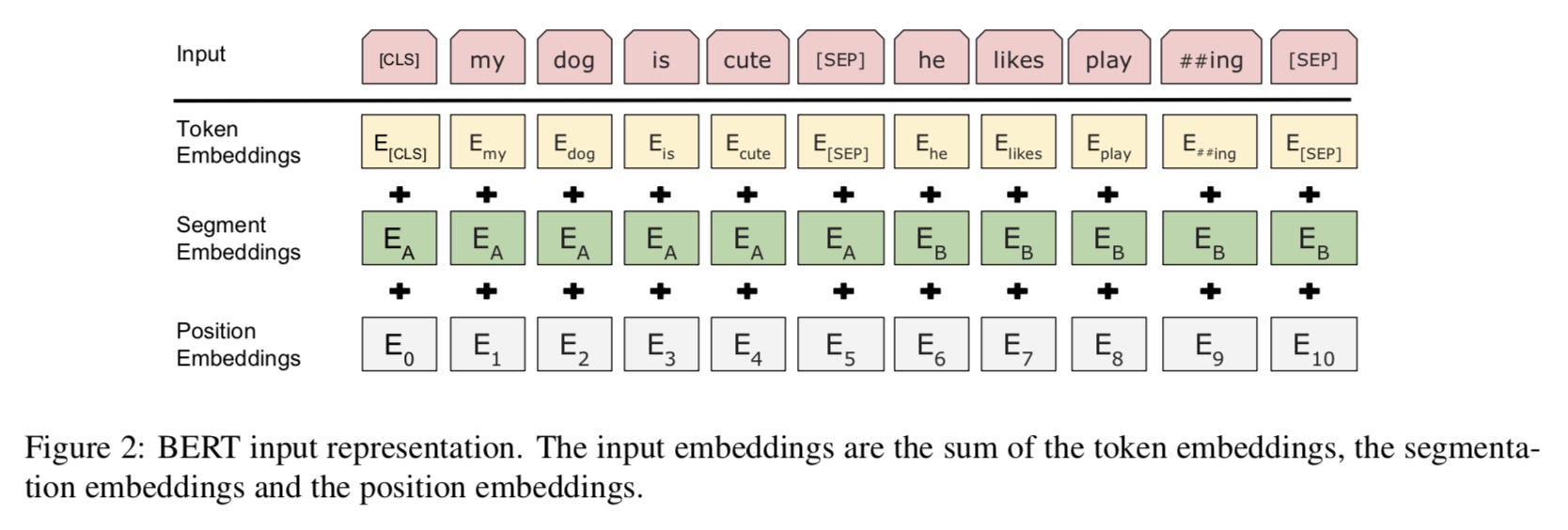
- Bert的Embedding由三种Embedding求和而成。
2.3.1 Token Embeddings
- token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。
- 输入文本在送入token embeddings 层之前要先进行tokenization处理。 假设输入文本是:”my dog is cute he likes playing“, 会将两个特殊的token会插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。这两个token为后面的分类任务和划分句子对服务的。
- tokenization使用的方法是WordPiece tokenization. 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”(此处不详细展开)。使用WordPiece tokenization让BERT在处理英文文本的时候仅需要存储30,522 个词,而且很少遇到oov的词。
- 经过处理,上述句子被转换成”[CLS] my dog is cute [SEP] he likes play ##ing [SEP]“, 也就是11个token。这样,例子中的7个词的句子就转换成了11个token, 然后接着得到了一个(11, 768) 的矩阵或者是(1, 11, 768)的张量(如果考虑batch_size的话)。这就是Token Embeddings 层。
2.3.2 Segment Embeddings
- 用来区别两种句子,预训练除了LM,还需要做判断两个句子先后顺序的分类任务。
- 前一个句子的每个token都用0表示,后一个句子的每个token都用1表示。如”[CLS] my dog is cute [SEP] he likes play ##ing [SEP]“ 表示成”0 0 0 0 0 0 1 1 1 1 1“。 如果输入仅仅只有一个句子,那么它的segment embedding就是全0。 这也是一个(11, 768)维的向量。
2.3.3 Position Embeddings
- 这和Transformer的Position Embeddings不一样,在Transformer中使用的是公式法, 在bert中是通过训练得到的。加入position embeddings会让BERT理解”I think, therefore I am“中的第一个 “I” 和第二个 “I”应该有着不同的向量表示。
- BERT能够处理最长512个token的输入序列。论文作者通过让BERT在各个位置上学习一个向量表示来讲序列顺序的信息编码进来。这意味着Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,表的第一行是代表第一个序列的第一个位置,第二行代表序列的第二个位置,以此类推。因此,如果有这样两个句子“Hello world” 和“Hi there”, “Hello” 和“Hi”会由完全相同的position embeddings,因为他们都是句子的第一个词。同理,“world” 和“there”也会有相同的position embedding。
2.3.4 合成
- 长度为n的输入序列将获得的三种不同的向量表示,分别是:
- Token Embeddings, (1, n, 768) ,词的向量表示
- Segment Embeddings, (1, n, 768),辅助BERT区别句子对中的两个句子的向量表示
- Position Embeddings ,(1, n, 768) ,让BERT学习到输入的顺序属性
- 这些表示会被按元素相加,得到一个大小为(1, n, 768)的合成表示。这一表示就是BERT编码层的输入了。
2.4 预训练任务(Pre-training Task)
2.4.1 Task 1: Masked LM
-
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被mask的原单词。最终的损失函数只计算被mask掉那个token。
-
如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,具体的MASK是有trick的:
-
随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。作者没有说明什么原因,应该是基于实验效果?
-
要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
-
训练技巧:序列长度太大(512)会影响训练速度,所以90%的steps都用seq_len=128训练,余下的10%步数训练512长度的输入。
-
具体实现注意:
- i) 在encoder的输出上添加一个分类层。
- ii) 用嵌入矩阵乘以输出向量,将其转换为词汇的维度。
- iii) 用softmax计算词汇表中每个单词的概率。
-
BERT的损失函数只考虑了mask的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
2.4.2 Task 2: Next Sentence Prediction
- LM存在的问题是,缺少句子之间的关系,这对许多NLP任务很重要。为预训练句子关系模型,bert使用一个非常简单的二分类任务:将两个句子A和B链接起来,预测原始文本中句子B是否排在句子A之后。
- 具体训练的时候,50%的输入对在原始文档中是前后关系,另外50%中是从语料库中随机组成的,并且是与第一句断开的。
- 为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
- 在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
- 将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上,即前文说的Segment Embeddings。
- 给每个token添加一个位置embedding,来表示它在序列中的位置。
- 为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
- 整个输入序列输入给 Transformer 模型用一个简单的分类层将[CLS]标记的输出变换为 2×1 形状的向量。
- 用 softmax 计算 IsNextSequence 的概率
- 在训练BERT模型时,Masked LM和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
2.5 微调(Fine-tunning)
- 对于不同的下游任务,我们仅需要对BERT不同位置的输出进行处理即可,或者直接将BERT不同位置的输出直接输入到下游模型当中。具体的如下:
- 对于情感分析等单句分类任务,可以直接输入单个句子(不需要[SEP]分隔双句),将[CLS]的输出直接输入到分类器进行分类
- 对于句子对任务(句子关系判断任务),需要用[SEP]分隔两个句子输入到模型中,然后同样仅须将[CLS]的输出送到分类器进行分类
- 对于问答任务,将问题与答案拼接输入到BERT模型中,然后将答案位置的输出向量进行二分类并在句子方向上进行softmax(只需预测开始和结束位置即可)
- 对于命名实体识别任务,对每个位置的输出进行分类即可,如果将每个位置的输出作为特征输入到CRF将取得更好的效果。
- 对于常规分类任务中,需要在 Transformer 的输出之上加一个分类层
3 优缺点
3.1 优点
- 效果好,横扫了11项NLP任务。bert之后基本全面拥抱transformer。微调下游任务的时候,即使数据集非常小(比如小于5000个标注样本),模型性能也有不错的提升。
3.2 缺点
作者在文中主要提到的就是MLM预训练时的mask问题:
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
- BERT的预训练任务MLM使得能够借助上下文对序列进行编码,但同时也使得其预训练过程与中的数据与微调的数据不匹配,难以适应生成式任务
- BERT没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计
- 由于最大输入长度的限制,适合句子和段落级别的任务,不适用于文档级别的任务(如长文本分类)
4 参考文献
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 11 Oct 2018 (v1), last revised 24 May 2019 (v2)
- https://www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/
- https://zhuanlan.zhihu.com/p/46652512
- https://mc.ai/why-bert-has-3-embedding-layers-and-their-implementation-details/