Server端处理fetchRequest请求
1前言
在consumer章节,我们知道,在consumer的pollOnce()中调用sendFetches()方法,
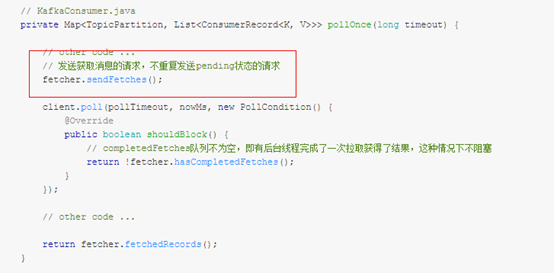
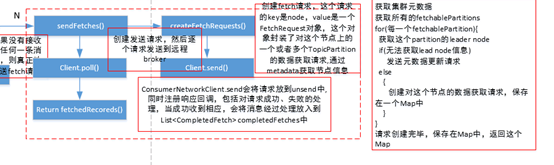
本节主要介绍服务端处理fetchRequest请求的过程,FetchRequest由服务端函数KafkaApis.handleFetchRequest处理, FetchReuqest中重要的字段是requestInfo: Map[TopicAndPartition, PartitionFetchInfo])
即对于Fetch请求来说,关注点是TopicAndParititon执行Fetch的offset以及FetchSize。
其实Kafka的主从同步也是通过FetchRequest来完成,与consumer拉取消息的过程相似,都在handleFetchRequest()中进行处理,不过broker对他们的处理在身份验证上做了区分,下面我们看具体的FetchRequest处理过程:
2 handleFetchRequest()处理过程
该函数的源码如下:



在函数的开头部分
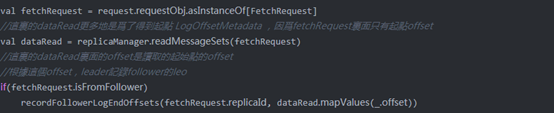
先是执行readMessageSets读取了log上当前可读的数据,这个数据量如果已经满足了Fetch的条件的话,后面会直接返回。之后会判断Fetch是否是来自于Follower的同步请求,如果是,则会调用recordFollowerLogEndOffsets记录Follower的offset。
该函数会调用ReplicaManager.updateReplicaLEOAndPartitionHW:
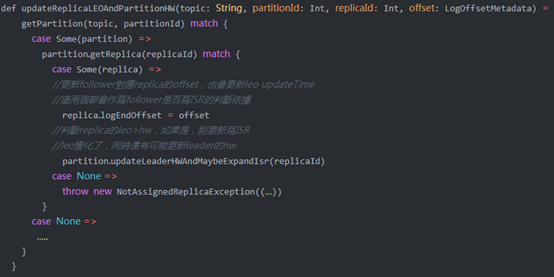
虽然执行的代码量很少,但recordFollowerLogEndOffsets带来的影响很大:
- l 根据Fetch读到的message的offset代表了follower的leo,所以replica中的logEndOffsetMetadata和logEndOffsetUpdateTimeMsValue变量会更新;
- l replicaManager.maybeShrinkIsr函数作为一个定期任务,会根据replica的logEndOffsetMetadata和logEndOffsetUpdateTimeMsValue变量清理ISR,将leo落后太多或者长时间没更新的replica从ISR中踢出;
- l replica的leo更新,如果满足条件leo > leaderHw,则该replica有可能会成为ISR中的一员,并更新zk中的ISR记录。
- l 如果replica本来就是ISR,leo更新意味着leaderHw也有可能会发生变化。
- l 在requiredAcks>1或者=-1时,DelayedProduce请求所需条件与replica是否满足leo>requiredOffset有关,所以需要调用producerRequestPurgatory.update;
- l 如果FetchRequest不想等待,或者已经读到了足够的数据,FetchRequest会直接使用已经读到的数据进行返回。
- l 否则,会执行如下代码:
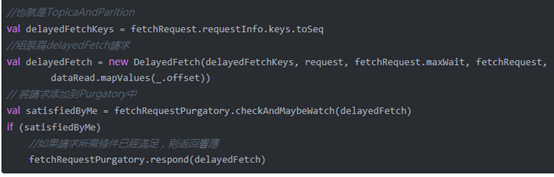
这里和ProducerRequest一样,将FetchRequest组装为DelayedFetch并加入到Purgatory中。
如果不是来自replica的请求,调用ReplicaManager.fetchMessages()方法,从本地副本中获取数据,并等待足够多的数据进行返回,其中传入的responseCallback方法在超时或者是满足fetch条件时将会被调用,将结果返回给客户端。
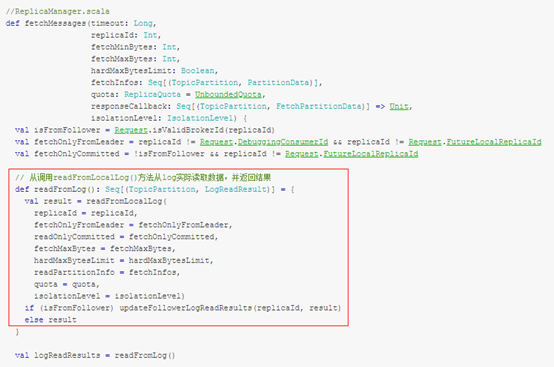

整体来说,分为以下几步:
- l readFromLocalLog():调用该方法,从本地日志拉取相应的数据;
- l 判断 Fetch 请求来源,如果来自副本同步,那么更新该副本的 the end offset 记录,如果该副本不在 isr 中,并判断是否需要更新 isr;
- l 返回结果,满足条件的话立马返回,否则的话,通过延迟操作,延迟返回结果。


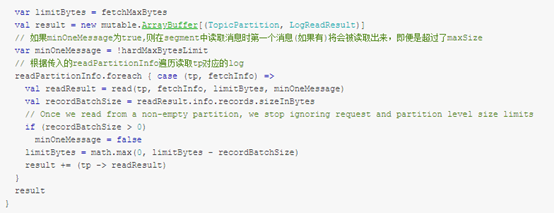
readFromLocalLog() 方法的处理过程:
- l 先根据要拉取的 topic-partition 获取对应的 Partition 对象,根据 Partition 对象获取对应的 Replica 对象;
- l 根据 Replica 对象找到对应的 Log 对象,然后调用其 read() 方法从指定的位置读取数据。
存储层对 Fetch 请求的处理
每个 Replica 会对应一个 log 对象,而每个 log 对象会管理相应的 LogSegment 实例。
Log 对象的 read() 方法的实现如下所示:

从实现可以看出,该方法会先查找对应的 Segment 对象(日志分段),然后循环直到读取到数据结束,如果当前的日志分段没有读取到相应的数据,那么会更新日志分段及对应的最大位置。读取日志分段时,会先读取 offset 索引文件再读取数据文件,具体步骤如下:
- l 根据要读取的起始偏移量(startOffset)读取 offset 索引文件中对应的物理位置;
- l 查找 offset 索引文件最后返回:起始偏移量对应的最近物理位置(startPosition);
- l 根据 startPosition 直接定位到数据文件,然后读取数据文件内容;
- l 最多能读到数据文件的结束位置(maxPosition)。
LogSegment
关乎 数据文件、offset 索引文件和时间索引文件真正的操作都是在 LogSegment 对象中的,日志读取也与这个方法息息相关。
read() 方法的实现如下:
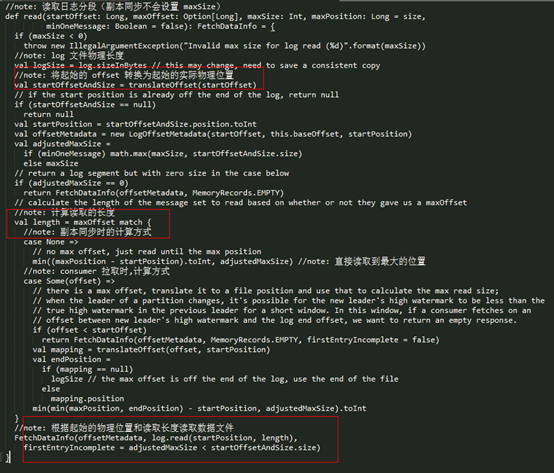
从上面的实现来看,上述过程分为以下三部分:
- l 根据 startOffset 得到实际的物理位置(translateOffset());
- l 计算要读取的实际物理长度;
- l 根据实际起始物理位置和要读取实际物理长度读取数据文件。
translateOffset()
translateOffset() 方法的实现过程主要分为两部分:
- l 查找 offset 索引文件:调用 offset 索引文件的
lookup()查找方法,获取离 startOffset 最接近的物理位置; - l 调用数据文件的
searchFor()方法,从指定的物理位置开始读取每条数据,知道找到对应 offset 的物理位置。
参考资料: