由于最近做图片爬取项目,涉及到网页中图片信息的选择,所以边做边学了点皮毛,有自己的心得
百度图库是ajax加载的,所以解析json数据即可
hjsons = json.loads(response.body) img_datas = hjsons['data'] if hjsons: for data in img_datas: try: item = Bd_Item() #print(data['fromPageTitleEnc']) #print(data['thumbURL']) item['img_url'] = data['thumbURL'] item['img_title'] = data['fromPageTitleEnc'] item['width'] = data['width'] item['height'] = data['height'] yield item except: pass
千图网抠图是分页加载
http://588ku.com/sucai/0-default-0-0-yueliang-0-1/
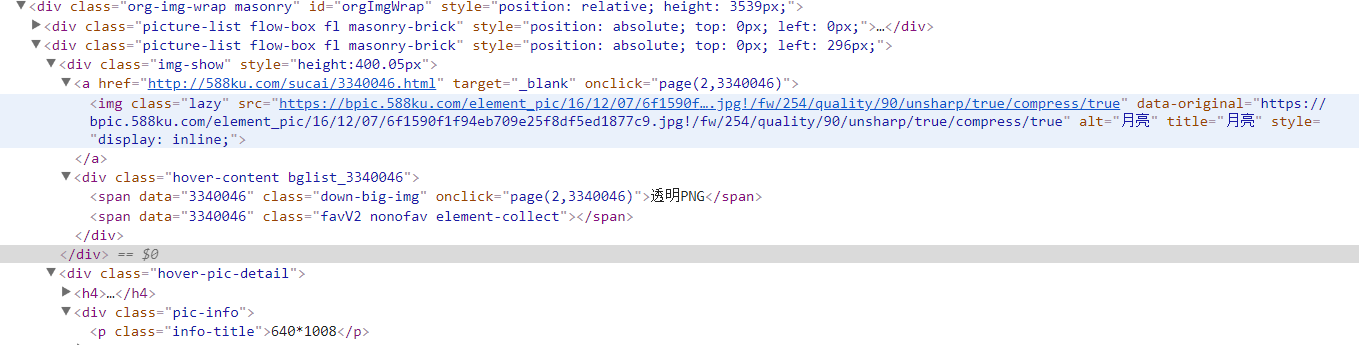
qt_imgs = response.css('.org-img-wrap .picture-list') for qt_img in qt_imgs: try: item = Qt_Item() img_url = qt_img.css('.img-show .lazy::attr(data-original)').extract_first() title = qt_img.css('.img-show .lazy::attr(title)').extract_first() size = qt_img.css('.hover-pic-detail .pic-info .info-title::text').extract_first() #width = re.findall(r'(.*?)*',size).extract_first() #height = re.findall(r'*(.*?)', size).extract_first() #print(width) #print(height) #time.sleep(10) item['qtimg_url'] = img_url item['qtimg_title'] = title item['size'] = size #item['width'] = width #item['height'] = height yield item except: pass
觅元素和千图网差不多,但是选取图片链接有技巧,千图网图片可以看到有两个图片链接,其中data-original这个链接不同处理即可,但是如果选src会发现,选取出来的链接都是一样的,而且当你打开链接时发现黑色一片,我感觉这是种保护吧,但只有这一种链接该怎么办呢,于是我用正则去选择,结果发现,抓取结果中有两条链接,而第一条是无用的,第二条才是有用的,它的名字是data-src,这就好办了,只需要把src改成data-src即可成功选取。

mys_imgs = response.css('.content-wrap .w1200 .f-content .i-flow-item') for mys_img in mys_imgs: try: item = Mys_Item() img_url = mys_img.css('.img-out-wrap .img-wrap img::attr(data-src)').extract_first() title = mys_img.css('.img-out-wrap .img-wrap img::attr(alt)').extract_first() size = mys_img.css('.i-title-wrap a::text').extract_first() size_detail = re.findall(r'((.*?))',size) #text = mys_img.css('.img-wrap .lazy').extract_first() # time.sleep(10) #img_url = re.findall(r'src="(.*?)!/fw/260/quality/90/unsharp/true/compress/true"', text) #width = re.findall(r'(.*?)x', size_detail).extract_first() #height = re.findall(r'x(.*?)', size_detail).extract_first() item['mysimg_url'] = img_url item['mysimg_title'] = title item['size'] = size_detail #item['width'] = width #item['height'] = height yield item except: pass
这东西有点意思,需要琢磨,以后用到再慢慢学吧