如果你有好的想法,欢迎讨论!
1 Application of Transfer Learning in Continuous Time Series for Anomaly Detection in Commercial Aircraft Flight Data
https://ieeexplore.ieee.org/document/8513709
论文开始介绍了用于处理时间序列的两个主要的模型RNN和LSTM,同时介绍了什么是迁移学习
一 迁移学习的方法
1 基于样例的迁移学习(instance-based transfer-learning )
这种方法以重新加权的方式重用目标域中源域中的部分数据。在这种情况下,实例重新加权和重要性抽样是两种主要的技术。
2 基于特征的迁移学习( feature-representation-transfer method)
这种方法是在源域中不断学习,从数据中提取好的特征,然后以代码的形式迁移到目标域中。 使用新的特征表示,目标任务的性能有望显著提高。
3 参数迁移
当模型建立时,它假定源域和目标域之间的一些参数是相同的。在迁移过程中,这些参数只需要直接从源域复制到目标域集,通过发现共享的参数或先验,就可以跨任务传递知识。
4 关系迁移
这种方法比较抽象。在机器学习领域中,各个领域的要素都会呈现出一定的关系,而对这些关系的充分理解可以帮助我们建立更好的模型。关系-知识-转移方法是指在具有相似关系结构的两个领域之间转移对这种关系的理解。
例如:老板和员工之前开会的关系和老师与学生上课的关系有相似之处,这种关系可以迁移。
二 三类迁移学习
1 归纳迁移学习:在这类任务中,无论源域和目标域是否相同,目标任务都与源任务(Ts ≠Tt)不同。
2 直推式迁移学习:在这个类别中,目标域不同于源域(Ds≠ DT),而它们的任务是相同的(TS=TT)
3 非监督迁移学习:就像归纳转移学习一样,任务与源任务不同,但又相关。
时间序列问题不同于分类问题。它变化较大,时间序列标签的特征空间不像分类问题那么有限(图相识别属于分类问题)。它需要在源域中构建和训练一个模型,潜在的数据更改存储在权重中。
三 试验
数据集是 商用飞机飞行数据
1 将连续时间序列转换为监督学习数据(这个我的博客有提),规范化数据集。
2 建立LSTM和全连接层的训练模型
3 训练出一个比较好的模型,保存权重把它用于目标域。
4 使用较少的数据集来训练这个模型,获得最终的迁移模型。
四 模型的评估
结果表明使用迁移学习后使用少量的训练集和相同的迭代次数时的准确性要高于没有使用迁移学习的模型,并且可以从损失函数的曲线看出。
五 总结
迁移学习的确可以提高准确性和减少时间的消耗,但是它的使用要求也有限制,有的时候反而会适得其反,目前为止我看到的迁移学习用于时间序列的论文,大多使用LSTM,GRU模型,在相似时间序列中的迁移。似乎看上去整体的步骤相似,没有突破之处。他们的研究往往仅限于表面,并没有深入的研究数据,我认为迁移学习的运用应该更加广泛,那么可以从细化时间序列上,或者通过变换,现在有个大致方向。
2 Transfer learning for time series classification
代码:github.com/hfawaz/bigdata18
论文:https://arxiv.org/pdf/1811.01533.pdf
作者提出转移学习很少应用于时间序列数据的深度学习模型。这种缺失的原因之一可能是缺少一个大型通用数据集,像图片迁移现在就有一个通用的模型VGG16,它包括了1000多种图片种类,而且训练的准确性也十分高,我们大可以在这个模型的基础进行迁移学习,但是对于复杂多变的时间序列时间,没有一个通用的模型,还有,图片在抽象层中大致就像26个字母一样,有统一的集合来构成五彩缤纷的图片。
这篇论文要比上一张更加深入
1 使用DTW来比较时间序列之间的相似性(DTW博客有提到)
2 使用CNN模型,迁移时对最后一层softmax层进行替换
3 对于时间序列集,作者使用DBA算法把时间序列集合进行压缩(本博客有提到)
4 作者在评估结果的过程中,用于可视化方法,分析结果,发现迁移学习在相似的数据集之间表现的更好,而不相似的数据集则有相反的效果。
补充:
通常来说,用传统的机器学习方法(例如KNN、DTW)进行时间序列分类能取得比较好的效果。但是,基于深度网络的时间序列分类往往在大数据集上能够打败传统方法。另一方面,深度网络必须依赖于大量的训练数据,否则精度也无法超过传统机器学习方法。在这种情况下,进行数据增强、收集更多的数据、实用集成学习模型,都是提高精度的方法。这其中,迁移学习也可以被用在数据标注不路的情况。
从深度网络本身来看,有研究者注意到了,针对时间序列数据,深度网络提取到的特征,与CNN一样,具有相似性和继承性。因此,作者的假设就是,这些特征不只是针对某一数据集具有特异性,也可以被用在别的相关数据集。这就保证了用深度网络进行时间序列迁移学习的有效性。
Method
基本方法与在图像上进行深度迁移一致:先在一个源领域上进行pre-train,然后在目标领域上进行fine-tune。
然而,与图像领域有较多的经典网络结构可选择不同,时间序列并没有一个公认的经典网络架构。因此,作者为了保证迁移的效果不会太差,选择了之前研究者提出的一种全卷积网络(FCN,Fully Convolutional Neural Network)。这种网络已经在之间的研究中被证明具有较高的准确性和鲁棒性。
网络的结构如下图所示。网络由3个卷积层、1个全局池化层、和1个全连接层构成。使用全连接层的好处是,在进行不同输入长度序列的fine-tune时,不需要再额外设计池内化层。

与图像的区别就是,输入由图片换成了时间序列。注意到,图片往往具有一定的通道数(如常见的R、G、B三通道);时间序列也有通道:即不同维的时间序列数据。最简单的即是1维序列,可以认为是1个通道。多维时间序列则可以认为是多个通道。
网络迁移适配
Fine-tune的基本方法就是,不改变除softmax层以外的层的结构,只改变softmax层的构造。例如,预训练好的网络可能是一个分5类的网络,而目标领域则是一个10类的分类问题。这时候,就需要改变预训练网络的softmax层,使之由原来的5层变为10层,以适应目标领域的分类。
因此,源领域和目标领域的网络相比,除最后一层外,其他都相同。当然,相同的部分,网络权重也相同。
作者对整个网络都在目标领域上进行了fine-tune,而不是只fine-tune最后一层。因为以往的研究标明,在整个网络上进行fine-tune,往往会比只fine-tune某些层效果好。
选择合适的源领域:数据集间相似性
在进行迁移学习前,一个重要的问题就是:给定一个目标域,如何选择合适的源领域?如果选择的源域与目标域相似性过小,则很可能造成负迁移。
度量时间序列相似性的另一个问题是,如何度量不同维度的时间序列的相似性。作者提出把多维时间序列规约成每类由一维序列构成,然后利用DTW(Dynamic Time Warping)来度量两个时间序列的相似性。
在进行规约时,作者利用了之间研究者提出的DTW Barycenter Averaging (DBA)方法进行了时间序列的规约。
经过规约后,两个数据集便可度量相似性。
然而,这种方法具有很大的局限性。例如,它没有考虑到数据集内部不同维度之间的关联性。作者自己也承认这种方法不够好,但是由于他们的主要关注点是如何迁移,因此,并未在这个方面多做文章。
经过相似度计算,可以针对 个数据集,得到一个
的相似性矩阵。此矩阵表示了不同数据集之间的相似度。相似度高的两个数据集,迁移效果最好。
Experiments
作者利用了UCI机器学习仓库中的85个时间序列分类数据集,构建了7140对迁移学习任务。为了进行如此大量的实验,他们用了来自英伟达的60个GPU。(只想说,有钱真好)
实验非常充分。这里简要说一下一些结论:
- 利用迁移往往效果比不迁移好,并且,几乎不会对原来的网络产生负面作用。
- 同一个目标域,不同的源域,产生的迁移效果千差万别:总能找到一些领域,迁移效果比不迁移好。
- 在选择正确的源域上,有时,随机选择的效果不一定会比经过作者的方法计算出来的要差。这说明,计算领域相似性的方法还有待加强。
本篇论文主要的新颖之处在于使用DTW和DBA算法,在评估相似性时更加具有说服性。
3 Transfer learning with seasonal and trend adjustment for cross-building energy forecasting
论文:https://www.sciencedirect.com/science/article/pii/S0378778817329171
这篇论文的背景是,对于一座新建的大楼,预测它的耗能(内有传感器检测),由于新建大楼,检测到的数据非常有限,预测就不太准确,尤其是这种季节性很强的数据,于是作者想通过迁移学习来使用与它相近的大楼的数据进行模型的训练。
正则化方法:
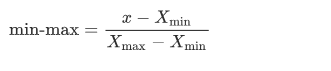
min-max方法重新计算值,并将样本限制在0到1之间。
The z-score:

它返回的距离x均值μ,以倍数的标准差σ[8]。对于遵循正态分布的属性,建议使用z-score归一化。
选用模型:

趋势成分(Tt)是一个平稳、有规律和长期的统计序列,代表总体的增长或下降;循环(Ct)分量是在不规则周期内多次重复出现的一种模式;季节性成分(St)与周期性成分相似,但模式发生在一个定义明确的时期(例如,每日、每周或每月);而不规则分量(It)是余数,它可以与非时间因素相关,也可以简单地认为是一个误差。周期性(Ct)和趋势(Tt)成分经常被分析在一起,并合并为一个单一的。
选择最合适的模型取决于要分析的数据。当变化量(高与低之间的距离)随时间保持相对恒定时,加法模型最适用;当变量随局部平均值(平均值越高,变化越大)[13]变化时,乘法模型最有效。
接下来介绍迁移学习,老一套。略。
本文提出了一下方法
Hephaestus method
Hephaestus (古希腊神话中的火神)同时处理时间序列和多特征回归。它将时间组件从各个域中分离出来,将所有域的剩余组件调整为一个域,并使用任何标准的机器学习算法来创建预测模型。

(A) 时间序列适应,对所有源和目标数据集的时间效应(如季节性、趋势)进行分析,转移到目标(如果需要),并删除季节和趋势组件。
(B) 非时间域适应,即对非时间特征域和消费数据域进行适应。
(C) 标准机器学习,它使用任何合适的标准算法来训练预测模型,并使用预测集生成预测。
(D) 调整,即利用时间序列适应和非时域适应阶段计算的因子对预测进行重新调整。
具体的实现步骤:
Time series adaptation
这个阶段有两个目标:
(a)从所有数据集中删除时间的影响,
(b)将时间序列知识(如果需要)从源转移到目标构建。
下图说明了这个阶段。接收n个原始源数据集和目标数据集作为输入。作为输出,每个数据集的标签Y包含趋势和季节性删除后的能源消耗数据。

Trend removal
每个输入数据集的消费数据可能有不同的趋势。为了减小这种差异,趋势剔除程序计算趋势因子,并将其从消费数据中剔除,消费数据失去了长期趋势,如上图所示。
为了计算趋势因子,执行了两步程序。首先,使用移动平均线进行趋势平滑
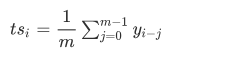
其中tsi为消费时间序列中的每个数据点i计算,m为i之前的最后m个数据点。一般选择m是为了确保只删除长期趋势。例如,如果数据集包含每天的条目,可以将m设置为365,以保持与每月和每周季节性相关的周期性组件。
第二步是趋势消除。用该方程计算了趋势因子:

其中r是一个参考值的索引,通常是数据集的最后一个点。
Seasonality removal
与消除趋势相似,这一步用来消除季节性
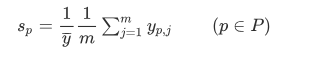
该阶段剔除趋势和季节性因素后的结果是剔除了时间效应的消费数据的剩余成分。
Non-temporal domain adaptation
非时间域适应阶段的目标是对齐所有非时间特性(那些不定义时间和不依赖于时间的特性)和消费数据的域,使它们能够一起处理。本文提出了非时域自适应的局部和全局归一化方法,但赫菲斯托斯算法具有足够的灵活性,可以与其他领域的自适应技术协同工作。下图说明了这个阶段的工作原理。

Local normalization
能量消耗与外部温度之间的关系就是一个相对关系的例子。在这种情况下,温度对每个建筑的消耗的影响是特定的,因为每个建筑与外部环境的热交换特性不同。通过使温度正常化,这些影响在所有建筑物中保持一致。
Global normalization
例如,假设所有的建筑物都配备了相同类型的设备(例如计算机),并且设备的数量是一个数据集特性。假设每台设备所消耗的能量与它安装的位置无关,是相同的,那么它与能源消耗的关系将被认为是绝对的,因为能源消耗直接取决于打开的设备的数量。
试验:
使用一年的数据训练的模型,用于只有一个月数据的新建筑的预测,发现只用一个月的数据训练,同样可以达到一样的效果。

图中发现他们具有不同的走势,Hephaestus对于调整数据集并使它们能够联合使用非常重要。
总结:
这篇论文提出了一个算法,该算法用于数据的预处理,可以将源数据大致分解为三部分
(1) 季节性特性
(2) 趋势特性
(3)非时间特性(例如,温度影响,内置主机的个数)这又分为
Local normalization(温度对建筑的影响是相同) 和 Global normalization(内置主机的个数直接影响消耗)
对于具体的数据来选择具体的方法
例如本文,选择提出趋势的影响,对季节性迁移,并且只考虑每周的季节性。

以一周为一个周期,并且选取与目标域相似的季节性数据进行迁移,去除不相似数据。
同时对非时间因素进行归一化(合并它们作为输入)

小结
目前为止我读到的论文关于迁移学习涉及到
1 迁移模型选择(大多都使用LSTM,GRU或者CNN),对参数进行迁移
2 通过比较相似性后,进行迁移。
3 先对数据进行预处理后,分出周期因素,趋势因素,非时间因素,有选择的迁移
论文3,对我以前的疑问进行了解答,可以做到数据的有选择迁移(数据的细化),那我接下来我该做什么呢?
研究一下神经网络的训练过程。那一部分数据起到什么作用。
想法:
突发奇想,可不可以根据源数据生成新的数据,而这条数据与目标数据相似,用这个数据来训练模型,达到迁移学习的目的,主要解决的问题是迁移学习只适合两个十分相似的数据集。
用于解决数据量不足无法用于训练问题:
(1)能否找出部分数据与整体数据的关联,训练一个模型,可以实现少量数据逆向生成具有整体数据趋势或周期的数据
(2)使用已知的少量数据借助模型生成足够的数据集
(3)使用生成的数据集去训练模型
(4)利用该模型预测
4 A novel transfer learning framework for time series forecasting
论文:https://www.sciencedirect.com/science/article/pii/S095070511830251X
(1)问题的提出
在现实中,时间序列数据往往表现出某种时变特性,这可能导致新旧数据之间存在较大的变异性。因此,在处理时间序列预测问题时,如何在较长时间跨度内迁移知识,是一个严峻的挑战。
为了解决这一问题,本文提出了一种基于转移学习、带核在线顺序极限学习机(OS-ELMK)和集成学习(简称TrEnOS-ELMK)的混合算法,并给出了其精确的数学推导。
(2)框架
如图所示,提取了大量与当前新样本时间跨度较长的过去数据。由于具有时变的特性,大变异性通常分布在新旧样本之间。通过应用迁移学习,从旧数据中学到的知识被保留下来,并巧妙地用于未来的预测过程。特别是在旧数据的基础上,首先生成了ELMK的核矩阵和相应的权矩阵。
2.1 ELM(极限学习)在时间序列预测中的应用
由于ELM只涉及乘法的基本矩阵运算和Moore-Penrose 广义逆,因此通常具有较快的学习速度
2.2 迁移学习和在线学习
提出了在线迁移学习框架(OTL),介绍几种先进的迁移学习方法
3 对提出的算法 TrOS-ELMK 进行推导
为了更好地介绍和概述本文所提出的算法,本文首先简要介绍了本文最后提出的算法的总体框架,即一种融合了转移学习、os- elmk和集成学习的混合算法,简称TrEnOS-ELMK。
简而言之,TrEnOS-ELMK大致可以分为两部分
在第一部分中,通过将知识从旧数据转移到新的现有数据,生成了一组ELMK模型。由这些初始权值相同的基本模型构造一个原始的集成。第二部分,随着新样本的到来,根据不同模型的预测精度自适应调整模型的权重同时,对模型的参数分别进行了更新。将最穷的模型替换为新的训练模型的决策取决于集成的性能是否不合格。图2直观地描述了TrEnOS-ELMK的框架。
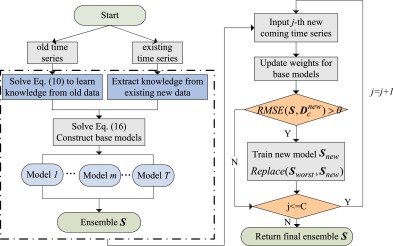
TrEnOS-ELMK框架
4试验
这里作者用了很多种数据集,我只关心下面一种数据集
该数据集来自于时间序列数据库,记录了英国1723年至1970年[45]月的温度。由于天气模式的时变特性,在很长一段时间内,温度之间通常会出现差异。因此,我们提取了前100年和后70年的时间序列进行实验。具体来说,我们将1723 - 1823年的温度作为旧数据,而将1900 - 1970年的温度作为新数据。
4.1验证
为了验证本文框架的优越性,选择在线顺序ELM (OS-ELM)[29]、在线顺序改进误差最小化ELM (OS-EMELM)[30]、ELM自适应集成模型(AEE)[31]、在线支持向量回归(OLSVR)[47]、增量支持向量回归模型(OISVR)[48]、跨域SVR (CDSVR)与我们的算法进行比较。同时还和自己作比较。
5 结果
分别在不同的数据集上做了对比,评价。
6总结
由于时间的时变特性,长时间跨度之间的时间序列数据往往相差很大。因此,直接使用旧样本进行未来预测是不可取的。本文是把旧数据中的知识迁移到新数据中。也就是说目标域和源域依然是属于同一场景。本篇论文很长,是对已有算法的优化和组合。
问题:
(1)作者运用迁移学习从旧数据迁移知识到新数据中提取的是什么内容?
答:
该算法从旧数据中转移知识的过程可以总结为:首先,在已有数据集上训练初始ELMK模型;然后根据公式(22),根据可用的新数据对初始模型的参数进行更新。
ws 是训练旧数据获得的是权值,wt可以看作是对目标领域的知识学习。为了更好地利用源知识,最好将ws和wt之间的差异最小化。此外,为了保证模型的预测性能,有必要对现有的新样本最小化训练误差。根据以上分析,从旧数据中转移知识的问题可以表述为式
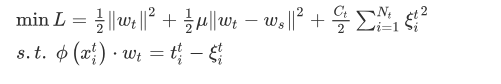
加入在线学习
随着新样本的加入,需要对之前构建的模型进行更新。由于模型是基于ELM算法,其中输出权向量是最小二乘解,我们的目标是找到一个对现有样本和新样本的范数参数向量最小、训练误差最小的模型。
加入集成学习
在第一步中,生成多个具有相同权重的基模型,构造一个原始的集成。其次,为了保证整体性能,需要根据不同模型对现有新数据集的预测精度,自适应地更新它们的权重。性能优越的模型通常具有更重的重量。为了便于描述,下面列出了一些相关的定义
随着新鲜样本的到来,过去时间序列生成的集成可能会出现性能下降。因此,培训新模型作为一个新的注射总是被认为是可取的。如果集成的性能没有达到预先定义的标准,预测精度较差的模型将被替换。
想法
框架
(1)根据已有的数据产生的过程来模拟这个过程
(2)通过调节已知的特征属性,来控制产生需要预测特征的属性
(3)获得产生的数据后,用它来训练模型
(4)用已有的不足的真实数据来训练模型(这里真实的数据每天都在产生,所以不断的输入,不断的调节参数,使得准确性提高)
问题
(1)源域和目标域,相似处在于预测特征和其它特征之间的相关性相同?
(2)到底存不存在有这样的相关性,能不能通过相关性来生成数据?
实现:
(1)学习使用GAN模型来根据历史数据生成新数据,不同的是,调整一些特征的输入产生新的数据。
所以我要做的大概是,使用gan来做预测模型,并且是监督学习,至于使用什么特征来做xi 有待探索。
5 Generative Adversarial Network for Synthetic Time Series Data Generation in Smart Grids
论文:https://ieeexplore.ieee.org/abstract/document/8587464
问题的提出:
数据可得性,数据量的大小,数据安全和隐私的问题妨碍了数据广泛的公共可用性。
目的:
在本文中,我们提出了一种新的数据驱动方法来合成数据集的生成,利用深度生成对抗网络(GAN)来学习真实数据集中基本特征的条件概率分布,并根据所学习的分布生成样本。
论文结构
列出来前人提出的方法,找到了它们存在的问题。
提出了深度生成对抗网络(GAN),虽然在图片生成方面表现不错,但是很少用于类似于具有季节性,长短期,用户行为等时间序列上。
本文的贡献:
(1)首先,我们开发了一个概率模型来抽象智能电网时间序列数据集中固有的重要特征
(2)然后,我们开发了一个条件GAN来学习真实数据集的概率分布,从而生成统计测试下不可分辨的综合数据集。据我们所知,这是第一次在智能电网中使用深度GANs
(3)我们通过统计测试和经典的机器学习任务(包括timeseries聚类和负载预测)来评估生成的合成数据集的有效性,并表明结果与实际数据集没有什么区别
数据集的定义
。。。
GAN模型
在这项工作中,我们使用一种称为condition GAN[17]的变体GAN体系结构来学习时间序列数据的条件概率分布。
评估策略
。。。
在智能电网中,人类活动数据集通常包含日、月和季节模式。它们源于人类行为的周期性。
我们假设每个时间序列都是Level和pattern两个部分组成
Level:由家庭消费水平、季节等属性决定,并影响时间序列数据的尺度和偏差。例如,高收入家庭可能比低收入家庭消耗更多的能源. 由于高温暖通空调的使用,所有家庭通常在7月比10月消耗更多的能源。
pattern:由家庭活动决定。由于人们外出工作,上班族家庭白天消耗的能源可能很少;夜猫子家庭在夜间消耗更多的能量。在本研究中,我们假设 Level 是由时间序列的日均值和标准差来捕获的,我们使用GAN来学习用户 Pattern.
注:上面的分析主要是人为因素,当然用电量也包括了阳光,温度,季节等因素
用数学来描述这些因素:
我们把整个时间序列分解成以每一天为单元的向量,将特定用户u的每个日数据向量表示为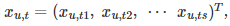
其中s是每天的样本数,t是每天的下标。我们假设每日数据向量的分布是有条件的依赖下标 t 和用户下标 u 。此外,我们假设这一天下标 t 可以表示为星期{Sun, Mon, · · · , Sat},今年月{Jan, F eb, · · · , Dec}.。数学上,我们可以写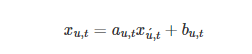
其中 aut 和 but 表示 level 信息(aut 表示比例,but 表示偏差),xut 表示pattern信息。然后,条件概率分布表
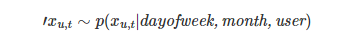
每个用户都有不同的分布,因此,从不同的分布中采样不同用户产生的时间序列。给定N个不同用户的训练数据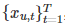 其中u= 1,2,n,目标是训练一个生成器函数G,它可以生成服从分布p的样本,而不需要显式地建模或计算p
其中u= 1,2,n,目标是训练一个生成器函数G,它可以生成服从分布p的样本,而不需要显式地建模或计算p
数据处理流程
在预处理步骤中,我们按照下式进行水平归一化,得到条件概率分布
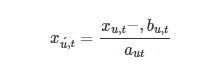
 为用户u在第t天的能耗或太阳能发电量的标准差和平均值。在学习阶段,我们使用GAN隐式学习分布p,生成合成样本x^u,t。在后处理步骤中,我们执行级别恢复为
为用户u在第t天的能耗或太阳能发电量的标准差和平均值。在学习阶段,我们使用GAN隐式学习分布p,生成合成样本x^u,t。在后处理步骤中,我们执行级别恢复为
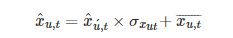

试验过程
数据分布
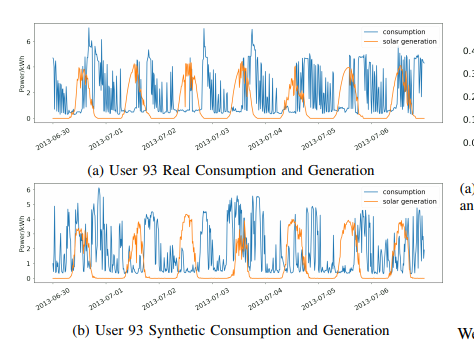
数据集收集时间为2013-01-01 - 2016-12-31,平均每15分钟耗电量和太阳能发电量。图2显示了2013-10-08至2013-10-14年93号用户的能耗和太阳能发电量。我们观察到,太阳能发电呈现出重复的模式,噪音来自云和雨。本周消费也出现了类似的趋势,但出现了不规则的峰值。
我们在图3中展示了我们的条件GAN架构。我们使用 embedding layer把日、月标签转换为 one-hot矢量表示。该发生器将正态分布中采样的日向量、月向量和噪声串联起来,送入3层一维经位卷积网络,产生合成输出。识别器是一个3层的一维卷积网络,它输入实际数据或合成数据,日向量和月向量为输入,生成输入是真实的还是合成的标签

图说明了GAN运行过程
使用K-Means聚族来评价生成结果
利用真实数据拟合模型,预测合成数据的聚类标签。
利用合成数据拟合模型,预测真实数据的聚类标签。
使用混合的真实和合成数据拟合模型。
理想情况下,由同一个用户生成的实时序列和合成时间序列应该属于同一个集群。我们使用F1-score[20]比较真实标签和合成标签。在本实验中,为了简化结果的说明,我们将簇K的个数设为3。
然后又使用Short-term Load Forecasting来评估
以下进行了各种评估
。。。。

利用真实数据和综合数据进行负荷预测的平均绝对百分误差(MAPE)分布,看起来还不错是么?
文中没有给出与其他生成方法的比较
总结
分布式智能电网缺乏细粒度的时间序列数据集,阻碍了新数据驱动方法的发展。在本文中,我们建立了一个通用的概率时间序列数据模型。我们提出使用生成式对抗网络生成与真实数据集具有相同分布的合成数据集。为了评估合成的数据集,我们进行了统计测试以及经典的机器学习任务,包括时间序列聚类和负载预测。实验结果表明,合成数据集和真实数据集是不可区分的。
所以接下来我该用这个方法来生成关于污染预测时间序列数据集,听上去很棒。
问题:
1 使用gan生成数据时,生成的数据需要进入判别器与真实的数据比较,使得判别器无法区分是否为真实数据,但是我不是要生成与真实数据一样的数据,而是根据已知特征,生成相应的数据。(这是auto-encoder的思想,gan应该有不同的表现)
2 既然这样,为什么要用gan模型呢,这不就是一个监督学习的问题吗?
3 所以要想提高准确性,就是找到一个相关性最高的的特征,独一无二的特征,所以这里需要探索。
4 这又回到了预测模型上面了!!!!!艹
5 接下来分别使用经典的预测模型,和gan实现监督学习预测模型,进行预测,比较准确性。
6 Conditional Generative Adversarial Nets
论文 https://arxiv.org/pdf/1411.1784.pdf
视频 https://www.youtube.com/watch?v=LpyL4nZSuqU&t=381s
博客 https://blog.csdn.net/dukuku5038/article/details/85028130
动机:
在无条件生成模型中,没有对生成的数据模式的控制。 然而,通过将模型设置为附加信息,就有可能指导数据生成过程。这种条件作用可以基于类标签、用于inpainting的部分数据(如[5]),甚至基于不同形式的数据。
Multi-modal Learning For Image Labelling
尽管监督神经网络最近取得了许多成功,要扩展这样的模型以适应数量非常大的预测输出类别,仍然具有挑战性。第二个问题是,到目前为止,大部分工作都集中在学习从输入到输出的一对一映射。然而,许多有趣的问题更自然地被认为是概率一对多映射
工作
Generative Adversarial Nets
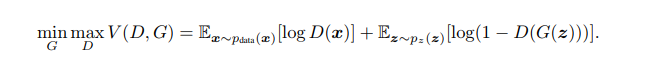
Conditional Adversarial Nets
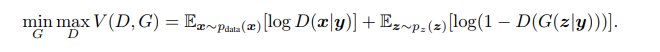
相比于,上一个式子,增加了标签
框架

试验
我们根据MNIST图像的类标签(one-hot)训练了一个条件对抗性网络
想法
最近又想了想,又发现了新的问题
其实问题还是在于目标域和源域的相似性,之前读过的几篇论文有一个共同的问题,目标域和源域相似性要求十分高,导致迁移条件十分苛刻,我的想法创新点就在于,放宽看条件,假如智能工厂这个场景下,我的想法是:
已知一些老工厂的所有的数据
这个时候需要建设新的工厂,我这时候可以用老工厂的数据
两个工厂的地理位置不同,导致一些周期性的因数不同
两个工厂的,规模,产量和排放量等不同(预测的排放的污染物一样),导致一些非周期的东西不同,趋势不同
对于一个时间序列,其就是有三个因素组成,即周期,趋势,和可变因素。如果这三个都不同,目标域和源域没有相似性可言,怎么进行迁移呢?
所以就如Transfer learning with seasonal and trend adjustment for cross-building energy forecasting这篇论文一样,寻找外界因数相似的工厂,趋势和产量可以不同。
总结:
(1)保证两个工厂生产的东西一样(必要条件)
(2)保证所在地区天气等外界因数相似
条件(2)有些苛刻,于是我想两个地区的气候不一定完全相似,可能有几个周天气相似的,我想gan模型应该能解决这个问题。
做一下试验:
(1)把不同地区工厂的数据混合后输入condition gan中
(2)只输入与之相似的工厂的数据
工作
经过和师兄的讨论后,有以下工作要做:
(1)先从小的方面入手,逐渐把问题抽象化,形成一个普适性的框架。
(2)读相关领域的论文,对自己的想法进行补充优化
(3)细化模型
(4)利用不相关数据生成相关数据
找数据集很困难,数据集的要求
1 要求源域和目标域之间不相互影响
2 要求有明确的关联性很强的特征属性
天气或污染预测排除了,因为影响因素十分复杂,不适合做初期的验证工作。
7 Transfer learning for short-term wind speed prediction with deep neural networks
https://www.sciencedirect.com/science/article/pii/S0960148115300574#bib26
1 问题提出以及其他论文的解决方案
(1)数据驱动建模是一种有效的选择。对于一些新建的风电场,没有足够的历史数据来训练一个准确的模型,而一些较老的风电场可能有长期的风速记录。,一个问题是,由来自老农场的数据训练的预测模型是否对新建农场也有效。
(2)有许多风电场位于不同的地区。对于风速预测,不同的风场可以学习不同的模型。当数据量足够时,这是可行的。但对于新建风电场,风速数据不足,无法进行模型设计
Togelou等人针对这一问题提出了一种解决方案,他们提供了两个自构建和自适应的统计模型
Wind Power Forecasting in the Absence of Historical Data
(3)他们没有考虑任何其他网站的数据。另一种策略是通过混合目标域和其他域的数据来学习模型。只有当来自其他农场的数据可以直接用于训练目标模型时,这才有意义。由于不同区域风速模式不同,上述解决方案通常不可行。因此,提出了另一种战略。
Domain adaptation for large-scale sentiment classification: A deep learning approach
这种策略是指从一组域学习一个共享模型,然后将该模型调整到每个单独的域。然而,只有当模型能够发现跨域共享 和有用的中间抽象时,这种方法才有效。
2 本文提出的方案
将多源风速信息融合在一起,构建了一个DNN。隐藏层在许多农场之间共享,而输出层依赖于农场。共享隐藏层可以看作是一种通用的特性转换,适用于许多领域。
3 数据采集与分析
我们收集了宁夏、吉林、内蒙古和甘肃四个风电场的风速历史记录。风速的符合分布情况。
4 自编码去燥
5 共享隐藏层DNN
https://ieeexplore.ieee.org/document/6639348
在该体系结构中,所有风电场都共享输入层和隐藏层,可以将其视为一个公共特性转换。但是,输出层不是共享的,而是彼此独立的,每个农场都有自己的输出层,因为它的数据分布不同于其他农场。这是一种知识传输类型,其中将通用特性传输到每个数据集。
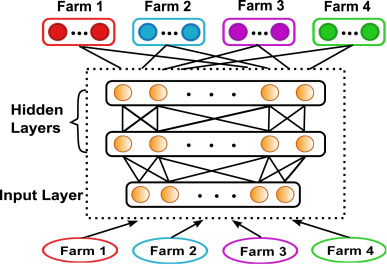
6 试验
训练策略
总结:
(1)这篇论文最大的创新之处在于把共享隐藏层DNN模型用于时间序列
(2)在训练策略上别出心裁,值得学习
这篇论文总体来说还是很有意思的,模型的提出,但是并没有给出为什么使用这样的模型可以,没有给出验证,通过大部分是试验验证。
另外通过试验发现预测只对短期有效(半个小时左右),时间稍长就不行。
试验结果分析透彻,但是试验过程不清楚。
框架的通用性不强。
工作:
接下来使用该数据进行试验。
8 Multilingual acoustic models using distributed deep neural networks
https://ieeexplore.ieee.org/document/6639348
1 问题描述
一般来说,数据稀缺不仅是一个代价高昂的数据收集问题,而且对于那些难以找到大量有代表性数据的低流量和新发布的语言来说,也是一个不可避免的瓶颈。
2 多任务学习
与上面描述的传统的单任务学习方法相比,多任务学习是一种很有吸引力的选择。在这种方法中,多个任务并行学习,并使用共享表示。多语言语音识别体系结构如图1所示。在本例中,特征提取是共享的,而每种语言都有一个单独的分类器。多任务学习可能有几个好处。

这篇文章我学到的就是使用多任务学习。
问题
(1)按照原来的思想,使用CGAN需要找到相关特征,对于一些相关特征不足或者没有不适用。
(2)要是非监督学习呢?
1 解决使用不同域数据的预测问题
9 Crude oil price prediction model with long short term memory deep learning based on prior knowledge data transfer
https://www.sciencedirect.com/science/article/pii/S036054421832382X?via%3Dihub
https://www.sciencedirect.com/science/article/pii/S0950705115000179?via%3Dihub
问题
1 到目前为止,我的思维可能陷入某一个点,应该跳出来重新设计
2 整理迁移学习的发展现状
10 Correlated Time Series Forecasting using Deep Neural Networks: A Summary of Results
https://arxiv.org/abs/1808.09794?context=stat.ML
举例:
使用传感器对排污工厂的排污进行监控时,会有很多种污染物排放,而且不同污染物之间相互有影响。
另外使用传感器对交通监控时,一个路段的交通情况会受其他路段的交通情况的影响,他们之间也是相关的。
因此:
作者通过把CNNs模型和RNNs结合,第二个模型是把自编码加入CNNs,使其变成一个多任务学习模型。
CNNs的使用帮助我们了解每个时间序列的特性。
CRNN:我们首先独立考虑每个相关的时间序列,并将每个时间序列输入到一维卷积神经网络(CNN)中。CNNs的使用帮助我们了解每个时间序列的特性。然后将卷积后的时间序列特征融合在一起,并将其反馈给一个递归神经网络(RNN),在学习序列信息的同时考虑不同时间序列之间的相关性。
AECRNNs:我们在CRNN中增加了额外的自动编码器。卷积时间序列的输出不仅被合并到一起,而且被送入RNN。此外,每个卷积的时间序列也被重构回原来的时间序列。然后,将目标函数与RNN预测的误差和自动编码器的重构误差相结合,得到了目标函数的估计结果 。AECRNN是一种多任务学习模型。
相关工作:
线性vs非线性,单一Vs复杂
设计了相关的对比实验。这一段作者举出了很多的预测模型,来实现对比实验。
CNNs 善于提取图片的特征。RNNs 可以捕获序列值之间的相关性,从而更好的预测。作者猜想两者结合能获得更好的结果。
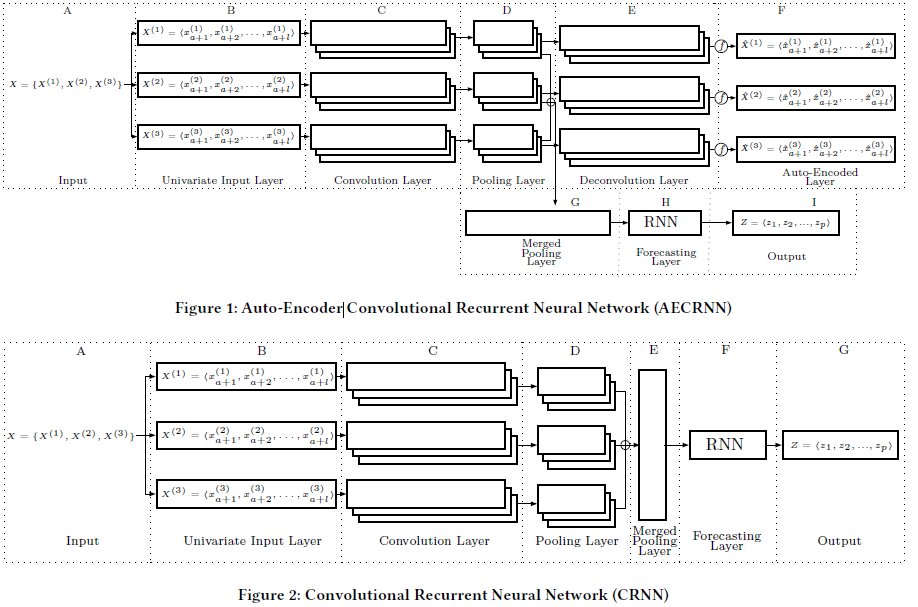
接下来就是训练策略
结果对比
结果发现ARIMA对于短期的预测表现好,而CRNN和AECRNN对于长期预测表现很好。
结果发现,AECRNN能够较好地预测峰值的幅值,但忽略了顶部的小畸变。
(1)由于自编码器的存在,使得AECRNN对不相关时间序列的鲁棒性更强;
(2)具有相关时间序列的CRNN具有更大的优势。
11 Cross-language Transfer Learning for Deep Neural Network Based Speech Enhancement
这篇论文是通过在汉语和英语之间使用迁移学习,对于这两种无关的语言,作者发现,虽然他们看上去无关,使用DNN模型训练,其实每种语言特别的特征主要集中在前两层,而其他层中具有相似性,因此,可以使用迁移学习来进行训练。
12 High-dimensional Time Series Clustering via Cross-Predictability
时间序列聚类的关键是如何描述任意两个时间序列之间的相似性。
作者提出了一个可以用于高维时间序列聚类的算法。
13Visualizing the intercity correlation of PM2.5 time series in the Beijing-Tianjin-Hebei region using ground-based air quality monitoring data
14 Time Series Analysis Using Geometric Template Matching
https://ieeexplore.ieee.org/document/6205761/citations#citations
15 CONVOLUTIONAL, LONG SHORT-TERM MEMORY, FULLY CONNECTED DEEP NEURAL NETWORKS
CNNs LSTMs 和DNNs 个有个的优势,但是能力也有限,作者认为把它们连起来会获得更好的效果。
我们提出的模型是将输入特征在时域环境中输入到几个CNN层中,以减小频谱变化。然后将CNN层的输出输入到几个LSTM层中,以减少时间变化。然后,将最后一个LSTM层的输出提供给几个完全连接的DNN层,这些DNN层将特性转换为一个空间,使输出更容易分类。
训练方式不同,之前有人做过的 是先分别训练三个模型再连接起来,而本篇文章是三个模型连接起来一起训练。
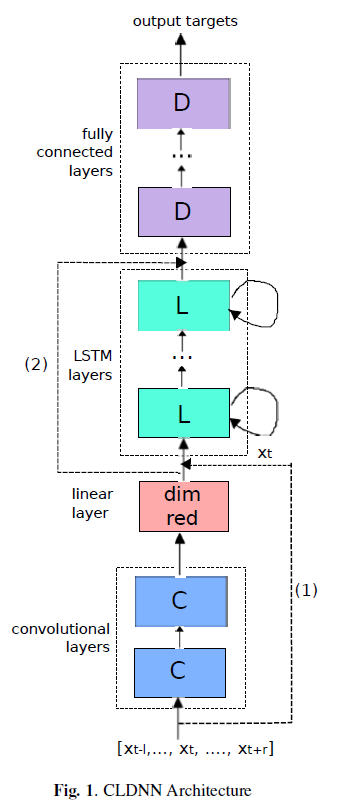
接下来试验,通过对三个模型的排列组合,证明了这样结合的有效性。
16 Singing Voice Correction Using Canonical Time Warping
https://ieeexplore.ieee.org/document/8461280
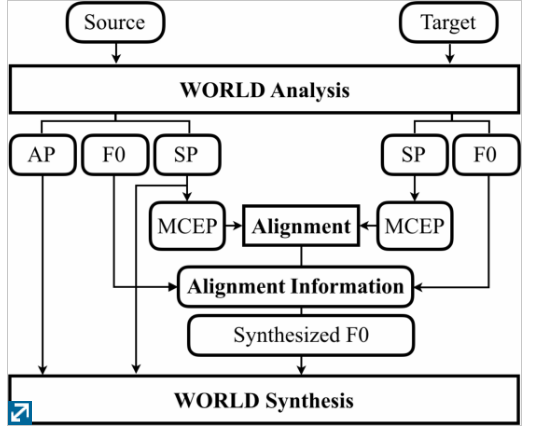
本文要解决的问题是,类似于调音师的工作,把一段声音以标准规范的声音为准,来对其进行调整。
17 Robust and Rapid Clustering of KPIs for Large-Scale Anomaly Detection
https://netman.aiops.org/wp-content/uploads/2018/05/PID5338621.pdf
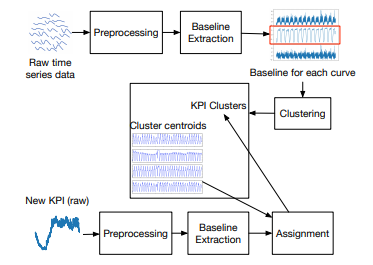
这篇文章提出了一个将时间序列快速聚类的方法。
而在做时间序列聚类的时候,也有着不少的挑战。通常挑战来自于以下几点:
- 形状:通常来说,时间序列随着业务的变化,节假日效应,变更的发布,将会随着时间的迁移而造成形状的变化。
- 噪声:无论是从数据采集的角度,还是系统处理的角度,甚至服务器的角度,都有可能给时间序列带来一定的噪声数据,而噪声是需要处理掉的。
- 平移:在定时任务中,有可能由于系统或者人为的原因,时间序列的走势可能会出现一定程度的左右偏移,有可能每天 5:00 起的定时任务由于前序任务的原因而推迟了。
- 振幅:通常时间序列都存在一条基线,而不同的时间序列有着不同的振幅,振幅决定了这条时间序列的振荡程度,而振幅或者基线其实也是会随着时间的迁移而变化的。
对于所有可能的位移s2 [m + 1, m1],我们可以计算内积CCs(~x, ~y)作为时间序列~x和~y与相移s的相似性,定义为Eq
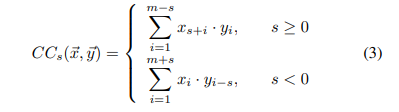
互相关是CCs的最大值(~x, ~y),表示在最佳相移s时~x和~y之间的相似性。直观地说,在最优偏移时,~x和~y中相似的模式是正确对齐的,这样内积就是最大的。因此,互相关测度可以克服相移,表示两个时间序列之间的形状相似性。
18 Task-Adversarial Co-Generative Nets
在本文中,我们提出了任务对抗性协同生成网络 (TAGN)用于从多个任务中学习。它旨在解决多任务学习的两个基本问题,即,领域转移和有限的标记数据,以一种有原则的方式。
TAGN使用一种对抗策略来生成“好的”特性和“好的”示例
实验结果表明,TAGN通过平滑域转移和缓解标记数据的稀缺性,优于现有的方法。这项工作的主要贡献概括如下:
1 一种有原则的方式,对领域不变的特征和可信的例子进行对抗性的协同生成,以弥合领域差距和处理稀疏数据问题。
2 关于任务不变特征的边际分布和似然样本与标签的联合分布的博弈均衡的保证。
3 在基准数据上的实验证明了该方法的有效性。
我们提出的策略是学习“好的”特性来弥补领域差距,并生成“好的”示例来处理稀疏标记的数据问题
19 Streaming Adaptation of Deep Forecasting Models using Adaptive Recurrent Units
https://arxiv.org/abs/1906.09926
提出一个新的预测模型ARU,基于深度神经网络。
20 Model-Free Renewable Scenario Generation Using Generative Adversarial Networks
与现有的基于概率模型的方法相比,我们的方法是数据驱动的,并在时间和空间维度上为大量相关资源构建可再生能源生产模式。或者验证,我们使用来自NRELintegration数据集的风能和太阳能时间序列数据。实验结果表明,该方法能够生成逼真、行为多样的风电和光伏电源剖面。
此外,气候的时变特性、非线性和有界功率转换过程以及复杂的空间和温度相互作用,使得基于模型的方法难以应用,也难以扩展,尤其是考虑到多个可再生发电厂时。
为了克服这些困难,在这项工作中,我们提出了采用生成方法数据驱动(或无模型)方法。具体来说,我们建议利用最近发现的机器学习概念生成对抗网络(GANs)[10]来完成场景生成任务。
自回归模型和状态空间规范虽然简单易行,但容易对模式进行过度拟合和错误识别。由于潜在地需要包含大量的状态,要在可再生发电过程中捕捉到足够的多样性也很难使用这些模型。
近年来,提出了几种用于场景生成的机器学习算法。在[22]中,将径向基函数神经网络(RBFNN)与粒子群opti-mization (PSO)算法相结合,生成具有数值天气预报(NWP)输入的场景。
对[23]、[24]、神经网络模型进行训练,输出时序功率生成或发生概率。与copula或timeseries方法相比,这些基于机器学习的算法可能更好地捕捉可更新生成过程的非线性动态,但所有这些都依赖于对输入特性的仔细选择,并且在实践中进行调优和使用非常重要。
综上所述,上述大部分方法首先采用历史观测拟合模型,然后对拟合的概率模型进行采样,生成新的场景。其中一些方法可能还需要对数据进行预处理。尽管有了显著的进步,场景生成仍然是一个具有挑战性的问题。天气的动态和时变特性、非线性耳朵和有界功率转换过程,以及复杂的时空交互作用,使得基于模型的方法难以应用和扩展。通常,一套单一的模型雨量计无法捕捉这些复杂的动态,尤其是考虑到多个可再生发电厂时。这些模型通常建立在统计假设的基础上,这些假设可能不成立或在实践中难以检验(例如,预测误差是高斯分布的)。从高维分布(如非高斯分布)中采样也是非平凡的[3]。在addition中,高斯copula和ARMA等方法依赖于一定的概率预测作为输入。预测的时空重现性和准确性直接影响所生成情景的多样性。
历史数据和生成的场景并不完全匹配。我们的目标是生成新的、独特的场景来捕捉历史数据的内在特征,而不是简单地记忆训练数据。
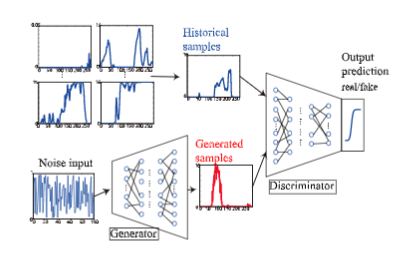
A Single Time-Series Scenario Generation
B Scenario Generation for Multiple Sites
C vent-Based Scenario Generation
接着作者对GANs模型进行设计。
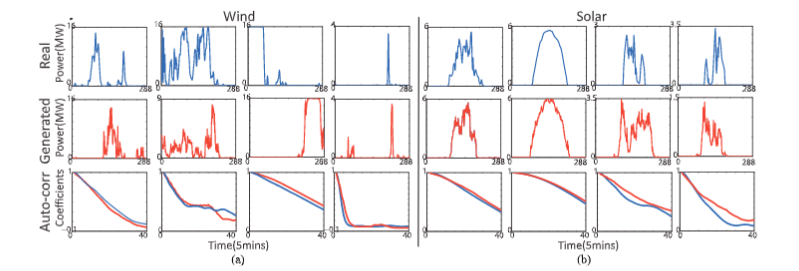
从我们的验证集中选出的样本(顶部)与从我们为风能和太阳能组训练的甘斯系统中生成的样本(中间)进行比较。采用基于欧氏距离的搜索方法选择样本。在培训中不使用这些验证样例,我们的GANs就能够生成具有相似行为的样例,并显示各种模式。自相关图(底部)也验证了生成的样本捕获正确时间相关性的能力。
试验:
我们使用来自NREL wind1和Solar2IntegrationDatasets[31]的发电数据构建培训和验证数据集。原始数据的分辨率为5分钟。我们选择位于华盛顿州的24个风电场和32个太阳能发电厂作为培训和验证数据集。
这些发电地点的地理位置相近,表现出相关(虽然不是完全相似)的随机行为。通过使用这些位置的历史数据作为输入,无需修改算法,我们的方法可以轻松地处理跨多个位置的场景联合生成。因此,时空关系是自动学习的。
结论:
情景发电可以对可再生能源发电的不确定性和变异性进行建模,是可再生能源普及率高的电网进行决策的重要工具。提出了一种新的机器学习模型——广义对抗网络(GANs),并将其应用于可再生资源的情景生成。我们提出的方法是数据驱动和无模型的。它利用深度神经网络和大量历史数据集的能力,直接生成符合相同历史分布的场景。
应用所提出的模型建立的案例研究表明,GANsworks在风能和太阳能的场景生成中都能很好地工作。我们还在模拟中显示,通过使用来自多个站点样本的历史数据对模型进行再培训,GANs能够为这些站点生成具有修正的spa-tiotemporal correlation的场景,而不需要任何额外的调优。
通过添加表示场景属性的类信息,GANs能够生成符合相同示例属性的类条件样本。通过一系列统计方法验证了生成的样本的质量,并与高斯参copula方法进行了场景生成的比较。由于我们提出的方法不需要任何特殊的统计假设,它可以应用于电力系统中大多数随机过程。此外,由于该方法采用前馈神经网络结构,它不需要对可能复杂的高维过程进行采样,并且可以方便地扩展到具有大量不确定性的系统。在未来的工作中,我们建议将遗传算法引入概率预测问题。此外,我们还希望利用这些场景,将其扩展到可再生能源发电的高渗透决策策略设计中。