//加载需要的包
import org.apache.spark.rdd._ import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel}
//读取数据
val ratings = sc.textFile("D:/BaiduYunDownload/machine-learning/movielens/medium/ratings.dat").map { line =>
val fields = line.split("::")
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}

//数据情况探索(评分数,用户数,物品数)
val numRatings = ratings.count()
val numUsers = ratings.map(_._2.user).distinct().count()
val numMovies = ratings.map(_._2.product).distinct().count()
println("Got " + numRatings + " ratings from " + numUsers + " users on " + numMovies + " movies.")
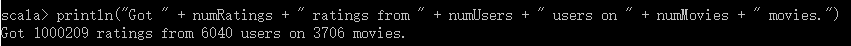
//某个人评分数据
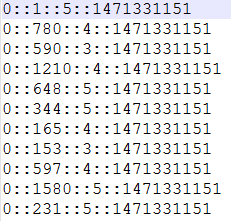
val myRatingsRDD = sc.textFile("D:/BaiduYunDownload/machine-learning/bin/personalRatings.txt").map { line =>
val fields = line.split("::")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}

//拆分训练集,校验集,测试集(ratings是(Int,Rating)格式,取values即可)
val numPartitions = 4
val training = ratings.filter(x => x._1 < 6)
.values
.union(myRatingsRDD) //加入个人评分数据
.repartition(numPartitions)
.cache()
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8)
.values
.repartition(numPartitions)
.cache()
val test = ratings.filter(x => x._1 >= 8).values.cache()
val numTraining = training.count()
val numValidation = validation.count()
val numTest = test.count()
println("Training: " + numTraining + ", validation: " + numValidation + ", test: " + numTest)

// 校验集预测数据和实际数据之间的均方根误差
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long): Double = {
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
val predictionsAndRatings = predictions.map(x => ((x.user, x.product), x.rating))
.join(data.map(x => ((x.user, x.product), x.rating)))
.values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n)
}
//训练不同参数下的模型,并在校验集中验证,获取最佳参数下的模型
val ranks = List(8, 12)
val lambdas = List(0.1, 10.0)
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda)
val validationRmse = computeRmse(model, validation, numValidation)
println("RMSE (validation) = " + validationRmse + " for the model trained with rank = "
+ rank + ", lambda = " + lambda + ", and numIter = " + numIter + ".")
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
//用最佳模型作用于测试集,并计算预测评分和实际评分之间的均方根误差
val testRmse = computeRmse(bestModel.get, test, numTest)
println("The best model was trained with rank = " + bestRank + " and lambda = " + bestLambda
+ ", and numIter = " + bestNumIter + ", and its RMSE on the test set is " + testRmse + ".")

//比较将最佳模型作用于测试集的结果:testRmse 与 仅仅用均值预测的结果进行比较,计算模型提升度。
val meanRating = training.union(validation).map(_.rating).mean
val baselineRmse = math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).mean)
val improvement = (baselineRmse - testRmse) / baselineRmse * 100
println("The best model improves the baseline by " + "%1.2f".format(improvement) + "%.")

//装载电影目录对照表(电影ID->电影标题)
val movies = sc.textFile("D:/BaiduYunDownload/machine-learning/movielens/medium/movies.dat").map { line =>
val fields = line.split("::")
(fields(0).toInt, fields(1))
}.collect().toMap

// 推荐前十部最感兴趣的电影,注意要剔除用户已经评分的电影
val myRatedMovieIds = myRatingsRDD.map(_.product).collect().toSet
val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
val recommendations = bestModel.get{
.predict(candidates.map((0, _)))
.collect()
.sortBy(-_.rating)
.take(10)}

//打印结果

var i = 1
println("Movies recommended for you:")
recommendations.foreach { r =>
println("%2d".format(i) + ": " + movies(r.product))
i += 1
}
over!!