1、C++中有两个方面体现重用:
(1)面向对象的思想:继承和多态,标准类库。
(2)泛型程序设计(generic programming) 的思想: 模板机制,以及标准模板库 STL。
将一些常用的数据结构(比如链表,数组,二叉树)和算法(比如排序,查找)写成模板,标准模板库 (Standard Template Library) 就是一些常用数据结构和算法的模板的集合。
2、概念
容器:可容纳各种数据类型的通用数据结构,是类模板。
迭代器:可用于一次存取容器中元素,类似于指针。
算法:用来操作容器中元素的函数模板。sort()排序vector数据;find()搜索list中对象等。
int array[100]; 该数组就是容器,而 int * 类型的指针变量就可以作为迭代器,sort 算法可以作用于该容器上,对其进行排序: sort(array,array+70); //将前70个元素排序
3、容器:可以用于存放各种类型的数据(基本类型的变量,对象等)的数据结构,都是类模版,分为三种。
1)顺序容器 vector, deque,list
2)关联容器 set, multiset, map, multimap
3)容器适配器 stack, queue, priority_queue
对象被插入容器中时,被插入的是对象的一个复制品。许多算法,比如排序,查找,要求对容器中的元素进行比较,有的容器本身就是排序的,所以,放入容器的对象所属的类,往往还应该重载 == 和 < 运算符。
容器并非排序的,元素的插入位置同元素的值无关。
(1)vector 头文件 <vector>
动态数组。元素在内存连续存放。随机存取任何元素都能在常数时间完成。在尾端增删元素具有较佳性能(大部分情况是常数时间)。
![]()
(2)deque 头文件<deque>
双向队列。元素在内存连续存放。随机存取任何元素都能在常数时间完成(仅次于vector)。在首尾两端增删元素具有较佳性能(大部分情况是常数时间)。

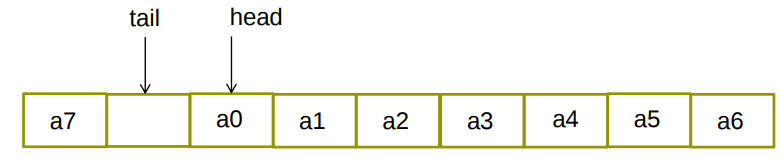
(3)list 头文件<list>
双向链表。元素在内存不连续存放。在任何位置增删元素都能在常数时间完成。不支持随机存取。

push_front 在链表最前面插入
pop_front 删除链表最前面的元素
sort 排序 (list 不支持 STL 的算法 sort)
remove 删除和指定值相等的所有元素
unique 删除所有和前一个元素相同的元素
merge 合并两个链表, 并清空被合并的链表
reverse 颠倒链表
splice 在指定位置前面插入另一链表中的一个或多个元素, 并在另一链表中删除被插入的元素
(4)关联容器
元素是排序的。插入任何元素,都按相应的排序规则来确定其位置。在查找时具有非常好的性能。
通常以平衡二叉树方式实现,插入和检索的时间都是O(log(N))
1)set/multiset 头文件<set>
set 即集合。set中不允许相同元素,multiset中允许存在相同的元素。


template<class Key, class Pred = less<Key>, class A = allocator<Key> > class set { … } //插入set中已有的元素时,忽略插入。
template<class Key, class Pred = less<Key>, class A = allocator<Key> > class multiset { …… };
Pred类型的变量决定了multiset 中的元素,“一个比另一个小”是怎么定义的。 multiset运行过程中,比较两个元素x,y的大小的做法,就是生成一个 Pred类型的变量,假定为op,若表达式op(x,y) 返回值为true,则 x比y小。
Pred的缺省类型是 less<Key>。
template<class T> struct less : public binary_function<T, T, bool> { bool operator()(const T& x, const T& y) { return x < y ; } const; }; //less模板是靠 < 来比较大小的
2)map/multimap 头文件<map>
map与set的不同在于map中存放的元素有且仅有两个成员变量,一个名为first,另一个名为second, map根据first值对元素进行从小到大排序, 并可快速地根据first来检索元素。 map同multimap的不同在于是否允许相同first值的元素。
map/multimap里放着的都是pair模版类的对象,且按first从小到大排序。
若pairs为map模版类的对象, pairs[key] 返回对关键字等于key的元素的值(second成员变量)的引用。若没有关键字为key的元素,则会往pairs里插入一个关键字为key的元素,其值用无参构造函数初始化,并返回其值的引用。
template<class Key, class T, class Pred = less<Key>, class A = allocator<T> > class map { …. typedef pair<const Key, T> value_type; ……. };
template<class Key, class T, class Pred = less<Key>, class A = allocator<T> > class multimap { ...... typedef pair<const Key, T> value_type; ...... }; //Key 代表关键字的类型
multimap中的元素由 <关键字,值>组成,每个元素是一个pair对象,关键字就是first成员变量,其类型是Key。
multimap 中允许多个元素的关键字相同。元素按照first成员变量从小到大 排列,缺省情况下用less定义关键字的“小于”关系。
#include <iostream> #include <map> #include <string> using namespace std; class CStudent{ public: struct CInfo{ int id; string name; }; int score; CInfo info; }; typedef multimap<int, CStudent::CInfo> MAP_STD; int main(){ MAP_STD mp; CStudent st; string cmd; while(cin>>cmd){ if(cmd == "Add"){ cin>>st.info.name>>st.info.id>>st.score; mp.insert(MAP_STD::value_type(st.score, st.info)); //mp.insert(make_pair(st.score,st.info )); 也可以 } else if(cmd == "Query"){ int score; cin >> score; MAP_STD::iterator p = mp.lower_bound(score); if(p != mp.begin()){ --p; score = p->first; //比查询分数低的最高分 MAP_STD::iterator maxp = p; int maxId = p->second.id; for(; p != mp.begin()&& p->first==score; --p){ if(p->second.id > maxId){ maxp = p; maxId = p->second.id; } } //如果上面循环是因为 p == mp.begin()而终止,则p指向的元素还要处理 if(p->first == score){ if(p->second.id > maxId) { maxp = p; maxId = p->second.id; } } cout<<maxp->second.name<<" "<<maxp->second.id<<" "<<maxp->first<<endl; } else cout<<"Nobody."; } } return 0; }
3)成员函数
find: 查找等于某个值 的元素(x小于y和y小于x同时不成立即为相等)
lower_bound : 查找某个下界
upper_bound : 查找某个上界
equal_range : 同时查找上界和下界
count :计算等于某个值的元素个数(x小于y和y小于x同时不成立即为相等)
insert: 用以插入一个元素或一个区间
4)pair模板
template<class _T1, class _T2> struct pair { typedef _T1 first_type; typedef _T2 second_type; _T1 first; _T2 second; pair(): first(), second() { } pair(const _T1& __a, const _T2& __b) : first(__a), second(__b) { } template<class _U1, class _U2> pair(const pair<_U1, _U2>& __p) : first(__p.first), second(__p.second) { } };
(5)容器适配器
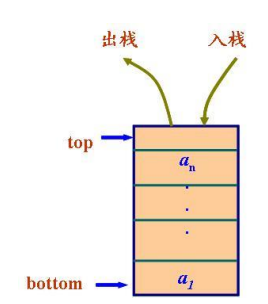
stack 头文件<stack>
栈,是项的有限序列,并满足序列中被删除、检索和修改的项只能是最近插入序列的项(栈顶的项)。后进先出。
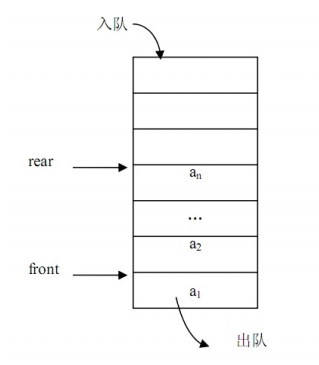
queue 头文件<queue>
队列,插入只可以在尾部进行, 删除、检索和修改只允许从头部进行。先进先出。
priority_queue 头文件<queue>
优先级队列。最高优先级元素总是第一个出列,优先级自己定义。
都有3个成员函数:push:添加一个元素 top:返回栈顶部或队头元素的引用 pop:删除一个元素
容器适配器上没有迭代器:STL中各种排序、查找、边序等算法都不适合容器适配器。
1)stack
可用 vector, list, deque来实现 • 缺省情况下, 用deque实现 • 用 vector和deque实现, 比用list实现性能好
template<class T, class Cont = deque<T> > class stack { … };
void push(const T & x);将x压入栈顶
void pop();弹出(即删除)栈顶元素
T & top();返回栈顶元素的引用. 通过该函数, 可以读取栈顶元素的值, 也可以修改栈顶元素
2)queue
和stack 基本类似, 可以用 list和deque实现,缺省情况下用deque实现
template<class T, class Cont = deque<T> > class queue { …… };
push发生在队尾 。pop, top发生在队头, 先进先出。
3)priority_queue
和queue类似, 可以用vector和deque实现,缺省情况下用vector实现。
priority_queue 通常用堆排序技术实现, 保证最大的元素总是在最前面。执行pop操作时, 删除的是最大的元素;执行top操作时, 返回的是最大元素的引用。默认的元素比较器是 less<T>。
#include <queue> #include <iostream> using namespace std; int main() { priority_queue<double> priorities; priorities.push(3.2); priorities.push(9.8); priorities.push(5.4); while( !priorities.empty() ) { cout << priorities.top() << " "; priorities.pop(); } return 0; } //输出结果: 9.8 5.4 3.2
(6)顺序容器和关联容器都有的成员函数:
begin 返回指向容器中第一个元素的迭代器
end 返回指向容器中最后一个元素后面的位置的迭代器
rbegin 返回指向容器中最后一个元素的迭代器
rend 返回指向容器中第一个元素前面的位置的迭代器
erase 从容器中删除一个或几个元素
clear 从容器中删除所有元素
(7)顺序容器常用的成员函数:
front 返回容器中第一个元素的引用
back 返回容器中最后一个元素的引用
push_back 在容器末尾增加新元素
pop_back 删除容器末尾的元素
erase 删除迭代器指向的元素(可能会使该迭代器失效),或删除一个区间,返回被删除元素后面的那个元素的迭代器
(8)迭代器
用于指向顺序容器和关联容器中的元素;迭代器用法和指针类似,有const和非const两种;通过迭代器可以读取它指向的元素;通过非const迭代器还能修改其指向的元素。
容器类名::iterator 变量名;
容器类名::const_iterator 变量名;
访问一个迭代器指向的元素:*迭代器变量名
迭代器上可以执行 ++ 操作, 以使其指向容器中的下一个元素。如果迭代器到达了容器中的最后一个元素的后面,此时再使用++,就会出错,类似于使用NULL或未初始化的指针一样。
#include <vector> #include <iostream> using namespace std; int main() { vector<int> v; //一个存放int元素的数组,一开始里面没有元素 v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); vector<int>::const_iterator i; //常量迭代器 for( i = v.begin();i != v.end();++i ) cout << * i << ","; cout << endl; vector<int>::reverse_iterator r; //反向迭代器 for( r = v.rbegin();r != v.rend();r++ ) cout << * r << ","; cout << endl; vector<int>::iterator j; //非常量迭代器 for( j = v.begin();j != v.end();j ++ ) * j = 100; for( i = v.begin();i != v.end();i++ ) cout << * i << ","; }
输出结果:
1,2,3,4,
4,3,2,1,
100,100,100,100,
1)双向迭代器
若p和p1都是双向迭代器,则可对p、p1可进行以下操作:
++p, p++ 使p指向容器中下一个元素
--p, p-- 使p指向容器中上一个元素
* p 取p指向的元素
p = p1 赋值
p == p1 , p!= p1 判断是否相等、不等
2)随机访问迭代器
若p和p1都是随机访问迭代器,则可对p、p1可进行以下操作:
双向迭代器的所有操作
p += i 将p向后移动i个元素
p -= i 将p向向前移动i个元素
p + i 值为: 指向 p 后面的第i个元素的迭代器
p - i 值为: 指向 p 前面的第i个元素的迭代器
p[i] 值为: p后面的第i个元素的引用
p < p1, p <= p1, p > p1, p>= p1 :p < p1是指p指向的元素在p1指向元素的前面
3)不同容器的迭代器类别
vector 随机访问
deque 随机访问
list 双向
set/multiset 双向
map/multimap 双向
stack 不支持迭代器
queue 不支持迭代器
priority_queue 不支持迭代器
Note:有的算法,例如sort, binary_search需要通过随机访问迭代器来访问容器中的元素,那么list以及关联容器就不支持该算法!
(9)算法
算法就是一个个函数模板,大多数定义在<algorithm>。
算法通过迭代器来操纵容器中的元素。许多算法可以对容器中的一个局部区间进行操作,因此需要两个参数,一个是起始元素的迭代器, 一个是终止元素的后面一个元素的迭代器,比如排序和查找。
算法可以处理容器,也可以处理普通数组。
大致分为7类:不变序列算法 • 变值算法 • 删除算法 • 变序算法 • 排序算法 • 有序区间算法 • 数值算法
大多重载的算法都是有两个版本的
• 用 “==” 判断元素是否相等, 或用 “<” 来比较大小
• 多出一个类型参数 “Pred” 和函数形参 “Pred op” : 通过表达式 “op(x,y)” 的返回值: ture/false来判断x是否 “等于” y,或者x是否 “小于” y
具体参见:
https://d396qusza40orc.cloudfront.net/pkupop/lectures/Week9/W9-04_%E7%AE%97%E6%B3%95.pdf
https://d396qusza40orc.cloudfront.net/pkupop/lectures/Week9/W9-05_%E7%AE%97%E6%B3%95.pdf
(10)函数对象
若一个类重载了运算符 “()”, 则该类的对象就成为函数对象。
函数对象类模板:头文件<functional>
equal_to greater less …….