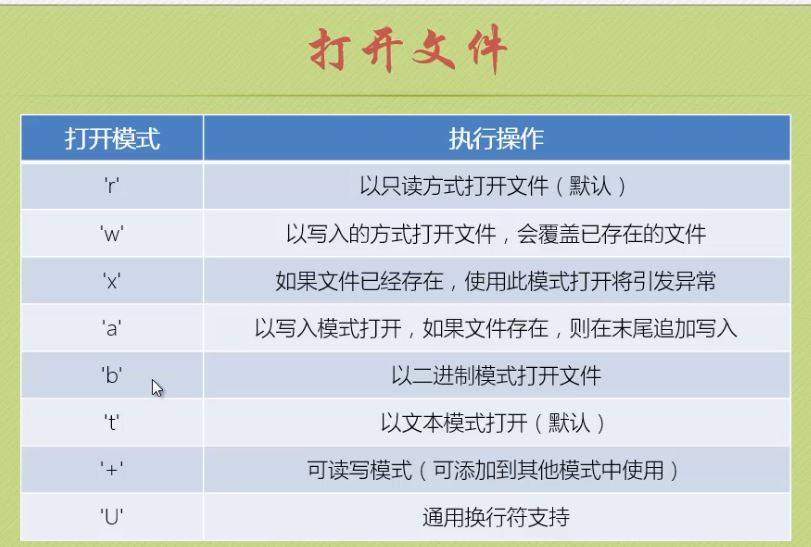
1.打开文件的集中模式:
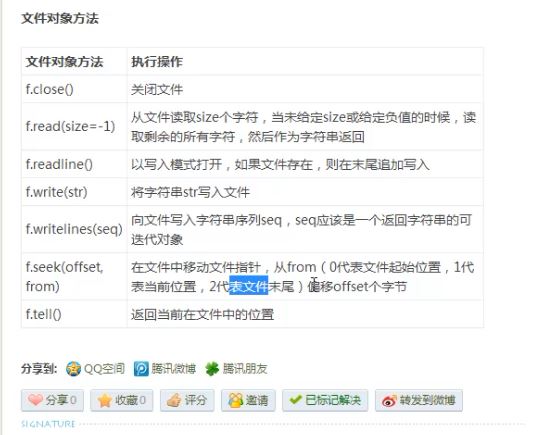
2.文件对象方法:
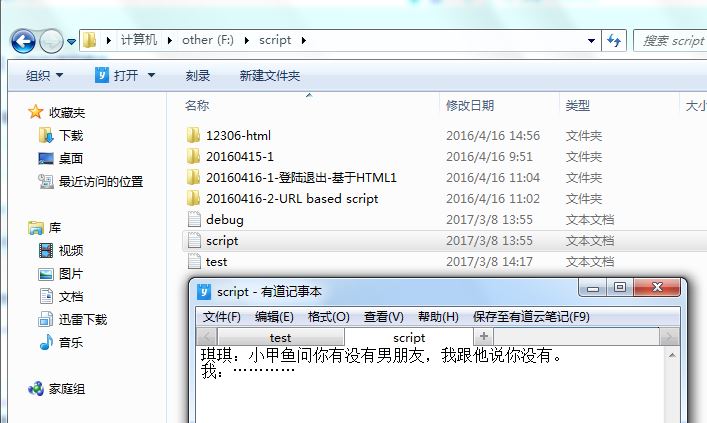
对于文件对象方法的练习代码:
读取F:\script\script.txt位置文件中内容
1 >>> f=open('F:\script\script.txt','rt') #打开文件位置 2 >>> f #查看f相关内容 3 <_io.TextIOWrapper name='F:\script\script.txt' mode='rt' encoding='cp936'> 4 >>> f.read() #读取script.txt文件中内容 5 '琪琪:小甲鱼问你有没有男朋友,我跟他说你没有。 我:…………' 6 >>> f.read() 7 '' #由于上面已经读取过了,所以指针已经指到了末尾,继续读取为空字符
1 >>> f=open('F:\script\script.txt','rt') 2 >>> f.read(5) #读取前5个字符 3 '琪琪:小甲' 4 >>> f.tell() 5 10 6 >>> f.seek(4,0) #重新定位指针指向到位置4 7 4 8 >>> f.readline() #从位置4开始读取本行内容 9 ':小甲鱼问你有没有男朋友,我跟他说你没有。 ' 10 >>> list(f) #继续以列表的形式读取下一行内容 11 ['我:…………'] 12 #用list及for语句打印出‘script.txt’中代码 13 >>> lines=list(f) 14 >>> for each_line in lines: 15 print(each_line) 16 17 18 琪琪:小甲鱼问你有没有男朋友,我跟他说你没有。 19 20 我:………… 21 #只用for语句打印出‘script.txt’中代码 22 >>> for each_line in f: 23 print(each_line) 24 琪琪:小甲鱼问你有没有男朋友,我跟他说你没有。 25 26 我:…………
在某个目录下创建一个新文件并写入相关内容:
>>> f=open('F:\script\test.txt','w') #打开某位置的test.txt,如果此目录下没有此文件,自动创建此文件 >>> f.write('我爱郭琦') #在test.txt中写入的内容 4 #写入test.txt中的字符数 >>> f.close() #只有做此操作write内容才能够真正写入指定文件,不然write的内容会在缓存中
执行以上代码后自动创建的文件‘test.txt’
执行close()操作后,test.txt文件中内容也同时写入:
——————————————————————————————————————————————
文件的花样操作(一个文件肢解成多个文件)
 、
、
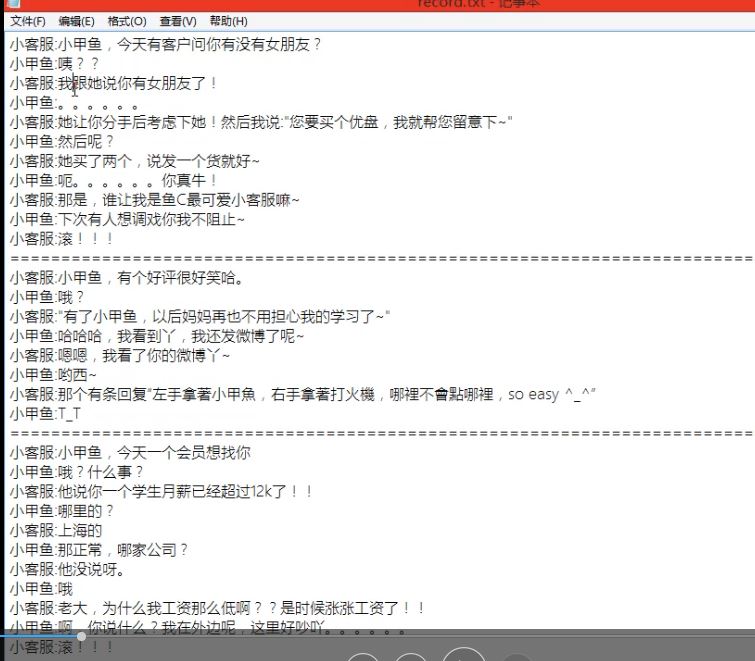
文件内容截图
实现代码:
切片函数学习:

1 f=open('script.txt') 2 #初始化不同身份以方便下面分解对话到不同文件 3 boy=[] 4 girl=[] 5 #初始化一个计算器,来分提取对话的文档名称 6 count=1 7 for each_line in f: 8 if each_line[:6] !='==========': #判断是否是等号如果是进行字符串操作 9 (role,line_spoken)=each_line.split(':',1) #此处用到分解函数参照上图 10 if role=='小甲鱼': 11 boy.append(line_spoken) 12 if role='小客服': 13 girl.append(line_spoken) 14 else: #如果不是等号,进行文件分别保存 15 #按照规则命名个角色对应文件名称 16 file_name_boy='boy_'+str(count)+'.txt' 17 file_name_girl='girl_'+str(count)+'.txt' 18 #打开文件 19 boy_file=open(file_name_boy,'w') 20 girl_file=open(file_name_girl,'w') 21 #写入文件内容 22 boy_file.writelines(boy) 23 girl_file.writelines(girl) 24 #关闭文件 25 boy_file.close() 26 girl_file.close() 27 #分解完一段对话后重新初始化各角色,再次进行对话分解 28 boy=[] 29 girl=[] 30 count+=1 31 #由于第三段末尾没有===,所以需要单独再写一段 32 file_name_boy='boy_'+str(count)+'.txt' 33 file_name_girl='girl_'+str(count)+'.txt' 34 35 boy_file=open(file_name_boy,'w') 36 girl_file=open(file_name_girl,'w') 37 38 boy_file.writelines(boy) 39 boy_file.writelines(boy) 40 41 boy_file.close() 42 girl_file.close()
对于上段代码进行代码简化并优化:
1 def save_file(boy,girl,count): 2 file_name_boy='boy_'+str(count)+'.txt' 3 file_name_girl='girl_'+str(count)+'.txt' 4 5 boy_file=open(file_name_boy,'w') 6 girl_file=open(file_name_girl,'w') 7 8 boy_file.writelines(boy) 9 boy_file.writelines(boy) 10 11 boy_file.close() 12 girl_file.close() 13 14 #封装以下代码 15 def split_file(file_name): 16 f=open('script.txt') 17 #初始化不同身份以方便下面分解对话到不同文件 18 boy=[] 19 girl=[] 20 #初始化一个计算器,来分提取对话的文档名称 21 count=1 22 for each_line in f: 23 if each_line[:6] !='==========': #判断是否是等号如果是进行字符串操作 24 (role,line_spoken)=each_line.split(':',1) 25 if role=='小甲鱼': 26 boy.append(line_spoken) 27 if role='小客服': 28 girl.append(line_spoken) 29 else: #如果不是等号,进行文件分别保存 30 save_file(boy,girl,count) 31 32 #分解完一段对话后重新初始化各角色,再次进行对话分解 33 boy=[] 34 girl=[] 35 count+=1 36 #由于第三段末尾没有===,所以需要单独再写一段 37 save_file(boy,girl,count) 38 f.close() 39 #设置主程序 40 split_file('scipt.txt')
————————————————————————————————————————————————
挂载点:
挂载点实际上就是linux中的磁盘文件系统的入口目录,类似于windows中的用来访问不同分区的C:、D:、E:等盘符。
————————————————————————————————————————————————
OS个函数:




代码:
1 >>> os.sep 2 '\' 3 >>> os.linesep 4 ' ' 5 >>> os.name 6 'nt' 7 >>> os.curdir 8 '.' 9 >>> os.listdir(os.curdir) 10 ['DLLs', 'Doc', 'include', 'Lib', 'libs', 'LICENSE.txt', 'NEWS.txt', 'python.exe', 'pythonw.exe', 'README.txt', 'Scripts', 'tcl', 'Tools'] 11 >>> os.path.basename('E:\A\B\C\sexy.avi') 12 'sexy.avi' 13 >>> os.path.dirname('E:\A\B\C\sexy.avi') 14 'E:\A\B\C' 15 >>> os.path.join('A','B','C') 16 'A\B\C' 17 >>> os.path.join('C:','A','B','C') 18 'C:A\B\C' 19 >>> os.path.join('C:\','A','B','C') 20 'C:\A\B\C' 21 >>> os.path.split('E:\A\SEXY.AVI') 22 ('E:\A', 'SEXY.AVI') 23 >>> os.path.split('E:\A\B\SEXY.AVI') 24 ('E:\A\B', 'SEXY.AVI') 25 >>> os.path.split('E:\A\B\C') 26 ('E:\A\B', 'C') #由于没有文件,所以会自动识别C路径为文件名,这里还是需要人工自动识别才好 27 >>> os.path.splitext('E:\A\B\SEXY.AVI') 28 ('E:\A\B\SEXY', '.AVI') 29 >>> os.path.getatime('D:\各种视频\Python\学习笔记\test_1.py') #得到一个浮点数时间,引入时间模块后可以转化为可识别的时间数字 30 1488955403.494545 31 >>> import time #引入时间模块 32 >>> time.gmtime(os.path.getatime('D:\各种视频\Python\学习笔记\test_1.py')) #英国标准时间gmtime 33 time.struct_time(tm_year=2017, tm_mon=3, tm_mday=8, tm_hour=6, tm_min=43, tm_sec=23, tm_wday=2, tm_yday=67, tm_isdst=0) 34 >>> time.localtime(os.path.getatime('D:\各种视频\Python\学习笔记\test_1.py')) #北京标准时间 35 time.struct_time(tm_year=2017, tm_mon=3, tm_mday=8, tm_hour=14, tm_min=43, tm_sec=23, tm_wday=2, tm_yday=67, tm_isdst=0) 36 >>> os.path.ismount('E:\') #判断是否为挂载点(可以理解为是否为Windows的分区盘,linux中的磁盘文件系统的入口目录) 37 True 38 >>> os.path.ismount('E:\A') 39 False 40 >>>