python模块可以分为内建模块和第三方模块。
内建模块
datetime
引入方式如下:
from datetime import datetime
如上所示,我们就可以引入datetime模块。获取当前时间:
>>> t = datetime.now() >>> print(t) 2018-03-28 16:19:14.755376
这里获取的是本地时间。
由于datetime是一个类,我们可以进行构造,传入相应参数即可:
>>> t = datetime(2018, 3, 28, 16, 20, 30) >>> print(t) 2018-03-28 16:20:30 >>> t = datetime(2018, 3, 28, 16, 20) >>> print(t) 2018-03-28 16:20:00 >>> t = datetime(2018, 3, 28, 16) >>> print(t) 2018-03-28 16:00:00
如上所示,我们可以看到,传入6个参数可以构造出确切的时间,而如果只有5个参数,则s默认为0,;只有4个参数,m也默认为0。但最少要有3个参数表示年月日。
转化为时间戳(timestamp)。 我们之前获取的都是北京事件,比UTC时间(格林威治时间)早了8个小时。但是时间戳在世界的任何一个角落都是相同的,所以时间戳比较常用。而转化也非常简单,调用timestamp()方法即可:
>>> t = datetime.now() >>> print(t) 2018-03-28 16:25:05.835699 >>> t.timestamp() 1522225505.835699
如上,timestamp是浮点数,转化的时间戳是浮点数。
从时间戳转化为当地时间。既然可以从当地时间转化为时间戳,那我们自然也可以从时间戳转化为当地时间:
>>> t.timestamp() 1522225505.835699 >>> stamp = t.timestamp() >>> stamp 1522225505.835699 >>> t = datetime.fromtimestamp(stamp) >>> t datetime.datetime(2018, 3, 28, 16, 25, 5, 835699) >>> print(t) 2018-03-28 16:25:05.835699
如上所示,我们就很轻松地从时间戳转换为了本地时间 ,当然,也可以从时间戳转换为UTC时间,如下:
>>> t = datetime.utcfromtimestamp(stamp) >>> print(t) 2018-03-28 08:25:05.835699
另外,在字符换和当地时间之间也可以相互转换,这里不再介绍。
且时间也可以进行加减的,引入timedelta模块就可以了,如下所示:
>>> from datetime import datetime, timedelta >>> now = datetime.now() >>> print(now) 2018-03-28 16:32:14.057271 >>> print(now + timedelta(hours = 10)) 2018-03-29 02:32:14.057271 >>> print(now + timedelta(days = 10)) 2018-04-07 16:32:14.057271 >>> print(now + timedelta(days = -2)) 2018-03-26 16:32:14.057271 >>> print(now + timedelta(days = 1, hours = 5)) 2018-03-29 21:32:14.057271
如上所示,我们可以看出,引入timedelta模块之后,我们就可以进行时间的加减了。 参数可以是日、时、分、秒等。
Collections
这是python的一个内建模块,提供了很多有用的集合类。
比如namedtupple。这个类的字面意思就很好理解,即命名的tupple。 比如我们希望定义个点,使用p = (1, 2)但是并没有实际的意义,这时我们就可以用namedtupple,如下:
>>> from collections import namedtuple >>> Point = namedtuple('Point', ['x', 'y']) >>> p = Point(1, 2) >>> p.x 1 >>> p.y 2
如上所示,namedtuple是一个函数,用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,根据属性而不是属性来引用tuple的元素。
deque
使用list存储数组时,我们使用list.append()和list.pop()都是从list的末尾进行插入和删除,其他位置的删除都是效率比较低的,而deque的appendleft()方法和popleft()方法可以实现从List的头部插入和删除,效率更高一些。
>>> from collections import deque >>> d = deque([5, 63, 85]) >>> d.appendleft(8) >>> d deque([8, 5, 63, 85]) >>> d.popleft() 8 >>> d deque([5, 63, 85])
如上所示,可见穿件一个deque数据结构,只需要在调用deque()函数,参数为一个list。
defaultDict
我们知道对于一个dict,如果说不存在某一个kv,那么在访问时就会出现KeyError,如下:
>>> k['wayn'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'wayn'
但是如果我们引入了 defaultdict,那么我们就可以指定不存在的情况下怎么返回了,如下:
>>> from collections import defaultdict >>> d = defaultdict(lambda: '不存在这个key') >>> d['wayne'] = 22 >>> d['wayne'] 22 >>> d['hedy'] '不存在这个key'
这样的提示会更加有好一些。
OrderdDict
使用dict时,key是无序的,无法确定key的顺序,而OrderdDict会根据你插入的顺序确定key的顺序,所以OrderdDict是有序的。这里就不举例了。
Counter
counter是一个计数器,它是一个dict,我们可以统计一个字符串中字符出现的次数:
from collections import Counter c = Counter() for i in 'computerscience': c[i] = c[i] + 1 print(c) # Counter({'c': 3, 'e': 3, 'o': 1, 'm': 1, 'p': 1, 'u': 1, 't': 1, 'r': 1, 's': 1, 'i': 1, 'n': 1})
如上所示,显然c[i]的默认值为0,这样,就可以统计每一个字符出现的个数了,最后的结果是一个dict。
另外,Couter的使用更加方便的是直接使用构造函数,传入一个字符串即可,如下:
>>> from collections import Counter >>> c = Counter('computerscience') >>> c Counter({'c': 3, 'e': 3, 'o': 1, 'm': 1, 'p': 1, 'u': 1, 't': 1, 'r': 1, 's': 1, 'i': 1, 'n': 1})
这样会更加简便一些。
base64
在我的这篇文章中介绍了base64的相关知识。简单的说base64就是将二进制文件或者其他文件使用64中字符来表示,但是base64编码之后的字符数是原来的1.3倍左右。 且使用base64编码可以作为cookie等保护性的字符,然后需要使用时再解码就可以了。
python中的base64模块就可以自动完成这个任务而不需要自己查表来完成了,如下所示:
>>> base64.b64encode(b'hedy') b'aGVkeQ==' >>> base64.b64decode('aGVkeQ==') b'hedy'
如上所示,就完成了base64编码和解码的过程。
如果使用base64编码之后作为url的一部分也是可以的,但是base64编码得到的时a-zA-Z0-9/-=,其中的/和=可能会影响正常的url,所以我们可以使用特殊的编码方式即urlsafe_b64encode,这种方式可以将/和=转化为其他的字符_等:
>>> base64.urlsafe_b64encode(b'abcd.dfzfasd89xff') b'YWJjZC5kZnpmYXNkODn_' >>> base64.urlsafe_b64decode('YWJjZC5kZnpmYXNkODn_') b'abcd.dfzfasd89xff'
如上所示,通过这种方式,我们就可以很好的利用base64编码解决问题了。
struct
python中的struct模块提供了bytes和二进制数据之间的转换。 比如struct的pack函数把任意数据类型变成bytes:
>>> import struct >>> struct.pack('>I', 10240099) b'x00x9c@c'
hashlib
在python的hashlib中提供了SHA1和MD5摘要算法。 而摘要算法的作用是通过一个函数将任意长度的数据转换为长度固定的数据串。
举个例子,你写了一篇文章,内容是一个字符串
'how to use python hashlib - by Michael',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'。如果有人篡改了你的文章,并发表为'how to use python hashlib - by Bob',你可以一下子指出Bob篡改了你的文章,因为根据'how to use python hashlib - by Bob'计算出的摘要不同于原始文章的摘要。
因此摘要算法的作用是通过使用摘要算法函数f()对任意长度的数据data生成固定长度的摘要digest,来判断原来的数据是否被修改。并且这个摘要算法是单向的,即可以通过数据生成digest,但是很难通过digest推到原来的数据,所以对原始数据一个bit的修改,就会导致digest的巨大变化。
如下是MD5摘要算法的使用:
>>> import hashlib >>> md5 = hashlib.md5() >>> md5.update('wayne zhu is handsome'.encode('utf-8')) >>> md5.hexdigest() 'a05db2b83183e5ae872644492db99636' >>> md5_1 = hashlib.md5() >>> md5_1.update('wayne zhu is handsome'.encode('utf-8')) >>> md5_1.hexdigest() 'a05db2b83183e5ae872644492db99636' >>> md5_2 = hashlib.md5() >>> md5_2.update('hedy zhu is handsome'.encode('utf-8')) >>> md5_2.hexdigest() '6549b4c53f96b973199e829b9dd0d8e9' >>> md5_3 = hashlib.md5() >>> md5_3.update('wayne zhu is'.encode('utf-8')) >>> md5_3.update(' handsome'.encode('utf-8')) >>> md5_3.hexdigest() 'a05db2b83183e5ae872644492db99636'
如上所示,每次对于一个数据使用md5算法,我们就使用hashlib.md5()进行创建;接着使用update()函数来添加要进行md5算法的字符串; 最后我们使用hexdigest()就可以生成32bit的16进制表示的摘要算法。
并且我们可以发现,将字符串中的几个字符修改之后生成的md5算法发生了很大的改变。另外,hexdigest函数是强制生成16进制的摘要算法,如果是digest呢?如下:
>>> import hashlib >>> md5_4 = hashlib.md5() >>> md5_4.update('wayne zhu is handsome'.encode('utf-8')) >>> md5_4.digest() b'xa0]xb2xb81x83xe5xaex87&DI-xb9x966'
经过比较发现,即使这里我们使用的时digest,但是生成的还是16进制的,并且这里使用x来表示16进制,因为这里是字符串; 如果是数字,一般用0x作为前缀,表示这是16进制的数。
接下来要说的SHA1和md5的用法是完全一样的,只是内部的实现算法有区别,如下所示:
>>> import hashlib >>> sha1 = hashlib.sha1() >>> sha1.update('wayne zhu is handsome'.encode('utf-8')) >>> sha1.hexdigest() '2691709dbb47703edeb943da91a013ee6e5814d0'
如上所示,我们可以看到,sha1的用法的确一模一样,但是sha1算法生成的是160bit的二进制位,这里用了40个16进制位来表示。但sha1的摘要更长,理论上会更加安全一点。而sha256和sha512计算的摘要更长,所以也更安全,但是生成的时间也更慢了,效率也就更低了。如下:
>>> import hashlib >>> sha256 = hashlib.sha256() >>> sha256.update('wayne zhu is handsome'.encode('utf-8')) >>> sha256.hexdigest() 'a14319c1476ccca97be9bdfc6f485ece52e2fa40dc5fa61afc05c2ccd9c33352'
如上是sha256的算法摘要。
>>> import hashlib >>> sha512 = hashlib.sha512() >>> sha512.update('wayne zhu is handsome'.encode('utf-8')) >>> sha512.hexdigest() 'bf3ac43d83af78dd13d5ffaebdc4e2fdd9f080673f8f6bc9bc904fd28182048716469951fc9b88a65d20e8f81c1f62c2fd7c6fce8bcedd45430ffd24603be5a7'
如下是sha512的算法摘要,更为复杂了。
注意:有没有可能对于不同的数据使用算法得到的摘要相同呢?这是有可能的,因为他们都是将无限的数据映射到有限的摘要中,所以一定是有这种情况出现的,这就是碰撞。但是这是非常困难的。
摘要算法应用
任何允许用户登录的网站都会储存用户名和密码,那么如何存储用户名和密码呢,方法当然是存储到数据库表中,如下所示:
| name | password |
|---|---|
| michael | 123456 |
| bob | abc999 |
| alice | alice2008 |
但是,这有一个问题是,这个用户名和密码是存储在数据库中的,如果数据库被黑客攻击,那么黑客就可以获取到所有用户的用户名和密码而直接登录;或者管理员可以获取到后台的这些数据。无论是谁,他们一旦获取就会造成极大的损失,所以,我们一般是将用户登录的密码先使用摘要算法生成摘要,然后存储到数据库中; 当用户进行登录的时候,会再一次的生成摘要,然后和数据库中存储到的摘要进行比对,就可以判断密码生成是否正确了,如下所示:
| username | password |
|---|---|
| michael | e10adc3949ba59abbe56e057f20f883e |
| bob | 878ef96e86145580c38c87f0410ad153 |
| alice | 99b1c2188db85afee403b1536010c2c9 |
那么,使用了摘要算法之后就能保证安全了,这是不一定的,比如黑客获取到了所有的用户名和密码之后,可以对于一些常见的密码推理得到摘要,如111111/222222/8888888等,然后再去匹配,所以,一般网站希望用户将自己的密码设置的尽量复杂一些。不过,为了避免这种问题,开发人员还是可以做一些工作的,比如对于密码加salt,然后再获取摘要,只要黑客不知道我们所加的salt是什么,就很难通过上述方法获得密码。
itertools
itertools模块提供了很多操作迭代对象的函数。
(1)itertools.count()
这个函数可以从某个指定的数开始迭代,如下:
>>> import itertools >>> t = itertools.count(1) >>> for i in t: ... print(i) ... 1 2 3 4 5 6 7 8
这个函数运行到我们按下Ctrl + C才会停止。如果count中接受的是5,那么这个迭代器就是从5开始的了。
(2)itertools.cycle()
这个函数会让传入的参数这个序列无限的循环下去:
>>> import itertools >>> t = itertools.cycle('628') >>> for i in t: ... print(i) ... 6 2 8 6 2 8 6 2 8 6 2 8 6 2
如上所示。
(3)itertools.repeat()
会一直重复下去:
>>> import itertools >>> r = itertools.repeat('abc') >>> for i in r: ... print(i) ... abc abc abc abc abc abc abc abc abc
(4)itertools.takewhile()
之前都是无限重复下去的,但是我们不可能用这么多数据,所以需要在适当的时候截取出来,就要用到itertools.takewhile()函数了,他接受两个参数,第一个参数是一个lambda函数,第二个参数是之前的这些无限itertools:
>>> import itertools>>> r = itertools.count(1) >>> l = itertools.takewhile(lambda x: x < 20, r) >>> l <itertools.takewhile object at 0x000002A73D0AE6C8> >>> for i in l: ... print(i) ... 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
如上所示,通过这个函数,我们就可以运用到实际中了。
(5)itertools.chain()
这个函数可以帮助我们将多个可迭代对象串联起来,得到一个更大的可迭代对象:
>>> import itertools >>> r = itertools.chain('abcd','1234') >>> for i in r: ... print(i) ... a b c d 1 2 3 4
(6)itertools.groupby()
这个函数会将重复的部分自动分组,如下:
>>> import itertools >>> for key,group in itertools.groupby('aaaabbbcccddddd'): ... print(key, list(group)) ... a ['a', 'a', 'a', 'a'] b ['b', 'b', 'b'] c ['c', 'c', 'c'] d ['d', 'd', 'd', 'd', 'd']
通过上面知识点的学习,我们可以求圆周率了:
def pi(N): ' 计算pi的值 ' # step 1: 创建一个奇数序列: 1, 3, 5, 7, 9, ... # step 2: 取该序列的前N项: 1, 3, 5, 7, 9, ..., 2*N-1. # step 3: 添加正负符号并用4除: 4/1, -4/3, 4/5, -4/7, 4/9, ... # step 4: 求和: return 3.14
如下:
import itertools N = 100000000 r = itertools.count(1) l = itertools.takewhile(lambda x: x < N, r) sum = 0 for i in l: if i % 2 == 1: sum = sum + 4/(2 * i - 1) else: sum = sum - 4/(2 * i - 1) print(sum)
这样,在N比较大的时候,我们可以得到一个非常精确的值:
3.141592663589326
urllib
urllib提供了一系列操作url的功能。
get
urllib模块中的request模块可以非常方便的抓取URL内容,也就是发送一个GET请求到指定的页面,然后返回HTTP的响应 。例如对于豆瓣的一个URL进行抓取:https://api.douban.com/v2/book/2129650,并返回响应:
from urllib import request with request.urlopen('https://api.douban.com/v2/book/2129650') as f: data = f.read() print('Status: ', f.status, f.reason) for k, v in f.getheaders(): print('%s: %s' % (k, v)) print('Data:', data.decode('utf-8'))
这里引入了urllib中的request,然后使用request的urlopen函数发送了get请求,这里使用with就可以省去try...finally的书写使得其更为简洁,然后得到的内容就都在f中了。
通过f.read()可以得到get的内容,然后使用f.getheaders()得到响应头的kv对,通过for...in迭代出来即可 。最后打印时,我们使用utf-8的编码方式进行decode即可。最终结果如下:
Status: 200 OK Date: Wed, 28 Mar 2018 14:12:43 GMT Content-Type: application/json; charset=utf-8 Content-Length: 2058 Connection: close Vary: Accept-Encoding X-Ratelimit-Remaining2: 99 X-Ratelimit-Limit2: 100 Expires: Sun, 1 Jan 2006 01:00:00 GMT Pragma: no-cache Cache-Control: must-revalidate, no-cache, private Set-Cookie: bid=5kcAzYhjXJ0; Expires=Thu, 28-Mar-19 14:12:43 GMT; Domain=.douban.com; Path=/ X-DOUBAN-NEWBID: 5kcAzYhjXJ0 X-DAE-Node: sindar7c X-DAE-App: book Server: dae Data: {"rating":{"max":10,"numRaters":16,"average":"7.4","min":0},"subtitle":"","author":["廖雪峰"],"pubdate":"2007","tags":[{"count":21,"name":"spring","title":"spring"},{"count":13,"name":"Java","title":"Java"},{"count":6,"name":"javaee","title":"javaee"},{"count":5,"name":"j2ee","title":"j2ee"},{"count":4,"name":"计算机","title":"计算机"},{"count":4,"name":"编程","title":"编程"},{"count":3,"name":"藏书","title":"藏书"},{"count":3,"name":"POJO","title":"POJO"}],"origin_title":"","image":"https://img3.doubanio.com/mpic/s2552283.jpg","binding":"平装","translator":[],"catalog":"","pages":"509","images":{"small":"https://img3.doubanio.com/spic/s2552283.jpg","large":"https://img3.doubanio.com/lpic/s2552283.jpg","medium":"https://img3.doubanio.com/mpic/s2552283.jpg"},"alt":"https://book.douban.com/subject/2129650/","id":"2129650","publisher":"电子工业出版社","isbn10":"7121042622","isbn13":"9787121042621","title":"Spring 2.0核心技术与最佳实践","url":"https://api.douban.com/v2/book/2129650","alt_title":"","author_intro":"","summary":"本书注重实践而又深入理论,由浅入深且详细介绍了Spring 2.0框架的几乎全部的内容,并重点突出2.0版本的新特性。本书将为读者展示如何应用Spring 2.0框架创建灵活高效的JavaEE应用,并提供了一个真正可直接部署的完整的Web应用程序——Live在线书店(http://www.livebookstore.net)。 在介绍Spring框架的同时,本书还介绍了与Spring相关的大量第三方框架,涉及领域全面,实用性强。本书另一大特色是实用性强,易于上手,以实际项目为出发点,介绍项目开发中应遵循的最佳开发模式。 本书还介绍了大量实践性极强的例子,并给出了完整的配置步骤,几乎覆盖了Spring 2.0版本的新特性。 本书适合有一定Java基础的读者,对JavaEE开发人员特别有帮助。本书既可以作为Spring 2.0的学习指南,也可以作为实际项目开发的参考手册。","price":"59.8"} C:UsersAdministratorDesktop>python foo.py Status: 200 OK Date: Wed, 28 Mar 2018 14:14:17 GMT Content-Type: application/json; charset=utf-8 Content-Length: 2058 Connection: close Vary: Accept-Encoding X-Ratelimit-Remaining2: 98 X-Ratelimit-Limit2: 100 Expires: Sun, 1 Jan 2006 01:00:00 GMT Pragma: no-cache Cache-Control: must-revalidate, no-cache, private Set-Cookie: bid=27IsN2hIcec; Expires=Thu, 28-Mar-19 14:14:17 GMT; Domain=.douban.com; Path=/ X-DOUBAN-NEWBID: 27IsN2hIcec X-DAE-Node: dis5 X-DAE-App: book Server: dae Data: {"rating":{"max":10,"numRaters":16,"average":"7.4","min":0},"subtitle":"","author":["廖雪峰"],"pubdate":"2007","tags":[{"count":21,"name":"spring","title":"spring"},{"count":13,"name":"Java","title":"Java"},{"count":6,"name":"javaee","title":"javaee"},{"count":5,"name":"j2ee","title":"j2ee"},{"count":4,"name":"计算机","title":"计算机"},{"count":4,"name":"编程","title":"编程"},{"count":3,"name":"藏书","title":"藏书"},{"count":3,"name":"POJO","title":"POJO"}],"origin_title":"","image":"https://img3.doubanio.com/mpic/s2552283.jpg","binding":"平装","translator":[],"catalog":"","pages":"509","images":{"small":"https://img3.doubanio.com/spic/s2552283.jpg","large":"https://img3.doubanio.com/lpic/s2552283.jpg","medium":"https://img3.doubanio.com/mpic/s2552283.jpg"},"alt":"https://book.douban.com/subject/2129650/","id":"2129650","publisher":"电子工业出版社","isbn10":"7121042622","isbn13":"9787121042621","title":"Spring 2.0核心技术与最佳实践","url":"https://api.douban.com/v2/book/2129650","alt_title":"","author_intro":"","summary":"本书注重实践而又深入理论,由浅入深且详细介绍了Spring 2.0框架的几乎全部的内容,并重点突出2.0版本的新特性。本书将为读者展示如何应用Spring 2.0框架创建灵活高效的JavaEE应用,并提供了一个真正可直接部署的完整的Web应用程序——Live在线书店(http://www.livebookstore.net)。 在介绍Spring框架的同时,本书还介绍了与Spring相关的大量第三方框架,涉及领域全面,实用性强。本书另一大特色是实用性强,易于上手,以实际项目为出发点,介绍项目开发中应遵循的最佳开发模式。 本书还介绍了大量实践性极强的例子,并给出了完整的配置步骤,几乎覆盖了Spring 2.0版本的新特性。 本书适合有一定Java基础的读者,对JavaEE开发人员特别有帮助。本书既可以作为Spring 2.0的学习指南,也可以作为实际项目开发的参考手册。","price":"59.8"}
上面我们使用的时request.urlopen()方法,而如果我们希望模拟一个请求,我们可以使用request.Request()方法,如下所示:
from urllib import request req = request.Request('http://www.douban.com/') req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25') with request.urlopen(req) as f: print('Status:', f.status, f.reason) for k, v in f.getheaders(): print('%s: %s' % (k, v)) print('Data:', f.read().decode('utf-8'))
如上所示,我们之前使用的是request.urlopen()得到的结果,而这里使用的是request.urlopen(request.request())的结果,也就是之前的函数接受了一个域名作为参数,而这里接受了一个request.Request()作为参数,然后我们使用req.add_header()也可以模仿Ipone手机进行请求,结果如下:
Status: 200 OK Date: Wed, 28 Mar 2018 14:23:39 GMT Content-Type: text/html; charset=utf-8 Content-Length: 11531 Connection: close Vary: Accept-Encoding X-Xss-Protection: 1; mode=block X-Douban-Mobileapp: 0 Expires: Sun, 1 Jan 2006 01:00:00 GMT Pragma: no-cache Cache-Control: must-revalidate, no-cache, private Set-Cookie: bid=6cgMQfk41-I; Expires=Thu, 28-Mar-19 14:23:39 GMT; Domain=.douban.com; Path=/ X-DOUBAN-NEWBID: 6cgMQfk41-I X-DAE-Node: hador1 X-DAE-App: talion Server: dae Strict-Transport-Security: max-age=15552000; X-Content-Type-Options: nosniff Data: <!DOCTYPE html> <html itemscope itemtype="http://schema.org/WebPage"> <head> <meta charset="UTF-8"> <title>豆瓣(手机版)</title> <meta name="viewport" content="width=device-width, height=device-height, user-scalable=no, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0"> <meta name="format-detection" content="telephone=no"> <link rel="canonical" href=" http://m.douban.com/"> <link href="https://img3.doubanio.com/f/talion/05520a911efa802a06abd2263b41ac0e2bf335c6/css/card/base.css" rel="stylesheet"> <meta name="description" content="读书、看电影、涨知识、学穿搭...,加入兴趣小组,获得达人们的高质量生活经验,找到有相同爱好的小伙伴。"> <meta name="keywords" content="豆瓣,手机豆瓣,豆瓣手机版,豆瓣电影,豆瓣读书,豆瓣同城">
这样,我们就得到了豆瓣手机版的html页面。
同样,既然可以发送get请求,也是可以发送post请求的,我们只需要把参数data以bytes的形式传送:
from urllib import request, parse print('Login to weibo.cn...') email = input('Email: ') passwd = input('Password: ') login_data = parse.urlencode([ ('username', email), ('password', passwd), ('entry', 'mweibo'), ('client_id', ''), ('savestate', '1'), ('ec', ''), ('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F') ]) req = request.Request('https://passport.weibo.cn/sso/login') req.add_header('Origin', 'https://passport.weibo.cn') req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25') req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F') with request.urlopen(req, data=login_data.encode('utf-8')) as f: print('Status:', f.status, f.reason) for k, v in f.getheaders(): print('%s: %s' % (k, v)) print('Data:', f.read().decode('utf-8'))
如果成功登陆,获得如下响应:
Status: 200 OK Server: nginx/1.2.0 ... Set-Cookie: SSOLoginState=1432620126; path=/; domain=weibo.cn ... Data: {"retcode":20000000,"msg":"","data":{...,"uid":"1658384301"}}
如果失败:
Data: {"retcode":50011015,"msg":"u7528u6237u540du6216u5bc6u7801u9519u8bef","data":{"username":"example@python.org","errline":536}}
如果更为复杂,我们可以通过一个Proxy访问网站:
proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
with opener.open('http://www.example.com/login.html') as f:
pass
urllib提供的功能就是利用程序去执行各种HTTP请求。如果要模拟浏览器完成特定功能,需要把请求伪装成浏览器。伪装的方法是先监控浏览器发出的请求,再根据浏览器的请求头来伪装,User-Agent头就是用来标识浏览器的。
HTMLParser
如果我们要编写一个搜索引擎,第一步是用爬虫把目标网站的页面抓下来,第二步就是解析该HTML页面,看看页面的内容到底是新闻、图片还是视频。比如第一步已经完成,那么第二步如何解析HTML呢?
python提供了HTMLParser来非常方便的解析HTML,只需要几行代码。
找一个网页,例如https://www.python.org/events/python-events/,用浏览器查看源码并复制,然后尝试解析一下HTML,输出Python官网发布的会议时间、名称和地点。
from html.parser import HTMLParser from urllib import request import re class MyHTMLParser(HTMLParser): flag = 0 res = [] is_get_data = 0 def handle_starttag(self, tag, attrs): if tag == 'ul': fora attr in attrs: if re.match(r'list-recent-events', attr[1]): self.flag = 1 if tag == 'a' and self.flag == 1: self.is_get_data = 'title' if tag == 'time' and self.flag == 1: self.is_get_data = 'time' if tag == 'span' and self.flag == 1: self.is_get_data == 'addr' def handle_endtag(self, tag): if self.flag == 1 and tag == 'ul': self.flag = 0 def handle_data(self, data): if self.is_get_data and self.flag == 1: if self.is_get_data == 'title': self.res.append({self.is_get_data: data}) else: self.res[len(self.res) - 1][self.is_get_data] = data self.is_get_data = None parser = MyHTMLParser() with request.urlopen('https://www.python.org/events/python-events/') as f: data = f.read().decode('utf-8') parser.feed(data) for item in MyHTMLParser.res: print('------------') for k,v in item.items(): print('%s : %s' % (k, v))
最终的结果如下所示:
------------ title : PythonCamp 2018 - Cologne time : 07 April – 09 April ------------ title : PyCon IT 9 time : 19 April – 23 April ------------ title : PyDays Vienna time : 04 May – 06 May ------------ title : GeoPython 2018 time : 07 May – 10 May ------------ title : PyCon US 2018 time : 09 May – 18 May ------------ title : DjangoCon Europe 2018 time : 23 May – 28 May ------------ title : PyCon SK 2018 time : 09 March – 12 March ------------ title : PyCon PH 2018 time : 24 Feb. – 26 Feb.
如上所示,搜索引擎也大致是这个原理,就是先获取到所有网页的HTML,然后在通过HTMLParser来获取到相关的内容 ,如果符合则展示在用户的浏览器中。 这便就是爬虫了。
常用第三方模块
Pillow
PIL,即Python Imaging LIbrary, 即python图画库,是python平台事实上的图片处理标准库,但是PIL时间很长了,开发者又新出了Pillow代替之,如果已经安装了Anaconda,那么就已经包含了Pillow了。否则需要通过pip安装:
pip install pillow
使用pillow操作图像,只需要如下所示:
from PIL import Image #使用Image.open打开一个图片,才能操作 im = Image.open('c:/users/administrator/desktop/001.png') #获得图像尺寸 w, h = im.size #将图片缩小50% im.thumbnail((w//10, h//10)) #这里接受的是一个tuple #保存图片 im.save('c:/users/administrator/desktop/010.png')
如上所示,引入Image类,然后使用open方法打开一个文件,接着通过size属性获取到大小,使用thumbnail接受一个tuple可以缩小图片,通过save方法保存图片。
另外,我们还可以对图片进行filter处理,如下:
from PIL import Image, ImageFilter # 打开一个jpg图像文件,注意是当前路径: im = Image.open('test.jpg') # 应用模糊滤镜: im2 = im.filter(ImageFilter.BLUR) im2.save('blur.jpg', 'jpeg')
于是,我们可以发现python的能力还是很强大的,可以处理操作系统的任何操作,如删除、添加、修改文件,这里还可以做到ps的效果。
我们经常可以在网站上看到验证码图片,这里,我们就可以创建一个验证码图片:
from PIL import Image, ImageDraw, ImageFont, ImageFilter import random #产生随机字母 def rndChar(): return chr(random.randint(65, 90)) #产生随机颜色1,用于填充背景 def rndColor(): return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255)) #产生随机颜色2,用于填充文字,以便和背景区别开来 def rndColor2(): return (random.randint(32, 69), random.randint(32, 69), random.randint(32, 69)) #图片的宽和高 height = 100 width = height * 4 #创建一个图片 image = Image.new('RGB', (width, height), (255, 255, 255)) #创建Font对象 font = ImageFont.truetype('c:/windows/fonts/Arial.ttf', 48) #创建Draw对象,在之前创建的image图片上进行绘画 draw = ImageDraw.Draw(image) #填充每一个像素 for x in range(width): for y in range(height): # 对每个点填充颜色,使用了draw对象 draw.point((x, y), fill=rndColor()) #文字填充,使用了draw对象 for t in range(4): draw.text((height * t + 40, 25), rndChar(), font=font, fill=rndColor2()) #模糊处理 image = image.filter(ImageFilter.BLUR) image.save('c:/users/administrator/desktop/code.png')
如上所示,这里使用random模块产生随机数是非常方便的,然后使用Image可以创建图片,使用ImageDraw对象可以对图片进行绘画,最后就可以获得验证码图片了:
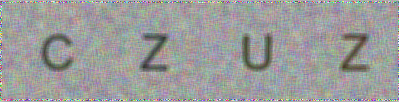
上面使用的是英文,如果我们希望生成简体中文也是可以的,我们在c:/windows/fonts下面找到合适的ttf文件,如Dent.ttf文件,替换掉Arial.ttf文件,然后在rndChar()的内容修改为:
#产生随机汉字 def rndHan(): return chr(random.randint(28000, 30000))
这样,我们就可以得到汉字了,如下所示:
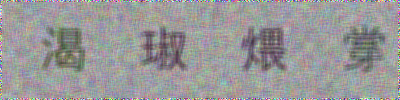
Requests模块
之前使用了urllib模块,但是更为方便的是Request模块,处理url资源更为方便。如果已经安装了anaconda,那么Request模块就已经存在了,否则需要通过pip install requests进行安装。
注意:之前的urllib时内建库,而这里的requests模块是第三方库,这个库更加方便使用。
>>> import requests >>> r = requests.get('https://www.douban.com/') >>> r.status_code 200 >>> r.text '<!DOCTYPE HTML> <html lang="zh-cmn-Hans" class=""> <head> <meta charset="UTF-8"> <meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。"> <meta name="keywords" content="豆瓣,广播,登 陆豆瓣"> <meta property="qc:admins" content="2554215131764752166375" /> <meta property="wb:webmaster" content="375d4a17a4fa24c2" /> <meta
如上所示,我们引入requests模块之后,直接就可以发送一个get请求,然后通过status_code属性得到状态码,通过text属性获得内容。
另外,对于get请求,我们可以加入第二个参数,params,这是一个dict,如下:
>>> r = requests.get('https://www.baidu.com/s', params={'wd': 'python'}) >>> r.status_code 200 >>> r.url 'https://www.baidu.com/s?wd=python'
另外,我们还可以通过r.encoding来获得当前的编码格式。get请求中的第二个参数也可以是headers,即添加请求头,如下所示:
>>> r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'})
如果要发送post请求,只需要requests.post()方法即可,第一个参数为主机名,第二个参数为data,其值是一个dict,
>>> r = requests.post('https://accounts.douban.com/login', data={'form_email': 'abc@example.com', 'form_password': '123456'})
chardet库
如果安装了anaconda,那么chardet就自动在其中了。否则就要再自行安装: pip install chardet。
使用也非常简单,就是chardet.detect()进行检测,如下所示:
>>> import chardet >>> chardet.detect(b'hello world!') {'encoding': 'ascii', 'confidence': 1.0, 'language': ''} >>> data = '白日依山尽,黄河入海流'.encode('gbk') >>> chardet.detect(data) {'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'} >>> data = '白日依山尽,黄河入海流'.encode('utf-8') >>> chardet.detect(data) {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''} >>> data = '最新の主要ニュース'.encode('euc-jp') >>> chardet.detect(data) {'encoding': 'EUC-JP', 'confidence': 0.99, 'language': 'Japanese'}
如上所示,我们通过chardet.detect()进行检测编码,就可以合理的使用相应的解码函数进行解码而不会出错、并且可以依据编码方式解决其他问题了。
psutil库
用python来编写脚本简化日常的运维工作是Python的一个重要用途。在linux下,有许多系统命令可以让我们实时监控系统运行的状态,如ps、top、free等等,要获取这些胸信息,python可以通过subprocess模块低啊用并获取结果,但麻烦。 而python中使用psutil第三方模块获取系统信息会很方便,是系统管理员和运维小伙伴不可或缺的必备模块。
这个库中有很多方法可以直接查看cpu、内存等内容,也可以获取到所有的进程线程,控制线程进程,所以做运维的,一般还是很需要psutil库的。
virtuallenv
在开发Python应用程序的时候,系统安装的Python3只有一个版本:3.4. 所有的第三方的包都会被Pip安装到python3的site-packages目录下。 如果我们要开发多个应用程序,那这些应用程序就会提供一个python.
就是系统的python3,但是如果应用A需要jinja2.7,而应用B需要jinja2.6怎么办?这样情况下,每个应用可能需要拥有一套‘独立’的python运行环境。而Virtualenv就是用来为一个应用创建一套“隔离”的python运行环境。这样就可以解决不同版本的冲突问题了。