浏览器介绍
如今,浏览器格局基本上是五分天下,分别是:IE、Firefox、Safari、Chrome、Opera,而浏览器引擎就更加集中了,主要是四大巨头:IE的浏览器排版引擎Trident,目前随IE10发布了Trident6.0;Mozilla的排版引擎Gecko,今年4月2号发布了Gecko21预览版,稳定版本为Gecko20;Google Chrome和Apple Safari使用的是WebKit引擎,它已经成为市场占用率最高的排版引擎;另外还有Opera的Presto引擎,不过在今年的2月13号,Opera Software宣布未来产品将以Webkti和V8为主,逐步放弃基于Presto引擎产品。也就是说,如今的浏览器排版引擎基本上是三分天下。
据国外媒体报道,Google当地时间周三宣布将放弃渲染引擎WebKit,开发名为Blink的渲染引擎。Opera也宣布将采用Blink。主要的原因是,与其他WebKit 浏览器相比,Chromium 使用的是一个不同的多过程架构体系。在过去多年为了支持多个架构体系,WebKit 和 Chromium 社区面临的问题越来越复杂,延缓了创新的整体速度。

浏览器的功能
浏览器的主要功能是将用户选择的web资源用网页的形式显示出来,这些资源包括:文字、图像、等其他信息,而web资源都是通过URI(uniform resource identifier)来定位。大部分网页都是HTML格式,网页的样式都是使用CSS来定义,相关的规范由W3C组织来进行制定和维护。但是,这些年来,浏览器开发商纷纷为了抢占市场及其扩展强化自己的产品,对相关的规范并不完全遵守,这也导致了如今web领域严重的兼容性问题。
浏览器内部结构
①、用户界面(UI) - 包括菜单栏、工具栏、地址栏、后退/前进按钮、书签目录等,也就是能看到的除了显示页面的主窗口之外的部分;
②、浏览器引擎(Rendering engine) - 也被称为浏览器内核、渲染引起,主要负责取得页面内容、整理信息(应用CSS)、计算页面的显示方式,然后会输出到显示器或者打印机;
③、JS解释器 - 也可以称为JS内核,主要负责处理javascript脚本程序,一般都会附带在浏览器之中,例如chrome的V8引擎;
④、网络部分 - 主要用于网络调用,例如:HTTP请求,其接口与平台无关,并为所有的平台提供底层实现;
⑤、UI后端 - 用于绘制基本的窗口部件,比如组合框和窗口等。
⑥、数据存储 - 保存类似于cookie、storage等数据部分,HTML5新增了web database技术,一种完整的轻量级客户端存储技术。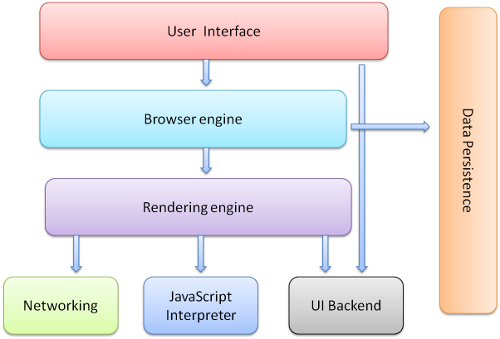
值得注意的是,IE只为每个浏览器窗口启用单独的进程,而chrome浏览器却为每个tab页面单独启用进程,也就是每个tab都有独立的渲染引擎实例。
渲染引擎
渲染并不是计算机领域的术语,而是来自于绘画领域,绘画时经常使用水墨或者淡色涂抹画布,以烘托物象,分出阴阳向背,主要用来加强艺术效果,明代 - 杨慎《艺林伐山·浮渲梳头》:“画家以墨饰美人鬢髮谓之渲染。”在这里就不扯远了,在电脑绘图中, 是指软件从模型生成图像的过程,包括几何、视点、纹理、和照明信息等。
浏览器的渲染引擎也主要是干这勾当的,负责显示HTML文档、XML文档以及图片、动画等信息,还可以借组浏览器的一些差距显示其他数据类型,例如:flash、pdf等。
渲染的主要步骤
渲染引擎首先通过网络部分获取request响应的文档内容,一般以8K为单位分块进行。解析HTML用以构建DOM树结构 -> 构建Render树 -> Render树的布局 -> 绘制Render树。
渲染引擎解释HTML文档,首先将标签转换成DOM树中的DOM node;接着,解释对应的CSS样式文件信息,而这些样式信息以及HTML中可见的指令(<b></b>etc)将被用来构建另外的Render树。这棵树主要由一些包含颜色和宽高等属性组成的矩形组成,它们将依次按顺序显示在屏幕上。
待Renter树构建完成,将执行布局过程,确定每个节点在屏幕上对应的坐标,及其覆盖和回流情况等,然后浏览器会遍历Renter树,并使用UI后端层绘制每个节点。这整个过程都是逐步进行的,HTML内容显示一部分,将构建和布局一部分Renter树,就先显示出来。也就是解释完一部分内容就显示一部分出来,而不是等着HTML内容解释完成才进行构建Renter树,同时,还有可能通过网络层进行下载其余的内容。
解析与DOM树构建
解析就是将一个文档转换成指定的结构,解析的结构通常是表达文档结构的节点树。例如:num1 + num2 * num3,可以解析成如下的DOM树。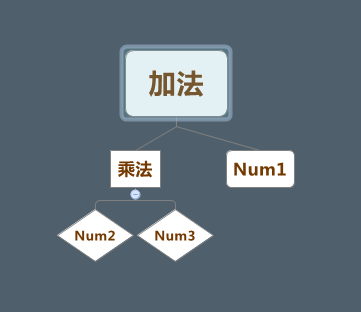
文法
解析基于文档依据的语法规则 —— 文档的语言和格式,每种可以被解析的格式必须是具有由词法及其语法规则组成的特定文法。
词法
解析可以分为两个过程:语法分析和词法分析。
词法分析就是将输入分解成符号,也可以理解为将字符序列转换为单词序列的过程,进行词法分析的程序或者函数叫做词法分析器(Lexical analyzer) - Lexer,一般以函数的形式存在,供语法分析器调用。这里说的单词序列也就是字符串序列,是构成源代码的最小单位。从输入字符流中生成单词的过程叫做单词话,在这个过程中,词法分析器会对单词进行分类,但通常不关心单词之间的关系,那属于语法分析的范畴,不会出现越俎代庖的情形。
语法分析(Syntactic analysis)是根据某种给定的形式文法对由单词序列构成的文本进行分析并确定其语法结构的一个过程。语法分析器主要作用就是进行语法检查、并且构建由单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的结构)。
基本的流程:document -> Lexical analyzer -> Syntactic analysis -> Parse Tree。解析过程是迭代的,解析器从词法分析器处获得一个新的符号,并试着用这个符号匹配一条语法规则,若匹配则添加到解析树种,否则先暂时保存该符号,并继续匹配下一个符号;若最终都没有找到可以匹配的规则,解析器就会抛出一个异常,一般是语法错误。
转换
解析树并不是最终的结果,还需要进行格式转换。例如编译的流程:Source Code -> Parsing ->parse Tree -> Translation ->Machine Code。
CSS解析
CSS属于上下文无关文法,可以按照前面所述的解析器解析,CSS规范定义了CSS词法及语法文法。
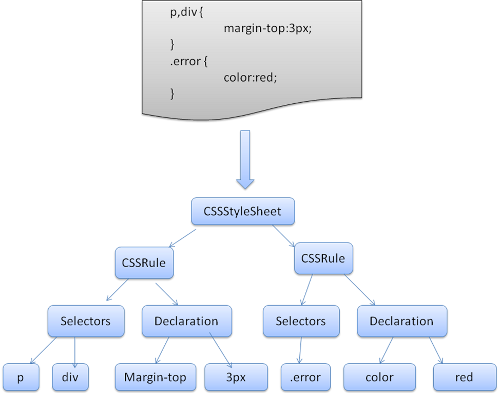
CSS解析生成器将每个CSS文件解析城样式表对象,每个对象包含CSS规则,CSS规则对象包含选择器和声明对象,以及其他一些符合CSS语法的对象。如上图案例所示。
脚本处理和CSS顺序
web的模式是同步的,解析到一个script标签立即解析执行脚本,并阻塞文档的解析直到脚本执行完成。如果脚本是外引的,则网络必须先请求到这个资源 —— 这个过程也是同步的,阻塞文档的解析直到资源被请求到。不过,开发者可以将脚本标示为defer,以使其不阻塞文档的正常解析,并在文档的解析完成后执行。Html5增加了标记脚本为异步的选项,以使脚本的解析执行可以使用另一个线程。
预解析
hrome和Firefox进行了解析的优化,当执行脚本时,另一个线程解析剩余的文档,并加载后面需要通过网络加载的资源。这种方式可以使用资源并行加载,从而使整体速度加快。但是,预解析并不改变DOM树,它只是解析外部资源的引用,例如:外部脚本、样式表、图片等。
理论上,样式表的解析并不改变DOM树,但是脚本可能在文档的解析过程中请求样式信息,假如样式信息还没有加载和解析,脚本将得到错误的信息,显然这会导致很多问题。Chrome只在当脚本试图访问可能被未加载的样式表所影响的特定样式属性时才会阻塞脚本。
渲染树的构建
当DOM树构建完成,又可是构建另一棵 —— 渲染树。渲染树由元素显示序列中的可见元素组成,是文档的可视化表示,构建这棵树是为了以正确的顺序绘制文档内容。
渲染树和DOM树的关系
渲染对象和DOM元素是相对应,但这种关系关系不是一对一的,不可见的DOM元素不会被插入渲染树之中。例如:display为none,但是visibility为hidden的元素却将出现在渲染树种,因为它需要渲染,只是不显示在屏幕上而已。
另外还有一些DOM元素对应几个可见的对象,例如:select元素,它是个相对复杂结构的元素,由三个渲染对象组成:显示区域、下拉列表、按钮。同样,当文本输入因为宽度不够而折行时,新增的行将作为额外的渲染元素被添加。
还有一些渲染对象和应当对应的DOM节点不在两棵树相同的位置,例如:浮动和绝对定位的元素在正常流之外,渲染树上标识出真实的结构,并用一个占位结构标识出它们原来的位置。
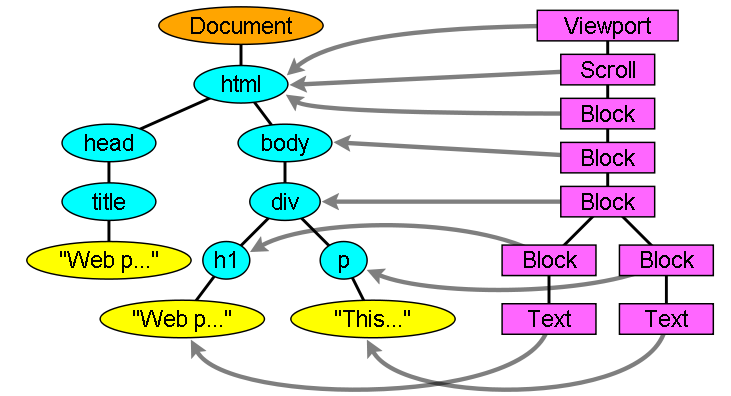
处理html和body标签将构建渲染树的根,这个根渲染对象对应被css规范为containing block的元素,包含着其他所有块元素的顶级块元素。它的大小就是viewport,Firefox称之为viewPortFrame,WebKit称之为RenderView,也就是文档对应的渲染对象。
样式计算
创建渲染树需要计算出每个渲染对象的可视属性,这可以通过计算每个元素的样式属性而得到。样式包括各种来源的样式表,包括行内样式表、外部样式表等。计算样式数据量比较大,不进行优化的话,寻找每个元素匹配的规则会导致性能问题,为每个元素查找匹配的规则都需要遍历整个规则表,这个过程有很大的工作量。
我们来看一下浏览器如何处理这些问题:
共享样式数据(Sharing style data)
WebkKit节点引用样式对象(渲染样式),某些情况下,这些对象可以被节点间共享,这些节点需要是兄弟或是表兄弟节点,并且:
1. 这些元素必须处于相同的鼠标状态(比如不能一个处于hover,而另一个不是)
2. 不能有元素具有id
3. 标签名必须匹配
4. class属性必须匹配
5. 对应的属性必须相同
6. 链接状态必须匹配
7. 焦点状态必须匹配
8. 不能有元素被属性选择器影响
9. 元素不能有行内样式属性
10. 不能有生效的兄弟选择器,webcore在任何兄弟选择器相遇时只是简单的抛出一个全局转换,并且在它们显示时使整个文档的样式共享失效,这些包括+选择器和类似:first-child和:last-child这样的选择器。
Firefox规则树(Firefox rule tree)
Firefox用两个树用来简化样式计算-规则树和样式上下文树,WebKit也有样式对象,但它们并没有存储在类似样式上下文树这样的树中,只是由Dom节点指向其相关的样式。

样式上下文包含最终值,这些值是通过以正确顺序应用所有匹配的规则,并将它们由逻辑值转换为具体的值,例如,如果逻辑值为屏幕的百分比,则通过计算将其转化为绝对单位。样式树的使用确实很巧妙,它使得在节点中共享的这些值不需要被多次计算,同时也节省了存储空间。
所有匹配的规则都存储在规则树中,一条路径中的底层节点拥有最高的优先级,这棵树包含了所找到的所有规则匹配的路径(译注:可以取巧理解为每条路径对 应一个节点,路径上包含了该节点所匹配的所有规则)。规则树并不是一开始就为所有节点进行计算,而是在某个节点需要计算样式时,才进行相应的计算并将计算 后的路径添加到树中。
我们将树上的路径看成辞典中的单词,假如已经计算出了如下的规则树:

假如需要为内容树中的另一个节点匹配规则,现在知道匹配的规则(以正确的顺序)为B-E-I,因为我们已经计算出了路径A-B-E-I-L,所以树上已经存在了这条路径,剩下的工作就很少了。
绘制(Painting)
绘制阶段,遍历渲染树并调用渲染对象的paint方法将它们的内容显示在屏幕上,绘制使用UI基础组件,这在UI的章节有更多的介绍。
全局和增量
和布局一样,绘制也可以是全局的——绘制完整的树——或增量的。在增量的绘制过程中,一些渲染对象以不影响整棵树的方式改变,改变的渲染对象使其在屏 幕上的矩形区域失效,这将导致操作系统将其看作dirty区域,并产生一个paint事件,操作系统很巧妙的处理这个过程,并将多个区域合并为一个。 Chrome中,这个过程更复杂些,因为渲染对象在不同的进程中,而不是在主进程中。Chrome在一定程度上模拟操作系统的行为,表现为监听事件并派发 消息给渲染根,在树中查找到相关的渲染对象,重绘这个对象(往往还包括它的children)。
绘制顺序
css2定义了绘制过程的顺序——http://www.w3.org/TR/CSS21/zindex.html。这个就是元素压入堆栈的顺序,这个顺序影响着绘制,堆栈从后向前进行绘制。
一个块渲染对象的堆栈顺序是:
1. 背景色
2. 背景图
3. border
4. children
5. outline
动态变化
浏览器总是试着以最小的动作响应一个变化,所以一个元素颜色的变化将只导致该元素的重绘,元素位置的变化将大致元素的布局和重绘,添加一个Dom节 点,也会大致这个元素的布局和重绘。一些主要的变化,比如增加html元素的字号,将会导致缓存失效,从而引起整数的布局和重
渲染引擎的线程
渲染引擎是单线程的,除了网络操作以外,几乎所有的事情都在单一的线程中处理,在Firefox和Safari中,这是浏览器的主线程,Chrome中这是tab的主线程。
网络操作由几个并行线程执行,并行连接的个数是受限的(通常是2-6个)。
事件循环
浏览器主线程是一个事件循环,它被设计为无限循环以保持执行过程的可用,等待事件(例如layout和paint事件)并执行它们。
参考文章:
①、http://www.html5rocks.com/en/tutorials/internals/howbrowserswork/