探索vue源码之缓存篇
一、从链表说起
首先我们来看一下链表的定义:
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)
其中的双向链表是我们今天的主角:
双向链表也叫双链表。双向链表中不仅有指向后一个节点的指针,还有指向前一个节点的指针。这样可以从任何一个节点访问前一个节点,当然也可以访问后一个节点,以至整个链表。一般是在需要大批量的另外储存数据在链表中的位置的时候用。
图示如下

想象一群人手拉手站成一排,除了队头跟队尾,可以根据每个人的左手以及右手找到排在其左边或者右边的人,这也可以看成一种双向链表
而在vue.js中,作者正是利用类似双向链表的方式实现缓存的利用
二、LRU算法
在缓存中,利用类似双向链表来管理缓存并不难的。难的是如何更加高效的管理缓存,如何在缓存达到其最大内存空间,删除程序中最不常用的变量,而不是随机删除,造成最常用的变量被误删的情况。
vue.js中采用LRU算法来实现缓存的高效管理。
LRU是Least Recently Used的简称,具体内容可以查看GitHub,其有以下优点:
-
基于双向链表改变缓存对象中entry的排序,复杂度低
-
缓存对象有一个head(最近最少使用的项)和一个tail(最近最多使用的项)
-
head和tail都是entry,一个entry可能会有一个newer entry以及一个older entry(双向链接,older entry更接近head,newer entry更接近tail)
-
使用一个key就可以遍历这个缓存对象,也就意味着只有o(1)的复杂度,内存消耗非常小
可以通过下面的图来更好的理解LRU算法:

如果缓存达到最大,那么每次只需要将head删除就行了,保证了删除的项是最不常用的项
还是拿站成一排的人来举例。
有两个指示牌,上面分别写着tail以及head。head指向队伍的第一个人,tail指向队伍的最后一个人。
假设队伍有10个人,按照队伍的排列从队首到队尾依次编号a b c d ··· j,head指向a,tail指向j。
下面分成五种情况来说明队伍的变化:
-
如果叫到a(使用了数组里面第一个变量),就将a放到队尾,再手拉手重新组成一个新的队伍。并将原来指向j的tail现在指向a。再让原来指向a的head指向现在队伍的第一个人b
-
如果叫到b c d ··· i之间任何一个人,则将其从队伍中抽出,放到队尾,重新排队,再改变tail的指向为这个人
-
如果叫到j,则保持队伍不变
-
队伍达到最大人数,则去掉head指向的编号a,并改变head指向编号b,再在队尾增加一个人,假定编号为k,最后则将tail指向编号k
-
队伍没有达到最大人数,需要增加队伍人数。只需要在队尾增加编号为k的人。再将tail指向编号k
三、源码分析
我们可以通过一张图来先简单理解作者的数据结构:

作者在caches对象的_keymap里面保存所需要缓存的变量,通过older以及newer这两个属性来实现双向链表。older指向其前一个对象,newer指向其后一个对象。通过这两个属性,将缓存中的变量连接起来。
以上图举例:
缓存caches这个对象中保存了三个变量:key1、key2、key3。
-
header指向key1
-
tail指向key2
指向如下:
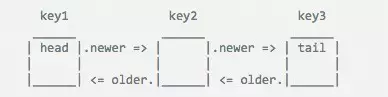
下面我们来看作者对这些数据的处理所使用的方法
文件位置:src/cache.js
首先export构造函数Cache

接下来作者在Cache的原型链上面分别定义了:
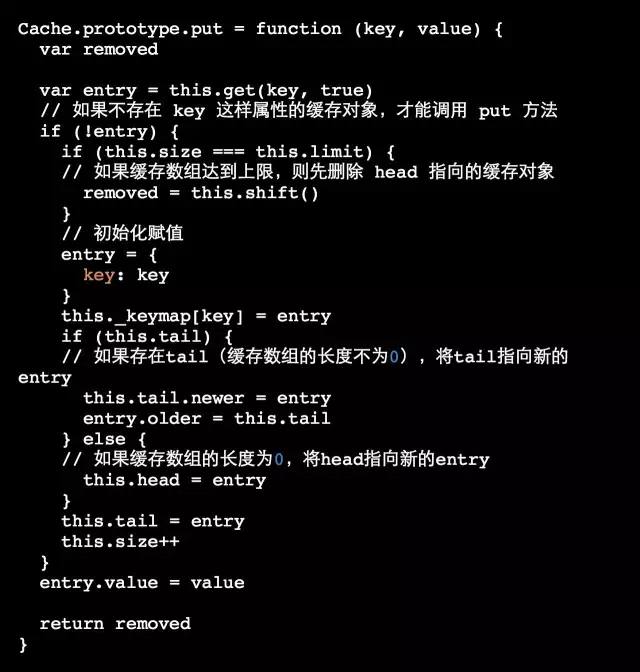
put:在缓存中加入一个key-value对象,如果缓存数组已经达到最大值,则返回被删除的entry,即head,否则返回undefined
shift:在缓存数组中移除最少使用的entry,即head,返回被删除的entry。如果缓存数组为空,则返回undefined
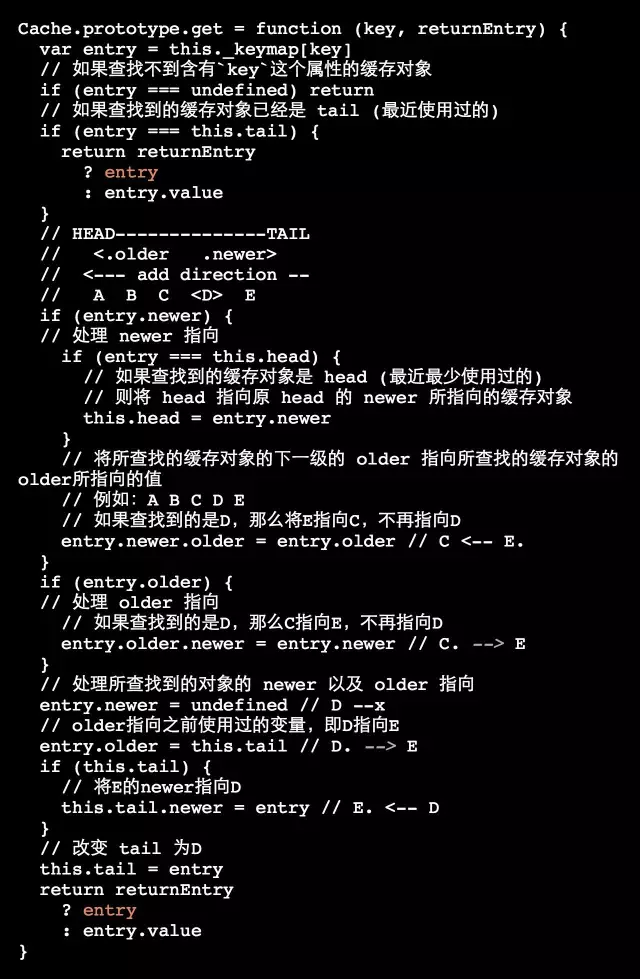
get:将key为传入参数的缓存对象标识为最常使用的entry,即tail,并调整双向链表,返回改变后的tail。如果不存在key为传入参数的缓存对象,则返回undefined
a) get:
b) put:
c) shift:

四、后记
从整个的代码来看,需要学习的不仅仅是LRU算法,作者的对于Object的处理方式也值的我们评味一番。
没有选择去遍历entry,选择通过在Cache内增加一个_keymap属性,通过这个属性来管理entry,实现key与newer、older状态的分离,减少代码的复杂度