Seq2Path: Generating Sentiment Tuples as Paths of a Tree
Seq2Path:生成情感元组作为树的路径
Author Information:Yue Mao, Yi Shen, Jingchao Yang, Xiaoying Zhu, Longjun Cai
Alibaba Group
论文地址:https://aclanthology.org/2022.findings-acl.174.pdf
摘要
最近利用生成的方式来解决方面级情感分析任务的方法虽然通过将输出转化情感元组的序列形式从而取得了一些很好的结果,但是情感元组的顺序在文本中并不是显示存在的,而且当前时刻下元组的生成也不应依赖于先前的元组。因此在这篇文章中,作者提出了一种新的生成方式:Seq2Path,该方式将情感元组的生成顺序转化为树的路径。该方式不仅可以有效的应对1对n的问题(如一个方面实体对应多个意见词),而且每个路径的生成都独立而不彼此依赖。在训练阶段,作者计算了Seq2Seq模型在路径上的平均损失。在推理阶段,作者应用了带约束的束搜索(beam search)。在此基础上,通过引入附加的token自动选择有效地路径,基本上在ABSA的各个子任务当中均取得了最好的结果。
1引言
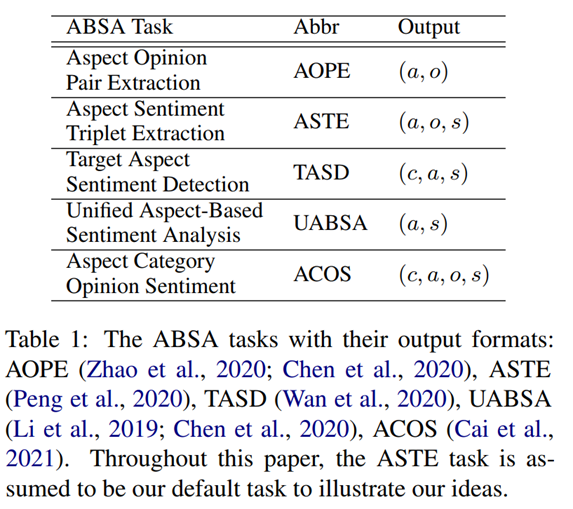
ABSA任务
方面级情感分析(ABSA)是一个经典的研究主题并持续受到关注,ABSA的任务旨在提取情感元组元素的方面项(a)、观点项(o)、方面分类(c)、情感极性(s)。(Zhang et al., 2021b)将方面情感分析的任务定义为以下几种:方面观点对提取(AOPE)、方面情感元组提取(ASTE)、目标方面情感检测(TASD)、统一方面级情感分析(UABSA)、方面分类观点情感(ACOS),输出的格式如table 1。对于当前这篇paper是基于ASTE任务进一步做阐述。
用于ABSA的Seq2Seq
最近的趋势是设计一个统一的框架来同时处理多个ABSA任务,而不是为每个ABSA任务使用单独的模型。近来,Seq2Seq模型已被应用于ABSA任务(Yan et al., 2021; Zhang et al., 2021a,b),将其表述为文本到文本问题:
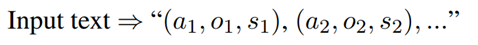
输出是情感元组序列。尽管这些方法取得了一定成就,但是依然有两个缺陷:1)顺序,元组之间应当是无序的。2)依赖,对于第二个元组的生成不应当以第一个元组为条件。
用于ABSA的Seq2Path
我们认为树是表达输出的更好选择,树可以表达“1-to-n“的关系,即可以表达生成过程中一个token下面接多个有效tokens的情况。然而,序列仅仅能表达”1-to-1“的关系,生成过程中一个token只能接一个token(贪婪算法)。如figure 1所示例子,两个情感元组(“rolls”, “big”, “positive”) and (“rolls”,“not good”, “negative”)共享同一个方面词“rolls”,因此这是一个“1-to-n“的关系,“big” and “not”接着同一个token。
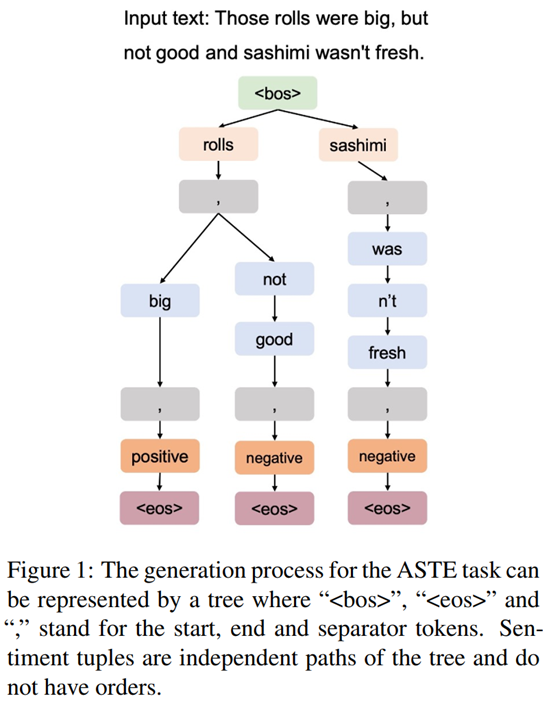
本文提出“Seq2Path”,将ABSA任务定义为”树的序列路径“问题。不同的情感元组可以看作是一个树的路径被单独生成,只要给定输入文本,就可以独立的得到任何有效的情感元组。举例来说,确定(a2; o2; s2)是一个情感元组,不需要知道(a1; o1; s1)也是一个有效的情感元组。
训练过程中,将所有情感元组看待为独立的目标,使用传统的Seq2Seq模型学习目标计算均值损失。为了推理,应用束搜索(bean search)生成多条路径及其概率。高概率的路径往往是正确的,但是也有例外。我们引入一个判别token从束搜索中自动选择正确路径。我们还扩充了数据集,为判别token生成负样本。
本文贡献:
1)提出了基于Seq2Path的并行生成ABSA框架,根据树的路径生成情感元组,引入判别token自动从束搜索中选择有效路径。
2)我们做了更多的研究表明Seq2Path在学习token生成的精确条件转移概率方面更好。
3)实验结果表明,模型在AOPE、UABSA、ASTE、TASD、ACOS任务的四个广泛使用的数据集Laptop14、Rest14、Rest15、Rest16上达到了sota,F1分数上几乎在所有情况下都优于基线模型。
2方法
2.1 Seq2Path概述
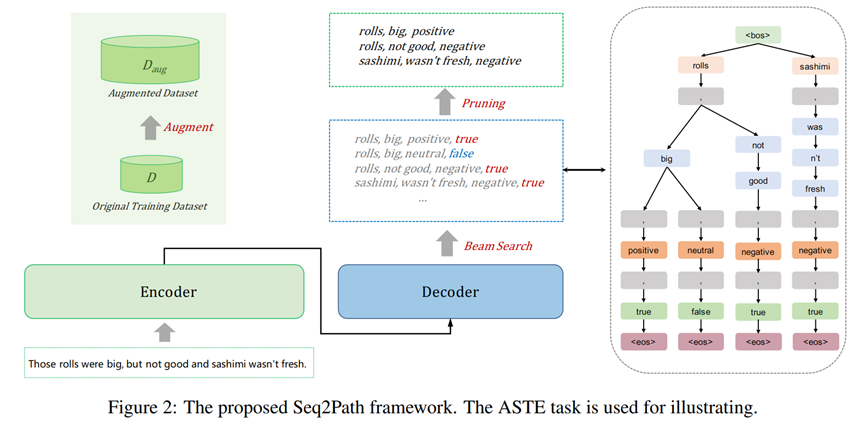
本文提出来的Seq2Path模型如Figure 2。编码器-解码器架构是普通的Seq2Seq架构,其区别如下所述。一 将不同的元组看待为相互独立的目标,通过普通的Seq2Seq模型训练并计算平均损失;二 token的生成过程会形成一棵树,将束搜索用于并行且独立的生成路径。三 输入是文本,输出是在末尾带有二分类判别标记v∈{true,false}的一组有效情感元组。如:
AOPE : Input text => “a, o, v”
ASTE : Input text => “a, o, s, v”
TASD : Input text => “c, a, s, v”
UABSA : Input text => “a, s, v”
ACOS : Input text => “c, a, o, s, v”
此处a, o, c, s分别代表方面、观点、分类、情感。由于对于判别token而言没有负样本,我们不得不为了训练而扩充数据集。
2.2 训练
路径上的平均损失。对于输入x,期望输出一组元组:
Y = {y1,……., yk} (1)
数据集D收集的是(x,Y)对,正如Figure 1 and 2 所示,集合Y可以表示为一棵树,其中每个y对应树的一条路径,k就是路径的总数。通过输入x得到预测值Y^,损失函数为k条路径上的平均损失。
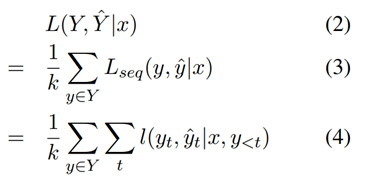
Lseq(.)就是普通的 Seq2Seq 损失,L(.)是每个时间步t的损失。更多的理论证明将在第三部分提供。
2.3 推论
束搜索
我们应用带有约束解码的束搜索方法,束搜索算法根据条件概率在每一步为输入序列选择多个备选方案。通过束搜索,我们输出概率递减的 top-k 路径,这些路径表示路径有效的可能性。
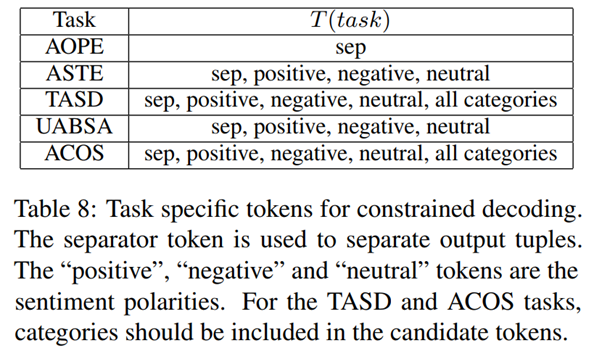
在解码期间也使用约束解码,不去搜索整个词汇表,而是在输入文本和特定任务tokens中选择进行输出。如在情感极性判断上只需要在积极positive、消极negative和中性neutral中进行查找即可。一些情况特殊的限制性token如下所示:
采用了这样的方式也不可避免的会出现路径重叠的情况,如“a, o, s, true”和 “a, o, s, false”等,这里作者就会去选取概率更高的路径,然后输出判别标记为true的,过滤其他无效路径。
2.4数据增强
由于原始的数据集中并没有针对于作者自己所加的判别token(true,false)的负样本,也就是判别为false的,因此作者这里进行了样本增强,具体本文用以下两种方式生成负样本,D1数据集是为了提高模型匹配元组元素的能力,随机替换元组中的元素,生成“rolls, was not fresh, positive, false”, “sashimi, big,negative, false”等。D2数据集是为提高模型过滤大部分不良泛化情况的能力,首先用几个小epoch训练模型,然后使用束搜索生成负样本。增广数据集就是正负样本的并集。最后的数据集就是生成的这样负样本与原始样本的拼接。
作者这里为了避免模型学习负样本的路径,对负样本路径的损失进行了mask处理(一个trick),对于正样本就不动。如果 y 是负样本,即 y 的验证标记为“false”,则损失掩码为如式7所示,如果 y 是正样本,即 y 的验证标记为“true”,则损失掩码如式8所示。损失掩码意味着在损失计算中跳过了一些token,如下图所示。除了判别token和结束标志token之外的所有token都被屏蔽。 Lm(·)为带有掩码的损失,其中只有m(t) = 1的标记参与损失计算,可以得到如式9所示的损失函数,最终数据集的总体损失如式10所示。具体方式如下:
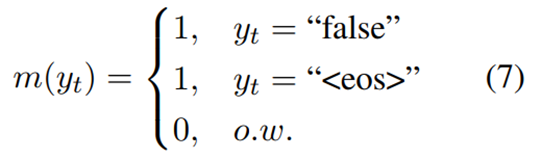
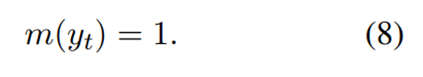
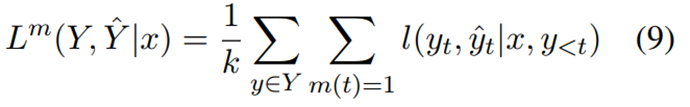
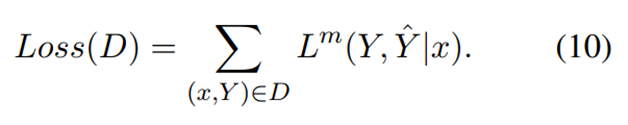
也就是说只对最后的判别token和结束标志有损失传播,其余均为0,样例如下所示:

2.5算法
Seq2Path 的流程总结为算法1,首先生成负样本数据进行数据增强。其次用普通的Seq2Seq方法训练模型,使用损失掩码。在推理时使用束搜索,生成前k条路径并剪枝。

该篇文章在四个广泛使用的基准数据集上进行,分别为SemEval2014 Restaurant, Laptop,SemEval2015 Restaurant和SemEval2016 Restaurant,根据ABSA的不同子任务,采取了基线方法进行比较。整体的实验结果较好,总体而言,本文提出的方法几乎在所有子任务上的F1 分数都达到了SOTA。
最后作者也进行了一些实验分析。首先分析束尺寸对性能的影响,总体而言,较小的束尺寸会导致更差的召回率,较大的束尺寸会导致更差的精度。然而,通过剪枝过程,无论 k 的选择如何,在前面几张实验表中得到的性能相比其他方法都是最优的,而最佳k的选择则取决于任务和数据集。尽管束搜索需要更大的 GPU 内存,但 Seq2Path 可以使用更短的最大输出序列长度,从而减少内存消耗。其次是数据增强的消融研究,数据集 D1 对 F1 分数的影响较小,数据集 D2 对 F1 分数有重大影响,说明利用少量epoch训练得到的模型得到负样本可以有效提高模型性能。