A Unified Generative Framework for Aspect-Based Sentiment Analysis
Paper:https://arxiv.org/pdf/2106.04300.pdf
Code:https://github.com/yhcc/BARTABSA
Author Information:Hang Yan1,∗, Junqi Dai1,∗, Tuo Ji1, Xipeng Qiu1,2†, Zheng Zhang3
概念:
token:模型输入基本单元。比如中文BERT中,token可以是一个字,也可以是<CLS>等标识符。
embedding:一个用来表示token的稠密的向量。token本身不可计算,需要将其映射到一个连续向量空间,才可以进行后续运算,这个映射的结果就是该token对应的embedding。
encoding:表示编码的过程。将一个句子,浓缩成为一个稠密向量(也称为表征, representation),这个向量可以用于后续计算,用来表示该句子在连续向量空间中的一个点。理想的encoding能使语义相似的句子被映射到相近的空间。
Abstract
Aspect-based Sentiment Analysis (ABSA) aims to identify the aspect terms, their corresponding sentiment polarities, and the opinion terms. There exist seven subtasks in ABSA. Most studies only focus on the subsets of these subtasks, which leads to various complicated ABSA models while hard to solve these subtasks in a unified framework. In this paper, we redefine every subtask target as a sequence mixed by pointer indexes and sentiment class indexes, which converts all ABSA subtasks into a unified generative formulation.
Introduction
Aspect-based Sentiment Analysis (ABSA) is the fine-grained Sentiment Analysis (SA) task, which aims to identify the aspect term (a), its corresponding sentiment polarity (s), and the opinion term (o). For example, in the sentence “The drinks are always well made and wine selection is fairly priced”, the aspect terms are “drinks” and “wine selection”, and their sentiment polarities are both “positive”, and the opinion terms are “well made” and “fairly priced”. Based on the combination of the a, s, o, there exist seven subtasks in ABSA. We summarize these subtasks in Figure 1.
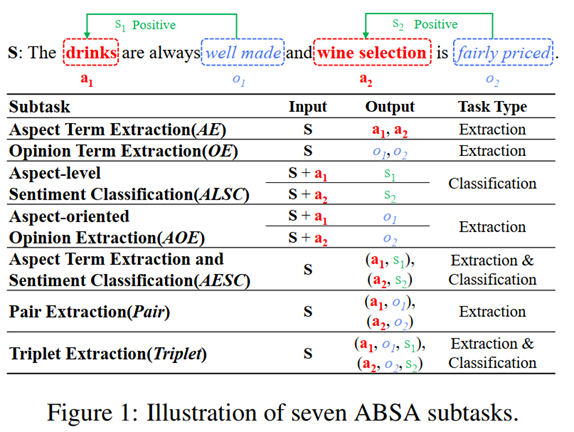
Task Type: There are two kinds of tasks: extraction task (extracting aspect and opinion) and classification task (predicting sentiment).
抽取类,具体有(AE、OE、AOE、AESC、Pair、Triplet)
分类类,具体有(ALSC、AESC、Triplet)
Contributions
- We formulate both the extraction task and classification task of ABSA into a unified index generation problem. Unlike previous unified models, our method needs not to design specific decoders for different output types.
- With our re-formulation, all ABSA subtasks can be solved in sequence-to-sequence framework, which is easy-to-implement and can be built on the pre-trained models, such as BART.
- We conduct extensive experiments on four public datasets, and each dataset contains a subset of all ABSA subtasks. To the best of our knowledge, it is the first work to evaluate a model on all ABSA tasks.
- The experimental results show that our proposed framework significantly outperforms recent SOTA methods.
Methodology
We use a, s, o, to represent the aspect term, sentiment polarity, and opinion term, respectively. Moreover, we use the superscript s and e to denote the start index and end index of a term. For example, os, ae represent the start index of an opinion term o and the end index of an aspect term a. We use the sp to denote the index of sentiment polarity class. The target sequence for each subtask is as follows:
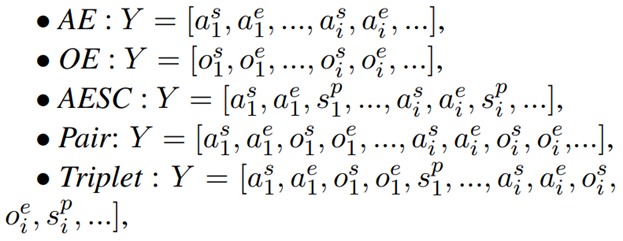
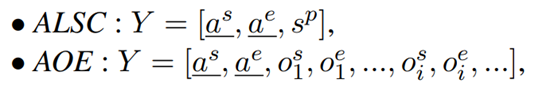
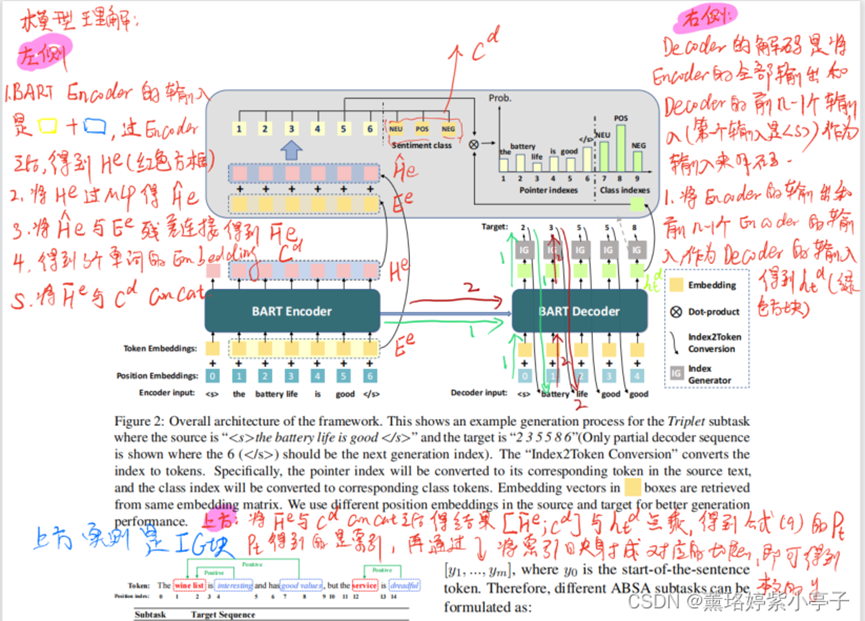
where the underlined tokens are given during inference. Detailed target sequence examples for each subtask are presented in Figure 3.

As our discussion in the last section, all subtasks can be formulated as taking the X = [x1; :::; xn] as input and outputting a target sequence Y =[y1; :::; ym], where y0 is the start-of-the-sentence token.
we use a model composed of two components: (1) Encoder; (2) Decoder.
Encoder The encoder part is to encode X into vectors He. We use the BART model, therefore,
the start of sentence (<s>) and the end of sentence (</s>) tokens will be added to the start and end of X, respectively. We ignore the <s> token in our equations for simplicity. The encoder part is as follows:
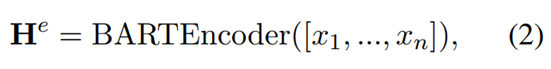
Decoder The decoder part takes the encoder outputs He and previous decoder outputs Y<t as inputs to get Pt. However, the Y<t is an index sequence. Therefore, for each yt in Y<t, we first need to use the following Index2Token module to conduct a conversion.
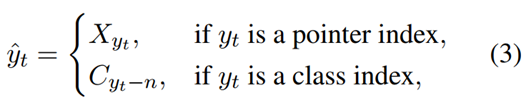
where C = [c1,,,,,,,cl] is the class token list.
After that, we use the BART decoder to get the last hidden state:

With hdt , we predict the token probability distribution Pt as follows:

Pictures from: https://blog.csdn.net/weixin_41862755/article/details/120266414
这是一个三元组(aspect, opinion,sentiment)抽取的模型示例。
其中输入文本为: <s> the battery life is good </s>
对应的坐标为:2 3 5 5 8 6 这些为位置序号。(Only partial decoder sequence is shown where the 6 (</s>) should be the next generation index).
原始的X 隐状态的维度为n * d,concat三个情感词的Embedding之后,得到的维度为(n+3)* d,与hdt维度为d*1点乘之后,维度为(n+3) * 1。将点乘之后的结果,过一个Softmax,得到(n+3)长度,每个token对应的概率值,将最高的概率值对应位置表示的token索引输出。