目录
内容
如果想在一个n个元素的列表中,查询元素x是否存在于列表中,首先想到的就是从头到尾遍历一遍列表,逐个进行比较,这种方法效率是Θ(n);当然,如果列表是已经排好序的话,可以采用二分查找算法进行查找,这时效率提升到Θ(logn); 本文中,我们介绍散列表(HashTable),能使查找效率提升到Θ(1);
Question 1:那么什么是Hash Table,是如何定义的呢?
给定一个关键字Key(整数),通过一个定义好的散列函数,可以计算出数据存放的索引位置,这样我们不用遍历,就可以通过计算出的索引位置获取到要查询的数。如下图所示:

因此:散列表是普通数组概念的推广,在散列表中,不是直接把关键字用作数组下标,而是根据关键字通过散列函数计算出来的。下面会进行讲解。
question 2:那么,Hash Function 如何定义呢?
hash function 有很多种定义方法,其中 最常用的是除法散列;在散列函数小节中会进行详细介绍【除法散列、乘法散列、全域散列、完全散列】
question 3:当给定的keys不是整数怎么办?
如下图所示,想通过各hash function将Non-InTeger key转换为Integer key,然后再进行正常的运算。
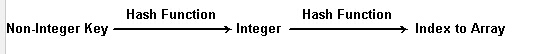
Question 4:当多个关键字Key,通过hash function计算出的索引相同,就是说他们产生了“冲突”,这时该怎么办呢?
针对这个问题,我们的处理方法有:开放寻址法和链表法。具体会在碰撞处理方法小节讲解。
Ok,下面开始枯燥地讲解了:
当关键字的的全域(范围)U比较小的时,直接寻址是简单有效的技术,一般可以采用数组实现直接寻址表,数组下标对应的就是关键字的值,即具有关键字k的元素被放在直接寻址表的槽k中。直接寻址表的字典操作实现比较简单,直接操作数组即可以,只需O(1)的时间。见下图:
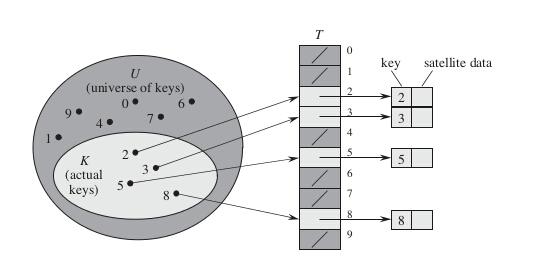
假设某应用要用到一个动态集合,其中每个元素都是取自全域U={0,1,...,m-1}中的一个关键字,这里m不是一个很大的数。另外,假设没有两个元素具有相同的关键字。
为表示动态集合,我们用一个数组,或称为直接寻址表(direct-address table),记为T[0...m-1]。其中每个位置,称为一个槽(slot),对应全域U中的一个关键字。上图描述了该方法。槽k指向集合中一个关键字为k的元素。如果该集合中没有关键字为k的元素,则T[k]为NIL
直接寻址技术的缺点是非常明显的:如果全域U很大,则在一台标准的计算机可用内存容量中,要存储大小为|U|的一张表T也许不大实际,甚至不可能。还有,实际存储的关键字集合K相对于U来说可能很小,使得分配给T的大部分空间都将浪费掉。当存储在字典中的关键字集合K比所有可能的关键字的全域U要小许多时,散列表需要的存储空间要比直接寻址表少的多。在散列方式下,元素存放在槽h(k)中即利用散列函数h,由关键字k计算出槽的位置。这里,函数h将关键字的全域U映射到散列表T[0...m-1]的槽位上。
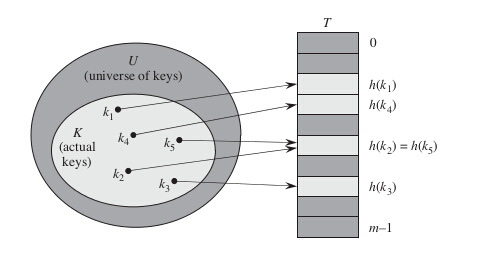
这里存在一个问题:两个关键字可能映射到同一个槽中。我们称这种情形为冲突(collision),解决冲突可以通过选择一个合适的散列函数h来做到这一点。但是,由于|U|>m,故至少有两个关键字其散列值相同,所以想要完全避免冲突是不可能的。因此一方面可以通过精心设计的散列函数来尽量减少冲突的次数,另一方面仍需要解决可能出现冲突的方法。
本文介绍几种冲突解决的方法,主要包括链表法和开放寻址法。其中开放寻址法又有几种可选的方法:线性探查、二次探查、双重散列、随机散列
接下来介绍几种常用的散列函数
好的散列函数的特点是每个关键字都等可能的散列到m个槽位上的任何一个中去,并与其他的关键字已被散列到哪一个槽位无关。多数散列函数都是假定关键字域为自然数N={0,1,2,....},如果给的关键字不是自然数,则必须有一种方法将它们解释为自然数。例如对关键字为字符串时,可以通过将字符串中每个字符的ASCII码相加,转换为自然数。在实际工作中经常用字符串作为关键字,例如身姓名、职位等等。这个时候需要设计一个好的散列函数进程处理关键字为字符串的元素。下面代码为将字符串中每个字符的ASCII码相加,转换为自然数的方法。
1 int Hash(const string& key,int tablesize) 2 { 3 int hashVal = 0; 4 for(int i=0;i<key.length();i++) 5 hashVal += key[i]; 6 return hashVal % tableSize; 7 }
有许多优秀的字符串散列函数,下面链接可以参考https://www.byvoid.com/blog/string-hash-compare
通过取k除以m的余数,将关键字k映射到m个槽的某一个中去。散列函数为:h(k)=k mod m 。m不应是2的幂,通常m的值是与2的整数幂不太接近的质数。
例如:下面的数如何通过除法散列映射到具有11个槽的散列表中:
23
346
48
通过除法散列:
23 % 11 = 1(余数是1)
346 % 11 = 5(余数是5)
48 % 11 = 4(余数是4)
则应该插入到1,5,4槽中,想下面所示:

乘法散列法构造散列函数需要两个步骤。第一步,用关键字k乘上常数A(0<A<1),并抽取kA的小数部分。然后,用m乘以这个值,再取结果的底。散列函数如下:h(k) = m(kA mod 1)。
任何一个特定的散列函数都可能将特定的n个关键字全部散列到同一个槽中,使得平均的检索时间为Θ(n)。为了避免这种情况,唯一有效的改进方法是随机地选择散列函数,使之独立与要存储的关键字。这种方法称为全域散列(universal hashing)
全域散列在执行开始时,就从一组精心设计的函数中,随机地选择一个作为散列函数。因为随机地选择散列函数,算法在每一次执行时都会有所不同,甚至相同的输入都会如此。这样就可以确保对于任何输入,算法都具有较好的平均情况性能.
选择一个足够大的质数p,使得每一个可能的关键字都落在0到p-1的范围内。设Zp表示集合{0, 1, …, p-1},Zp*表示集合{1, 2, …, p-1}。对于任何a∈Zp*和任何b∈Zp,定义散列函数ha,b
ha,b = ((ak+b) mod p) mod m;其中a,b是满足自己集合的随机数;
如果某种散列技术可以在查找时,最坏情况内存访问次数为O(1)的话,则称其为完全散列(perfect hashing)。当关键字集合是静态的时,这种最坏情况的性能是可以达到的。所谓静态就是指一旦各关键字存入表中后,关键字集合就不再变化了。
我们可以用一种两级的散列方案来实现完全散列,其中每级上采用的都是全域散列。如下图: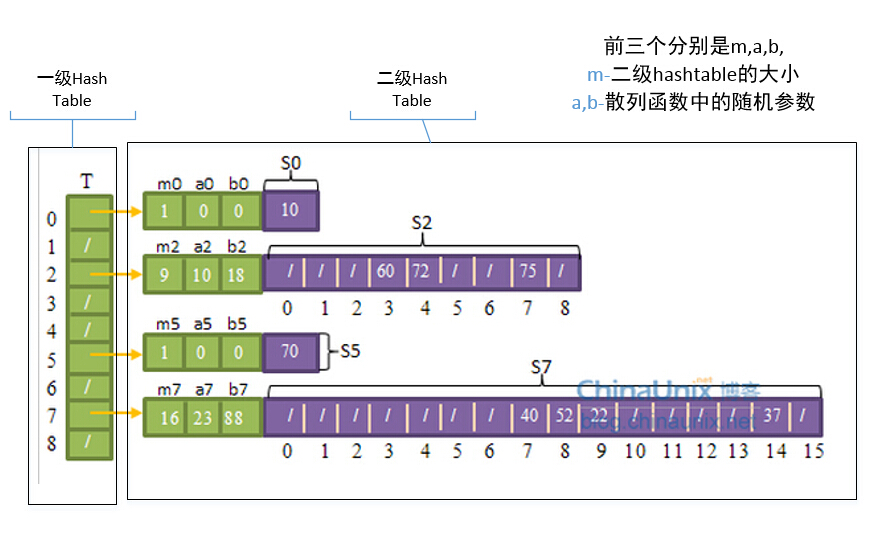
首先第一级使用全域散列把元素散列到各个槽中,这与其它的散列表没什么不一样。但在处理碰撞时,并不像链接法(碰撞处理方法)一样使用链表,而是对在同一个槽中的元素再进行一次散列操作。也就是说,每一个(有元素的)槽里都维护着一张散列表,该表的大小为槽中元素数的平方,例如,有3个元素在同一个槽的话,该槽的二级散列表大小为9。不仅如此,每个槽都使用不同的散列函数,在全域散列函数簇h(k) = ((a*k+b) mod p) mod m中选择不同的a值和b值,但所有槽共用一个p值如101。每个槽中的(二级)散列函数可以保证不发生碰撞情况。
可 以证明,当二级散列表的大小为槽内元素数的平方时,从全域散列函数簇中随机选择一个散列函数,会产生碰撞的概率小于1/2。所以每个槽随机选择散列函数后,如果产生了碰撞,可以再次尝试选择其它散列函数,但这种尝试的次数是非常少的。
虽然二级散列表的大小要求是槽内元素数的平方,看起来很大,但可以证明,当散列表的槽的数量和元素数量相同时(m=n),所有的二级散列表的大小的总量的期望值会小于2*n,即Ө(n)。
下面介绍几种冲突解决的方法,主要包括链表法和开放寻址法。其中开放寻址法又有几种可选的方法:线性探查、二次探查、双重散列、随机散列
在链接法中,把散列到同一槽中的所有元素(冲突的元素)都放在一个链表中;
若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。
举例说明链接法的执行过程,设有一组关键字为(26,36,41,38,44,15,68,12,6,51),用除余法构造散列函数,初始情况如下图所示: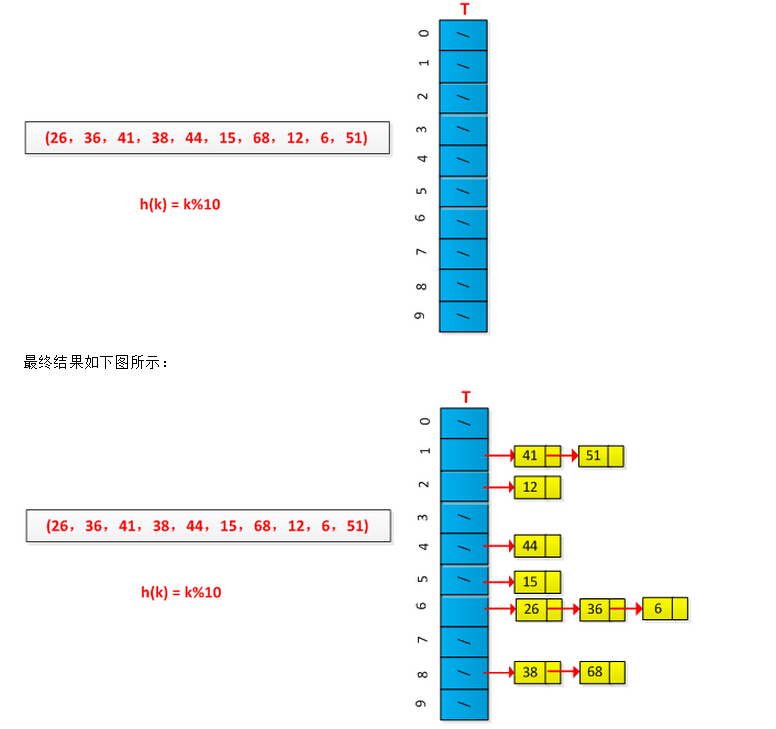
开放寻址法是另外一个处理元素冲突的方法;链表法是把冲突的元素依次放到一串链表中,而开放寻址法的思路是:在产生冲突的情况下,在hashtable中寻找其他空闲的槽位插入;当然,如何寻找其他空闲的槽位,我们有几种方法,包括:线性探查、二次探查、双重散列、随机散列;下面逐个讲解。
给定一个普通的散列函数h':U-->{0,1,...,m-1},称为辅助散列函数,线性探查方法采用的散列函数为
h(k,i)=(h'(k)+i) mod m, i = 0,1,...,m-1
给定一个关键字k,首先探查槽T[h'(k)],即由辅助三列函数所给出的槽位。再探测T[h'(k)+1],依次类推,直到槽T[m-1]。然后,又绕到槽T[0],T[1],...,直到最后探测到槽T[h'(k)-1]。
线性探测方法比较容易实现,但它存在着一个问题,称为一次群集。随着连续被占用的槽不断增加,平均查找时间也随之不断增加。集群现象很容易出现,这是因为当一个空槽前有i个满的槽时,该空槽下一个将被占用的概率是(i+1)/m。连续被占用的槽就会变得越来越长,因而平均查询时间也会越来越大。采用例子进行说明线性探测过程,已知一组关键字为(26,36,41,38,44,15,68,12,6,51),用除法散列构造散列函数,初始情况如下图所示: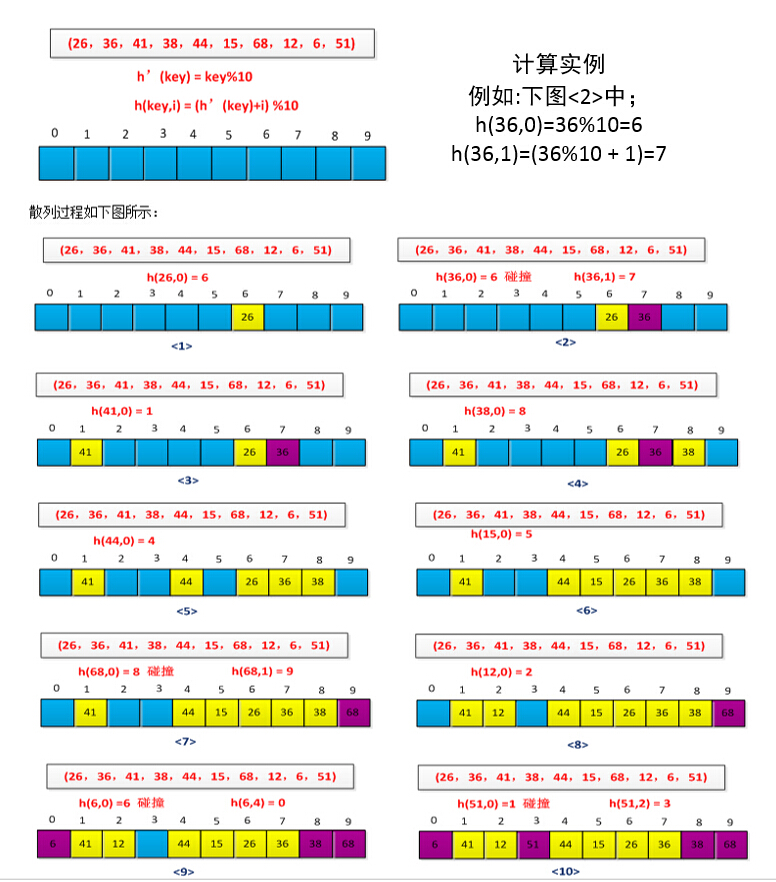
h(k,i)=(h'(k)+c₁i+c₂i²) mod m , i = 0,1,...,m-1
其中h'是一个辅助散列函数,c₁和c₂为正的辅助常数,i=0,1,...m-1。初始的探查位置为T[h'(k)],后续的探查位置要加上一个偏移量,该偏移量以二次的方式依赖于探查序号i。这种探查方法的效果要比线性探查好很多,但是,为了能够充分利用散列表,c₁,c₂和m的值要受到限制。此外,如果两个关键字的初始探查位置相同,那么它们的探查序列也是相同的。这一性质可导致一种轻度的群集,称为二次群集。
双重散列(double hashing)是用于开放寻址法的最好方法之一,因为它所产生的排列具有随机选择队列的许多特性。双重散列采用如下形式的散列函数:
h(k,i)=(h₁(k)+ih₂(k)) mod m, i = 0,1,...,m-1
其中h₁和h₂均为辅助散列函数。初始探查位置为T[h₁(k)],后续的探查位置是前一个位置加上偏移量h₂(k)模m。因此,不像线性探查或二次探查,这里的探查序列以两种不同方式依赖于关键字k,因为初始探查位置、偏移量或者两则都可能发生变化。下图给出了一个使用双重散列法进行插入的例子。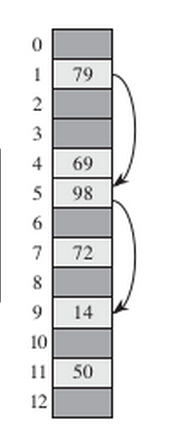
上图说明:双重散列法的插入。此处,散列表的大小为13,h₁(k)=k mod13,h₂(k)=1+(k mod 11)。以元素14为例:因为h₁(14)=(14 mod13)=1,槽1已被79占用,--》h₂(14)=1+(14 mod 11)=4,则h(14,1)=h₁(14)+h₂(14)=1+4=5,槽5已被98占用,--》h(14,2)=h₁(14)+2*h₂(14)=1+2*4=9,槽9空闲,则插入到槽9中;所以在探查了槽1和槽5,并发现它们被占用后,关键字14插入了槽9中
随机散列散列函数:
h(k,i)=(h₁(k)+Random(i)) mod m,Random(i)是随机整数,大小属于集合{0,1,2,......,m-1}
其中h₁为辅助散列函数。初始探查位置为T[h₁(k)],后续的探查位置是前一个位置加上偏移量Random(i)模m;Random(i)是系统产生的随机数,随机散列数组在探查之前生成,数组内的随机数相互独立;类似于全域散列函数,其实属于散列函数范畴的,这里专门当做一种探查方法来说明,只是为了说明一个随机的探查思想;
如果散列表满了,再往散列表中插入新的元素时候就会失败;或者散列表快满时,进行插入是一个效率很低的过程;这个时候可以通过创建另外一个散列表,使得新的散列表的长度是当前散列表的2倍多一些,重新计算各个元素的hash值,插入到新的散列表中。再散列的问题是在什么时候进行最好,有下面情况可以判断是否该进行再散列:
(1)当散列表将快要满了,给定一个范围,例如散列被中已经被用到了80%,这个时候进行再散列。
(2)当插入一个新元素失败时候(相同关键字失败除外),进行再散列。
(3)当插入一个新元素产生冲突次数过多时,进行再散列。
(3)对于链表法,根据装载因子(已存放n个元素的、具有m个槽位的散列表T,装载因子α=n/m)进行判断,当装载因子达到一定的阈值时候,进行再散列。
下面代码采用开放寻址法处理冲突,包括线性探查、二次探查、双重散列探查、随机散列探查实现;散列函数采用简单的除法散列函数;当插入一个新元素产生冲突次数过多时,进行再散列
HashTable.h


1 //HashTable.h 开放寻址法哈希表类(HashTable类) 2 #ifndef _HAXI_H_ 3 #define _HAXI_H_ 4 const int SUCCESS = 1;//成功 5 const int UNSUCCESS = 0;//不成功 6 const int DUPLICATE = -1;//关节字冲突(重复),不能再插入 7 const int N = 4;//hashsize[]的容量 8 int hashsize[N] = { 11, 19, 37, 73 }; 9 //哈希表容量递增表,一个合适的素数序列,(重)建哈希表用到 10 11 12 template<typename D>class HashTable 13 {//带数据元素类型D模板的开放寻址法哈希表类 14 private://6个私有成员函数,5个私有数据成员 15 D *elem;//数据元素存储基址,动态分配数组 16 int count, length;//数据元素个数,哈希表容量 17 int sizeindex;//hashsize[sizeindex]为当前容量 18 int *rando;//随机数数组指针 19 int Hash(KeyType Key) 20 {//一个简单的哈希函数 21 return Key%length; 22 } 23 int Hash2(KeyType Key)//用于双重散列探索法 24 {//双重散列探查法的第二个哈希函数 25 return Key % (length - 2); 26 } 27 void Random() 28 {//建立伪随机数组(用于随机探查法) 29 bool *ra = new bool[length];// 30 rando = new int[length]; 31 int i; 32 for (i = 1; i<length; i++)//设置ra[i]的初值 33 ra[i] = false;//i不在随机数数组中的标志 34 // srand(time(0));//设置随机数种子 35 for (i = 1; i<length; i++)//依次给rando[i]赋随机值 36 { 37 do 38 { 39 rando[i] = rand() % (length - 1) + 1;//给rando[i]赋值(1-length-1) 40 if (!ra[rando[i]])//伪随机数组中没有此数 41 ra[rando[i]] = true;//赋值成功 42 else 43 rando[i] = 0; 44 } while (rando[i] == 0);//赋值失败则重新赋值 45 cout << "rando[" << i << "]=" << rando[i] << endl; 46 } 47 delete[]ra; 48 } 49 int d(int i, KeyType Key)//增量序列函数 50 {//返回第i次冲突的增量 51 switch (type) 52 { 53 case 0: return i;//线性探查法 54 case 1: return ((i + 1) / 2)*((i + 1) / 2)*(int)pow(-1, i - 1); 55 //二次探查法(1,-1,4,-4,9,-9,......) 56 case 2: return i*Hash2(Key);//双重散列探查法 57 case 3: return rando[i];//随机探查法(由Random()建立的一个伪随机数列) 58 default:return i;//默认线性探查法 59 } 60 } 61 //开放寻址法求得关键字为Key的第i次冲突的地址p 62 void collision(KeyType Key, int &p, int i) 63 { 64 p = (Hash(Key) + d(i, Key)) % length;//哈希函数加增量后再求余 65 if (p<0)//得到负数(双重探查可能出现) 66 p = p + length;//保证非负 67 } 68 //重建哈希表 69 void RecreateHashTable() 70 { 71 int i, len = length;//原容量 72 D *p = elem;//p指向哈希表原有数据空间 73 sizeindex++;//增大容量为下一个序列数 74 if (sizeindex<N) 75 { 76 length = hashsize[sizeindex]; 77 elem = new D[length]; 78 assert(elem != NULL); 79 for (i = 0; i<length; i++)//未填数据的标志 80 elem[i].key = EMPTY; 81 for (i = 0; i<len; i++)//将p所指原elem中的数据插入到重建的哈希表中 82 if (p[i].key != EMPTY && p[i].key != TOMB) 83 InsertHash(p[i]); 84 delete[]p; 85 if (type == 3)//随机探查法 86 Random(); 87 } 88 } 89 public://7个公有成员函数,1个共有数据成员 90 int type;//探查法类型(0-3) 91 HashTable() 92 {//构造函数,构造一个空的哈希表 93 count = 0; 94 sizeindex = 0; 95 length = hashsize[sizeindex]; 96 elem = new D[length]; 97 assert(elem != NULL); 98 for (int i = 0; i<length; i++) 99 elem[i].key = EMPTY;//未填数据的格式 100 cout << "请输入探查法的类型(0:线性;1:二次;2:双散列;3:随机):"; 101 cin >> type; 102 if (type == 3) 103 Random(); 104 else 105 rando = NULL; 106 } 107 ~HashTable() 108 {//析构函数,销毁哈希表 109 if (elem != NULL) 110 delete[]elem; 111 if (type == 3) 112 delete[]rando; 113 } 114 //在开放寻址哈希表中查找关键字为Key的元素,若查找成功,以p指向待查数据元素在表中位置 115 //并返回SUCCESS;否则,以p指示插入位置,并返回UNSUCCESS 116 //c用以计冲突次数,其初值置零,供建表插入时参考 117 bool SearchHash(KeyType Key, int &p, int &c) 118 { 119 int c1, tomb = -1;//存找到的第一个墓碑地址(被删除数据) 120 p = Hash(Key);//哈希地址 121 //下面的while代码段,如果哈希地址处数据不是要查找的数据, 122 //则求下一个探查地址p,进行查找,直到碰撞次数超出定义的阈值 123 124 while (elem[p].key == TOMB || elem[p].key != EMPTY && !EQ(Key, elem[p].key)) 125 { 126 if (elem[p].key == TOMB && tomb == -1)//数据已被删除,且是找到的第一个墓碑 127 { 128 tomb = p; 129 c1 = c;//冲突次数存于c1 130 } 131 c++;//冲突次数+1 132 if (c <= hashsize[sizeindex]/2)//在冲突次数阈值内,求下一个探查地址p 133 collision(Key, p, c); 134 else 135 break; 136 } 137 if EQ(Key, elem[p].key)//查找成功 138 return true; 139 else//查找不成功 140 { 141 if (tomb != -1)//查找过程中遇到过墓碑 142 { 143 p = tomb;//将墓碑作为插入位置 144 c = c1;//冲突次数 145 } 146 return false; 147 } 148 } 149 //查找不成功时将数据元素e插入到开放寻址哈希表中,并返回SUCCESS;查找成功时返回 150 //DUPLICATE,不插入数据元素;若冲突次数过大,则不插入,并重建哈希表,返回UNSUCCESS 151 int InsertHash(D e) 152 { 153 154 int p, c = 0; 155 if (SearchHash(e.key, p, c))//查找成功,已有与e相同关键字 元素,不再插入 156 return DUPLICATE; 157 else if (c <= hashsize[sizeindex]/2)//为找到,冲突次数c也未达到上限(c的阈值可调),插入 158 { 159 elem[p] = e; 160 ++count; 161 return SUCCESS; 162 } 163 else//未找到,但冲突次数已达到上限,重建哈希表 164 { 165 cout << "按哈希地址的顺序遍历重建前的哈希表:" << endl; 166 TraverseHash(Visit); 167 cout << "重建哈希表" << endl; 168 RecreateHashTable(); 169 return UNSUCCESS; 170 } 171 } 172 //从哈希表中删除关节字为Key的数据元素,成功返回true,并将该位置的关键字设为TMOB; 173 //不成功返回false 174 bool DeleteHash(KeyType Key, D &e) 175 { 176 177 int p, c=0;//一定要赋初值,不然c会是个随机的数 178 if (SearchHash(Key, p, c))//查找成功 179 { 180 e = elem[p]; 181 elem[p].key = TOMB; 182 --count; 183 return true; 184 } 185 else 186 return false; 187 } 188 //返回元素[i]的值 189 D GetElem(int i)const 190 { 191 return elem[i]; 192 } 193 //按哈希地址的顺序遍历哈希表H 194 void TraverseHash(void(*visit)(int, D*))const 195 { 196 int i; 197 cout << "哈希地址0~" << length - 1 << endl; 198 for (i = 0; i<length; i++) 199 if (elem[i].key != EMPTY && elem[i].key != TOMB) 200 visit(i, &elem[i]); 201 } 202 }; 203 #endif
HashTable.cpp(主测试函数)
1 // 验证HashTable类的成员函数 2 #include <iostream> 3 #include <fstream> 4 #include <string> 5 #include <assert.h> 6 using namespace std; 7 // 对两个数值型关键字的比较约定为如下的宏定义 8 #define EQ(a, b) ((a)==(b)) 9 const int EMPTY=0;//设置0为无数据标志(此时关键字不可为0) 10 const int TOMB=-1;//设置-1为删除数据标志(此时关键字不可为-1) 11 typedef int KeyType; 12 #include "HashTable.h" 13 // 定义模板<D>的实参HD及相应的I/O操作 14 struct HD 15 { 16 KeyType key; 17 int order; 18 }; 19 void Visit(int i, HD* c) 20 { 21 cout << '[' << i << "]: " << '(' << c->key << ", " << c->order << ')' << endl; 22 } 23 void Visit(HD c) 24 { 25 cout << '(' << c.key << ", " << c.order << ')'; 26 } 27 void InputFromFile(ifstream &f, HD &c) 28 { 29 f >> c.key >> c.order; 30 } 31 void InputKey(int &k) 32 { 33 cin >> k; 34 } 35 36 void main() 37 { 38 HashTable<HD> h; 39 int i, j, n, p=0; 40 bool m; 41 HD e; 42 KeyType k; 43 ifstream fin("input.txt");//第一行的数表示数据个数 44 fin>>n;//由文件输入数据个数 45 //建立哈希表 46 for(i=0; i<n; i++) 47 { 48 InputFromFile(fin, e); 49 j=h.InsertHash(e); 50 if(j==DUPLICATE) 51 { 52 cout<<"哈希表中已有关键字为"<<e.key<<"的数据,无法再插入数据"; 53 Visit(e); 54 cout<<endl; 55 } 56 if(j==UNSUCCESS)//插入不成功,重建哈希表 57 j=h.InsertHash(e); 58 } 59 fin.close(); 60 cout<<"按哈希地址的顺序遍历哈希表:"<<endl; 61 h.TraverseHash(Visit); 62 63 //删除数据测试 64 cout<<"请输入待删除数据的关键字:"; 65 InputKey(k); 66 m=h.DeleteHash(k, e); 67 if (m) 68 { 69 cout << "成功删除数据"; 70 Visit(e); 71 cout << endl; 72 } 73 else 74 cout << "不存在关键字,无法删除!" << endl; 75 cout << "按哈希地址的顺序遍历哈希表:" << endl; 76 h.TraverseHash(Visit); 77 //查询数据测试 78 cout<<"请输入待查找数据的关键字:"; 79 InputKey(k); 80 n=0; 81 j=h.SearchHash(k, p, n); 82 if(j==SUCCESS) 83 { 84 Visit(h.GetElem(p)); 85 cout<<endl; 86 } 87 else 88 cout<<"未找到"<<endl; 89 90 //插入数据测试 91 cout<<"插入数据,请输入待插入数据的关键字:"; 92 InputKey(e.key); 93 cout<<"请输入待插入数据的order:"; 94 cin>>e.order; 95 j=h.InsertHash(e); 96 if (j==DUPLICATE) 97 { 98 cout << "哈希表中已有关键字为" << e.key << "的数据,无法再插入数据"; 99 Visit(e); 100 cout << endl; 101 } 102 if (j == UNSUCCESS)//插入不成功,重建哈希表 103 j = h.InsertHash(e); 104 cout<<"按哈希地址的顺序遍历哈希表:"<<endl; 105 h.TraverseHash(Visit); 106 107 }
input.txt 文件内容
10 17 1 60 2 29 3 38 4 1 5 2 6 3 7 4 8 60 9 13 10
测试结果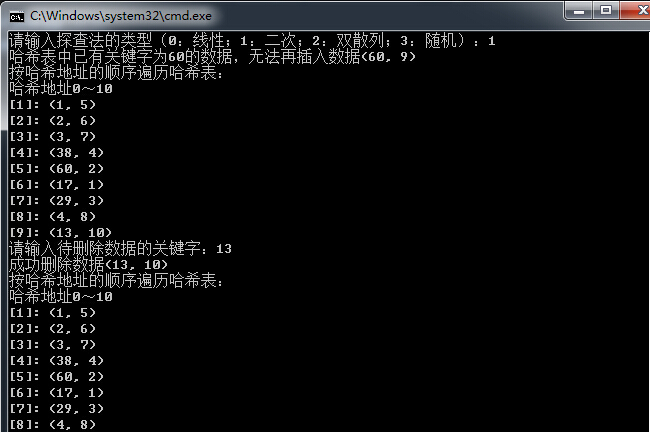

【1】 http://www.junevimer.com/2014/06/10/algorithms-hash-table.html#universal%20hashing
【2】 http://www.cnblogs.com/Anker/archive/2013/01/27/2879150.html
【3】 http://www.cs.uregina.ca/Links/class-info/210/Hash/#EXERCISE
【4】 https://www.byvoid.com/blog/string-hash-compare