(四十八)MySQL数据库使用(二)
4:主键、唯一键、外键 以及 一对一查询,一对多查询
概念
1: 什么叫键 数据库中的键(key)又称为关键字,是关系模型中的一个重要概念,它是逻辑结构,不是数据库的物理部分。 2:唯一键 唯一键,即一个或者一组列,其中没有重复的记录。可以唯一标示一条记录。 3:主键 属于唯一键,是一个比较特殊的唯一键。区别在于主键不可为空。 4:外键 一张表外键的值一般来说是另一张表主键的值。因此,外键的存在使得表与表之间可以联系起来
创建主键、唯一键
第一种方式: create table Robby (id int not null primary key ,name varchar(250) unique key, age int); 第二种方式:这里同时也给大家演示了如何将多个字段合并起来创建一个键 create table Robby (id int, name varchar(250), age int, primary key(id), unique key(name, age));
创建外键
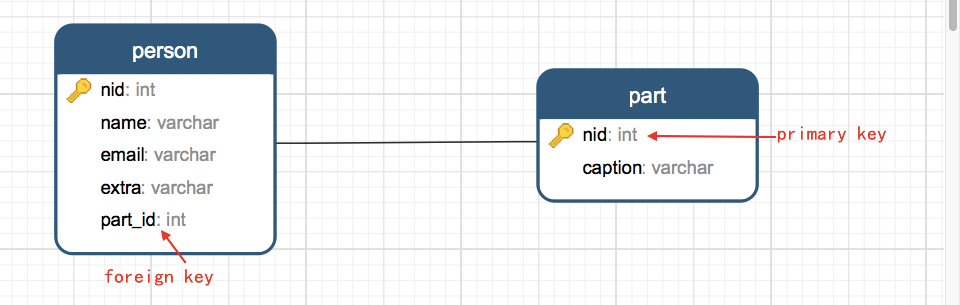
(1)创建主表和从表 create table part (nid int, caption varchar(250), primary key(nid)); create table person (nid int, name varchar(250), email varchar(250), extra varchar(250), part_id int, foreign key(part_id) references part (nid)); (2)删除主表和从表 drop table person; drop table part;
创建多张主表,一张从表的模型
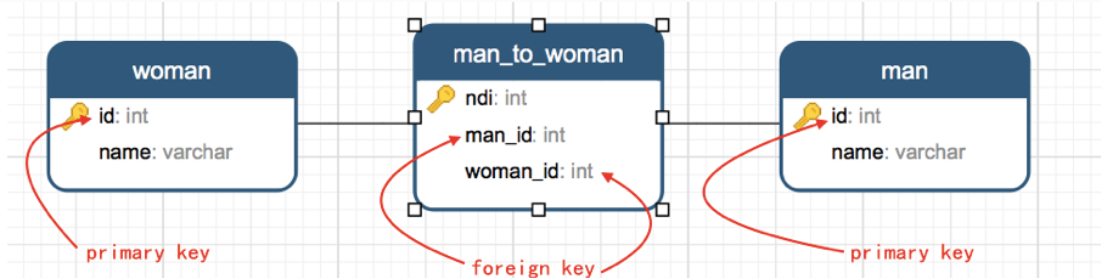
思路:先创建主表,再创建从表 create table woman (id int, name varchar(250), primary key(id)); create table man (id int, name varchar(250), primary key(id)); create table man_to_woman (nid int, man_id int, woman_id int, foreign key(man_id) references man (id), foreign key(woman_id) references woman (id));
给创建好的主从表插入数据
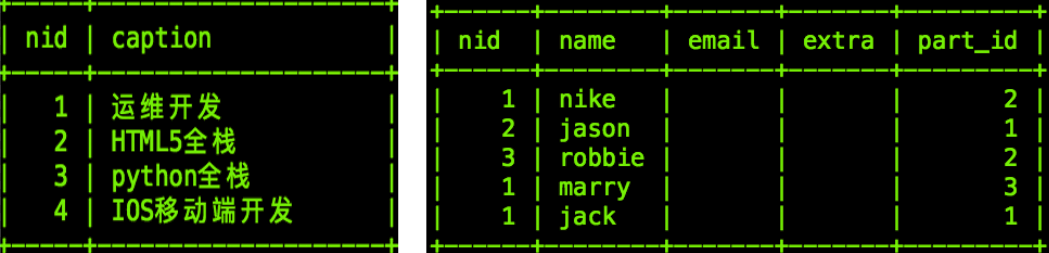
思路:先给主表插入数据,再给从表插入数据, 1:如何给part表、person表插入数据 insert into part values (1, '运维开发'), (2, 'HTML5全栈'), (3, 'python全栈'), (4, 'IOS移动端开发'); insert into person values (1, 'nike', '', '', 2), (2, 'jason', '', '', 1), (3, 'robbie', '', '', 2), (1, 'marry', '', '', 3), (1, 'jack', '', '', 1);
给woman表、man表、man_to_woman表插入数据

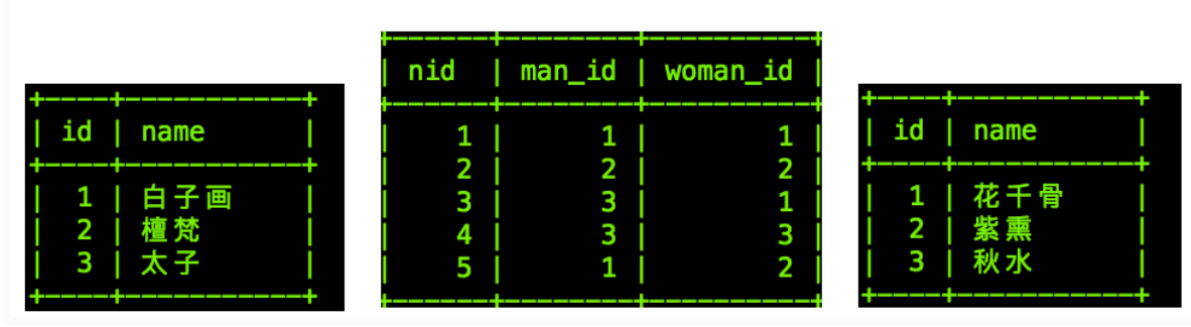
insert into man values (1, '白子画'), (2, '檀梵'), (3, '太子'); insert into woman values (1, '花千骨'), (2, '紫熏'), (3, '秋水'); insert into man_to_woman values (1, 1, 1),(2, 2, 2),(3, 3, 1),(4, 3, 3),(5,1,2);
连表查询
一对一连接查询:找到部门为HTML5全栈的所有人的姓名 select person.name, part.caption from person left join part on person.part_id=part.nid where part.caption='HTML5全栈'; 一对多连接查询:找到与太子有关系的所有的女人 select woman.name from man_to_woman left join man on man.id=man_to_woman.man_id left join woman on woman.id=man_to_woman.woman_id where man.name='太子';
5:索引
概念
1: 索引就像是一张表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。保存索引数据的文件一般会与保存数据的目录分开 2: 索引应该构建在经常被用作查询条件的字段上
使用 DESC TABLE 查看表的索引
DESC TABLE_NAME; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(50) | NO | UNI | NULL | | | age | varchar(500) | YES | MUL | NULL | | | class | varchar(50) | YES | MUL | NULL | | +---------+--------------+------+-----+---------+-------+
PRI 表示主键索引(PRIMARY KEY)。
UNI 表示唯一性索引(UNIQUE KEY),值不能重复。
MUL 表示非唯一性索引(MULTIPLE KEY) ,值可重复。
创建索引
1:普通索引:仅加速查询 create {unique|fulltext|spacial} index 索引名称 {btree|hass} on 表名称 (字段1, 字段2...) (1)create index name_and_age on students (name,age); (2)drop index name_and_age on students; (3)alter table students add index age (age); (4)alter table students drop index age; (5)alter table students add primary key (id); (6)alter table students drop primary key;
索引类型
1:普通索引:加速查询 2:唯一索引:加速查询 + 列值唯一(可以有null) 3:主键索引:加速查询 + 列值唯一 + 表中只有一个(不可以有null) 4:组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并 5:全文索引:对文本的内容进行分词,进行搜索
①:B-TREE 索引:顺序索引,每一个叶子节点到根节点的距离是相同的,左前缀索引,适合查找范围内的数据 适合B-tree索引的查询类型有:全键值,键值范围或键左前缀查找 全值匹配:精确查找某个值 最左前缀匹配:只精确匹配起头部分,'Qcache%' 匹配范围值:id > 1 不适合使用B-tree索引的场景 如果查找不是最左侧开始,索引无效 如果查询中某个列是范围查询,那么其右侧的列都无法再次使用索引优化查询 ②:Hash索引:基于哈希表,特别适用于精确匹配索引中的所有列,但是只有memory存储引擎支持显示hash索引 适应场景:只支持值的比较,例如: id > 1 不适用场景:模糊匹配查询、顺序查询 ③:空间索引(SPATIAL):指依据空间对象的位置和形状或空间对象之间的某种空间关系按一定的顺序排列的一种数据结构 MyISAM支持空间索引 ④:全文索引(FULLTEXT):用于在文本中查找关键词 MyISAM支持全文索引
索引优化策略
1:独立使用列,尽量避免其参与运算 2:左前缀索引:查询字段的时候,条件过滤时,最左前缀精确匹配 3:多列索引:AND 连接字段时适合多列索引;选择合适的索引次序,将选择性最高的放在左侧,范围匹配的放在右侧
索引的调优可以使用explain进行分析
explain select id,name from students where name = 'yhy%'G
# 当前程序语句中每个select语句的编号 id: 1 # 查询类型,简单类型为simple,复杂类型为:subquery(子查询),derived(用户from中的子查询) union(union语句的第一个之后的select语句)union select(匿名临时表) select_type: SIMPLE # 查询关联到的表 table: student1 # 关联类型,或访问类型mysql如何查找表中的行的方式,all(全表扫描) index(根据索引的次序进行全表扫描,如果在extra列出现using index表示覆盖索引)range(服务扫描,有限制的根据索引实现的范围扫描,扫描位置为索引的某一点到另一点结束)ref(根据索引,返回表中所有匹配单个值的行) eq_ref(仅仅返回一行,但需要与某个参考值做比较) const或system(直接返回单个行,效果最佳) type: ref # 查询可能会用到的索引 possible_keys: name_age_unique # 查询使用到的索引 key: name_age_unique # 使用到索引中使用的字节数 key_len: 752 # 在利用key字段所表示的索引进行查询所用的列或某个常量值 ref: const # mysql估计找到目标行所读取的行数 rows: 3 # 额外信息,如 using index(使用覆盖索引) using where (mysql服务器将在存储引擎内存层再进行过滤)using temporary(mysql对结果排序会使用临时表) using filesort(在磁盘创建临时表或内存中排序) Extra: Using where
查看表的状态
1:show table status 2:show table status like 'students'G
6:存储引擎
Innodb 存储引擎
1: 所有的InnoDB表的数据和索引存储于同一个表文件中,但是表数据和表结构分离,例如 -rw-rw---- 1 mysql mysql 65 8月 27 14:31 db.opt -rw-rw---- 1 mysql mysql 8614 8月 27 14:31 students.frm -rw-rw---- 1 mysql mysql 98304 8月 27 14:31 students.ibd db.opt文件 该文件主要用来存储当前数据库的默认字符集和字符校验规则。 students.frm文件是存放表结构的 students.ibd文件存储了当前表的数据和相关的索引数据 因此,表数据和表结构分离, 每个表单独使用一个表文件来存储数据和索引 2:Mariadb默认的存储引擎是XtraDB,但是为了与MySQL兼容,因此也取名做InnoDB,因为MySQL的默认存储引擎是InnoDB。 3:使用聚集索引(数据和索引在一起),也支持自适应hash索引,锁粒度为行级别,支持支持热备工具 (Xtrabackup) 4:支持事务的存储引擎,适合处理大量的短期事务
MyISAM 存储引擎
1:所有的MyISAM表的数据和索引存放在不同的文件中,表结构也分离,例如: -rw-rw---- 1 mysql mysql 10630 8月 27 13:12 user.frm -rw-rw---- 1 mysql mysql 504 8月 27 13:15 user.MYD -rw-rw---- 1 mysql mysql 2048 8月 27 14:30 user.MYI user.frm:为表结构 user.MYD:为表数据 user.MYI:为表索引 2:支持全文索引(fulltext index),压缩,空间函数, 3:不支持事物,表级锁,适用于只读,读多写少
7:MySQL的并发访问控制
概念
任何的数据集只要支持并发访问模型就必须基于锁机制进行访问控制
锁种类
读锁:共享锁,允许给其他人读,不允许他人写
写锁:独占锁, 不允许其他人读和写
锁类型
显示锁:用户手动请求读锁或写锁
隐式锁:由存储引擎自行根据需要加的,无需我们管理
给表施加锁机制
(一)lock tables 方式 1:lock tables 表名称 {read|write} 施加锁 例如:(1)lock tables home read; (2)lock tables home write; 2:unlock tables; 给表解锁 (二)flush tables 方式 1:flush tables 表名称 with {read|write} lock; 2:unlock tables;
8:MySQL事务机制
概念
一组原子性的SQL查询,或多个SQL语句组成了一个独立的单元。要么这一组SQL语句全部执行,要么全部不执行
事物日志:管理事物机制的日志
redo日志:记录SQL执行的语句,这些SQL语句还没有同步到磁盘上,没有修改数据。如果数据奔溃,可以通过撤销SQL执行的语句来进行还原。但是,如果已经同步到磁盘上的SQL语句而言,就只能使用undo来回滚之前的数据了
undo日志:记录没有执行SQL的样子,也就是记录修改数据之前的数据记录下来
ACID机制
A:automicity, 原子性,整个事物中的所有操作要么全部成功提交,要么全部失败回滚
C:consistency , 一致性,数据库总是从一个一致性状态转化为另一个一致性状态
I:isolation, 隔离性,事物不会相互影响,一个事物所作出的操作在提交之前,是不能为其他事物所见,隔离有多种级别,主要是为了并发
D:durability , 持久性,事物一旦提交,其所作的修改会保存在数据库中,不能丢失
事物操作示例1
1:show global variables where Variable_name like '%commit%'; 查看全局变量 2:set session autocommit = OFF; 修改事务日志自动提交功能 3:show variables where Variable_name like ‘%commit%’; 查看当前会话的全局变量 4:start transaction; 启用事务日志机制 5:在表中插入数据,但是不提交(commit) 6:rollback; 事务回滚
事物操作示例2
1:insert into home values (4, 'yhy1', 99); 添加一条记录 2:savepoint first; 设置一个保存点 3:update home set name = 'yhy2' where id = 4; 跟新一条记录 4:savepoint second; 设置第二个保持点 5:insert into home values (5, 'yhy3', 199); 再添加一条记录 6:rollback to second; 回滚到第二个保存点 7:rollback to first; 回顾到第一个保持点 8:commit; 提交数据
9:MySQL 忘记root密码
方案
记住如果忘记root密码,在启动MySQL的时候,跳过查询授权表
对于RedHat 6 而言
(1)启动mysqld 进程时,为其使用:--skip-grant-tables --skip-networking(这两项在/etc/init.d/mysqld文件中的start那一项的mysqld_safe后面加上就是) (2)使用update命令修改管理员密码 update mysql.user set password = password('123456') where user = 'root'; flush privileges; (3)停止mysqd进程,移除上述两个选项,重启mysqld
对于RedHat 7 而言
(1)编辑/usr/lib/systemd/system/mariadb.service文件,在mysqld_safe 后面加上--skip-grant-tables --skip-networking (2)使用update命令修改管理员密码,且让进程重读权限表 (3)停止mysqd进程,移除上述两个选项,重启mysqld
对于Linux系统而言
直接在/etc/my.cnf文件中,找到[mysqld],在后面加上下面两个指令 skip-grant-tables=on skip-networking=on
10:MySQL 查询缓存机制
概念
1:缓存的是查询语句的整个查询结果,是一个完整的select语句的缓存结果 2:哪些查询可能不会被缓存 :查询中包含UDF、存储函数、用户自定义变量、临时表、mysql库中系统表、或者包含列级别的权限表、有着不确定值的函数,如:now( )
缓存相关的服务器全局变量
1:query_cache_min_res_unit:查询缓存分配内存块的最小的分配单位,较小的值较少内存浪费,但是会导致更加平凡的内存分配操作 ,较大的值会导致浪费 2:query_cache_limit:能够缓存的最大查询结果,对有较大结果的查询语句,建议在select中使用SQL_NO_CACHE 3:query_cache_size:查询缓存总共可用的内存空间,单位是字节,必须是1024整数倍 4:query_cache_type:ON , OFF , DEMAND 5:query_cache_wlock_invalidate:如果某个数据表被其他的连接锁定,是否仍然可以从查询缓存中返回结果,默认值为off,表示可以返回数据,on为不允许
缓存命中率
缓存命中率计算公式: Qcache_hits / (Qcache_hits+Com_select)

图片来自:https://www.cnblogs.com/carl10086/p/5988159.html
11:MySQL 日志功能
MySQL日志分类
1:查询日志 :query log 2:慢查询日志:slow_query_log 查询执行时长超过指定时长的查询操作所记录日志 3:错误日志:error log 4:二进制日志:binary log 5:中继日志:relay log (主从复制会讲解) 6:事务日志:transaction log
查询日志 (query log一般不启用)
general_log = {ON|OFF}: 是否启用查询日志
general_log_file = /logs/mysql/general_log:当log_output为FILE类型时,日志信息的记录位置;
log_output = {TABLE|FILE|NONE}
log_output = TABLE,FILE
慢查询日志 (slow_query_log 必须启用)
慢查询日志产生的来源: SQL语句返回的结果集大,或者SQL语句没有被优化器优化,或SQL语句没有使用索引 慢查询日志的作用: 慢查询日志用于对执行速率较慢的SQL语句就像过滤,有利于SQL代码的优化 1:执行时长超出指定时长的操作 show global variables like 'long_query_time'; 查看指定的时长 set global long_query_time = 自定义时长 2:slow_query_log = {ON|OFF}:是否启用慢查询日志 set global slow_query_log = ON 3:slow_query_log_file = mariadb1-slow.log # 过滤条件 4:log_slow_filter=admin,filesort,filesort_on_disk,full_join,full_scan,query_cache,query_cache_miss,tmp_table,tmp_table_on_disk 5:log_slow_rate_limit = 1 指定记录速率 6:log_slow_verbosity = 指定内容级别
中继日志(relay log)
在主从复制架构中,从服务器用于保存从主服务器的二进制日志中读取到的时间
事物日志(transaction log)
事物日志由事物型存储引擎自行管理和使用,无需手动管理
redo log:将一组SQL语句安装先后顺序再执行一次
undo log:回滚到之前数据集没有发生改变的状态
错误日志 (error log 必须启用)
1:错误日志信息产生的来源 mysqld启动和关闭过程中输出的信息; mysqld运行中产生的错误信息; event scheduler运行一个event时产生的日志信息 在主从复制架构中的从服务器上启动从服务器线程时产生的日志信息; 2:错误日志的作用 二进制日志可以反应MySQL数据库的错误信息,用于调试 3:如何开启错误日志 log_error = /path/to/somefile log_warnings = {ON|OFF}:是否记录警告信息于错误日志中;
二进制日志(binary log)
1:二级制日志信息产生的来源 记录导致数据改变,或者潜在改变数据的SQL语句 2:二级制日志的作用 用于通过'重新执行'日志文件中的记录的事件(SQL语句)来生成数据副本,也就是用于主从复制 3:服务器变量 (1)sql_log_bin = [on|off] 是否记录二进制日志, 通常为on (2)log_bin= on :记录位置,通常为on,如果为off,那么需要在my.cnf配置文件中添加一项:log_bin=mysql-bin,用来指明二进制日志保存的路径名,对于yum安装的MySQL,保存于/var/lib/mysql/mysql-bin.000001这样的二进制日志中 (3)binlog_format = MIXED :二进制记录的格式 (4)max_binlog_size = 1073741824 :单个二进制文件的最大值,默认为1G 到达最大值会自动滚动 文件达到上限的大小未必是精确值 (5)max_binlog_cache_size = 18446744073709547520 (6)sync_binlog = 0:设定多久同步一次二进制日志文件;0表示不同步;任何正值都表示记录多少个语句后同步一次; 4:查看二进制文件的信息 show master status: 显示当前正在使用的二进制文件名 show {binary | master} logs:查看当前二进制文件记录end_log_pos(结束位置)的值,其实当前正在记录的二进制文件的大小。 5:日志记录的格式分类 基于“SQL语句”记录: statement 基于“行”记录:row “混合模式” :mixed,系统自行判断 6:二进制日志文件的构成 日志文件:mysql-bin.文件序号 例如: mysql-bin.000001 索引文件:mysql-bin.index 例如:mysql-bin.index 7:使用 mysqlbinlog 客户端命令工具查看二进制文件 mysqlbinlog /var/lib/mysql/mysql-bin.000001
二进制格式解析
# at 19364 #140829 15:50:07 server id 1 end_log_pos 19486 Query thread_id=13 exec_time=0 error_code=0 SET TIMESTAMP=1409298607/*!*/; GRANT SELECT ON tdb.* TO tuser@localhost /*!*/; # at 19486 事件发生的日期和时间;(140829 15:50:07) 事件发生在服务器的标识(server id) 事件的起始位置:(begin_log_pos 19364) 事件的结束位置:(end_log_pos 19486) 事件的类型:(Query) 事件发生时所在的服务器执行此事件的线程的ID:(thread_id=13) 语句的时间戳与将其写入二进制文件中的时间差:(exec_time=0) 错误代码:(error_code=0) 事件内容:(SET TIMESTAMP=1409298607/*!*/; GRANT SELECT ON tdb.* TO tuser@localhost) GTID事件专属: 事件所属的全局事务的GTID:(GTID 0-1-2)
12:MySQL 备份和恢复
备份策略的注意点
1:可容忍丢失多少数据 2:恢复需要在多长时间内完成 3:备份的对象: 数据、二进制日志和InnoDB的事务日志、SQL代码(存储过程和存储函数、触发器、事件调度器等)、服务器配置文件
备份类型
(1)站在数据集是否完整的角度上 完全备份,部分备份 (2)站在完全备份的基础上 增量备份,差异备份 (3)站在是否影响数据集读写的角度上 热备份:在线备份,读写操作不受影响; 温备份:在线备份,读操作可继续进行,但写操作不允许 冷备份:离线备份,数据库服务器离线,备份期间不能为业务提供读写服务 MyISAM存储引擎: 能够实现温备 InnoDB存储引擎: 能够实现热备 (4)站在数据存储角度上 物理备份:直接复制数据文件进行的备份 逻辑备份:从数据库中“导出”操作数据的SQL语句,再执行,实现备份
备份策略需要考虑的因素
持锁的时长
备份过程时长
备份负载
恢复过程时长
数据库备份具体解决方案
数据:完全备份 + 增量备份
备份:物理 + 逻辑
备份工具介绍
1:mysqldump: 逻辑备份工具,适用于所有存储引擎,温备;但是对InnoDB存储引擎支持热备; 2:scp, tar 等文件系统工具:物理备份工具,适用于所有存储引擎;冷备;完全备份,部分备份,不适用于Innodb存储引擎; 3:lvm2的快照:几乎热备;借助于文件系统工具实现物理备份; 4:mysqlhotcopy: 几乎冷备;仅适用于MyISAM存储引擎
实施备份期间,备份工具的常用组合
(一)mysqldump+binlog: mysqldump:完全备份,通过备份二进制日志实现增量备份 (二)lvm2快照+binlog: lvm2快照使用scp、tar进行物理完全备份 通过备份二进制日志实现增量备份 (三)xtrabackup(最佳) 由percana提供的热备,在物理层,实现完全备份和增量备份
MySQL 基于mysqldump备份工具的备份
先执行 show global variables like 'log_bin';看看log_bin的值,如果服务器变量log_bin的值为OFF,需要修改my.cnf配置文件,将log_bin=mysql-bin,再重启MySQL
mysqldump: 客户端SQL导出工具,通过mysql协议连接至mysqld服务器
(1)使用格式: mysqldump [选项] > backup.sql (2)选项说明 -A: 备份所有的数据库 -B 数据库1, 数据库2, 数据库3:指定需要备份的数据库 MyISAM, InnoDB: 温备 -x 或 --lock-all-tables:锁定所有表 -l 或 --lock-tables:锁定备份数据库中的表 InnoDB:热备 --single-transaction:启动一个大的单一事务实现备份 -B 或 --databases 数据库1,数据库2:备份指定的数据库 -C 或 --compress:压缩传输 注意:二进制文件不应该与数据文件放在同一个磁盘上
# 备份注意点:由于mysqldump只能实现数据库中指定数据库或数据表的完全备份,无法实现对表的单行或多行的增量备份,那么对应增量备份,将使用二进制文件进行备份 第一步: 使用mysqldump做完全备份,其中使用 --master-data=2 选项会在hellodb.sql中增加一条注释说明完全备份的结束位置,并且会显示完全备份结束后,滚到到了那个日志文件 mysqldump -uroot -h192.168.23.11 -p123456 -B TestDB --lock-tables --flush-logs > testdb.sql 第二步: 对完全备份之后的时间点到当前时间点做增量备份,在需要备份的服务器上操作,其中8631是完全备份后的时间点,因此,将从这个点开始到最后的日志文件的SQL语句都备份出来 (对于之后的每次增量做备份,可以无需指定开始时间,我们可以在增量备份之前将,二进制日志滚动,那么每次增量的时候,登入mysql使用 flush logs 命令,滚动日志,那么如何再有日志产生,将会写在下一个日志文件里,那么对于上一次增量备份到此时,可以直接使用客户端命令 mysqlbinlog /data/mysql/mysql-bin.000005 > increment.sql , 再将备份文件拷贝到备份的数据库中就可以了) mysqlbinlog /data/mysql/mysql-bin.000005 > increment.sql 第三步: set sql_log_bin = OFF; # 关闭二进制文件 show variables like 'sql_log_bin'; # 查看状态 第四步: 将hellodb.sql和increment.sql文件都拷贝到对应的数据恢复的主机上,将备份的SQL文件进行导入(关闭备份数据库服务器的二进制日志功能) mysql -p123456 < hellodb.sql mysql -p123456 < increment.sql 第五步: 当关闭二进制文件之后再导入文件系统上保存的SQL文件,但是SQL文件不要放在/root目录下面,因为/root目录对其它用户的权限是0,而mysqld进程的属主和属组都是mysql,因此无法进入/root目录里面,去读取SQL文件,切记 导入了SQL文件之后,在开启二进制文件 开启二进制文件 set sql_log_bin = ON; 查看状态 show variables like 'sql_log_bin'; 注意:SQL文件进行导入的时候不能一个同样的SQL进行重复导入,如果是插入语句,就会一直插入值
MySQL 基于lvm2的备份
实战过程如下:这里的演示是在一台Mariadb服务器上进行创建快照,将快照中的文件scp到备份服务器上的Mariadb的数据目录中,这样就实现了基于lvm2的备份 (1)新添加一块磁盘,将磁盘进行分区之后,先在分区上创建pv物理卷,然后在pv物理卷上创建vg卷组,之后在vg卷组上创建lv逻辑卷,将lv逻辑卷创建文件系统(使用ext4文件系统),将创建了文件系统的lv逻辑卷挂载至数据库目录,这里最好是创建两个lv逻辑卷,两个lv逻辑卷可以实现将数据库目录与二进制日志文件分开,分别放在不同的lv逻辑卷上,那么当使用lvcreate命令进行快照的时候,只对数据库目录进行快照,不对二进制文件进行快照,可以将 0: 添加一块硬盘,sdb给个40G就ok 1:fdisk /dev/sdb # 创建分区/dev/sdb1、/dev/sdb2,设置分区类型为linux lvm 2:partx -a /dev/sdb # 让内核重读 3:pvcreate /dev/sdb1 /dev/sdb2 # 创建两个pv 4:vgcreate myvg /dev/sdb1 /dev/sdb2 # 在两个pv上创建一个vg 5:lvcreate -L 20G -n mysql_data myvg # 创建一个名为mysql_data的逻辑卷 6:lvcreate -L 19.9G -n mysql_binlog myvg # 创建一个名为mysql_binlog的逻辑卷 7:mkfs -t ext4 /dev/myvg/mysql_data # 在mysql_data的逻辑卷逻辑卷上创建文件系统 8:mkfs -t ext4 /dev/myvg/mysql_binlog # 在mysql_binlog的逻辑卷上创建文件系统 9:mkdir -pv /data/{mysql,binlog} # 创建数据库目录和二进制文件目录 10:mount /dev/myvg/mysql_data /data/mysql # 挂载数据库目录 11:mount /dev/myvg/mysql_binlog /data/binlog # 挂载数据库目录 12:chown -R mysql.mysql /data # 让mysql用户可以读写 13:修改/etc/my.cnf配置文件:log-bin=/data/binlog/mysql-bin 和 datadir = /data/mysql 14:cd /usr/local/mysql/; ./scripts/mysql_install_db --user=mysql --datadir=/data/mysql # 如果是二级制或者编译安装的Mariadb这样初始化数据库,如果是yum安装的Mariadb,那么在数据库重启的时候自动hui 15:systemctl start mariadb.service # 启动Mariadb (2)在数据库依然提供服务的情况下,首先登入mysql数据库,请求锁定所有的表,添加读锁,这个时候所有的数据表只能够读数据,不能够写数据 1:flush tables with read lock; (3)让二进制日志文件滚动跟新,并且记录新的二进制文件的开始位置,那么数据库新的数据更改操作将记录到新的二进制文件中,做增量备份的时候需要再次滚动二进制日志,并且导出当前的日志为SQL文件 这里的日志滚动其实可以不要 flush logs; (4)使用lvcreate 命令创建快照 查看现在数据目录有多大了,如果是40M,那么创建快照的时候给个50M就ok了 du -sh /data/mysql 创建名为lvm_snap的快照 ,-s 表示创建快照,-p r 表示快照的权限是只读的,-n 表示快照的名,此时就会在生成一个/dev/myvg/lvm_snap的快照 lvcreate -L 50M -s -p r -n lvm_snap /dev/myvg/mysql_data (5)释放读锁,MySQL服务器可以读写正常工作,此时立马让日志滚动一下,让之后的所有操作都记录在新的二进制文件中 unlock tables; flush tables (6)将快照挂载,将数据库目录通过文件系统命令cp -a等不修改属性和时间戳的情况下拷贝 mount /dev/myvg/lvm_snap /mnt scp -rp /mnt/* 192.168.23.32:/data/mysql 试一试这里是否需要拷贝二进制文件,如果不拷贝二进制文件,那么备份服务器使用的二进制文件应该是从第一个开始的。但是,现在只需要备份数据,所以拷贝二进制文件也是可以的。 scp -rp /data/binlog/* 192.168.23.32:/data/binlog/ 此时在192.168.23.32这台Mariadb备份服务器中,已经存在Mariadb的数据目录/data/mysql和二进制目录/data/binlog/,且配置文件/etc/my.cnf都已经配置完毕。在这个时候,还需要修改/data目录的属主和属组,在192.168.23.32这台Mariadb备份服务器中操作如下: chown -R mysql.mysql /data (7)使用客户端命令mysqlbinlog 导出SQL文件 mysqlbinlog /data/binlog/`mysql -p123456 -e 'show master status;' | grep mysql-bin | awk '{print $1}'` > increment.sql (8)使用scp命令将数据库目录、导出的SQL文件拷贝到备份的MySQL服务器上,在备份的MySQL服务器上将数据库目录放在对应的数据库目录,并且导入增量备份的SQL文件 scp -rp increment1.sql 192.168.23.11:/root/ mysql -p123456 < increment.sql (9)之后的备份,均使用二进制文件做增量备份即可,备份前切记先滚动新的日志文件,再将当前二进制日志文件导出为SQL文件即可 mysql -p123456 -e 'flush logs;' mysqlbinlog /data/binlog/`mysql -p123456 -e 'show master status;' | grep mysql-bin | awk '{print $1}'` > increment2.sql scp increment2.sql 192.168.23.32:/root/ 在备份的服务器上执行导入增量的sql备份文件 mysql -p123456 increment2.sql
基于xtrabackup备份—热备工具
完全备份
1:在配置文件里面,设置主服务器和备份服务器的数据目录为/data/mysql, 二进制目录为/data/binlog datadir=/data/mysql log_bin=/data/binlog/mysql-bin innodb_file_per_table=on 2:在主服务器里面创建数据库,创建表,插入数据,使用innobackupex进行完全备份 innobackupex --user=root --password=123456 /backup 3:将完全备份拷贝到备份服务器 scp -pr /backup/2016-08-30_21-55-01 192.168.23.32:/root/ 4:在备份服务器停止Mariadb,先整理完全备份的事务 innobackupex --apply-log /root/2016-08-30_21-55-01 5:再导入数据,此时会在备份服务器上创建数据目录为/data/mysql, 二进制目录为/data/binlog innobackupex --copy-back /root/2016-08-30_21-55-01 6:最后将备份服务器的数据目录的属主和属组修改为mysql chown -R mysql.mysql /data/ 7:在备份服务器启动Mariadb,检查是否备份完毕 systemctl start mariadb.service
增量备份
1:完全备份之后,我们再来增量备份,现在主服务器上创建其他的数据库,和表,已经插入数据 2:基于刚刚创建的完全备份,再创建增量备份 innobackupex --user=root --password=123456 --incremental /backup/ --incremental-basedir=/backup/2016-08-30_21-55-01 3:再整理完全备份 innobackupex --apply-log --redo-only /backup/2016-08-30_21-55-01 4:将增量备份合并到完全备份 innobackupex --apply-log --redo-only /backup/2016-08-30_21-55-01 --incremental-dir=/backup/2016-08-30_23-16-04 5:将完全备份拷贝到备份服务器,这会覆盖之前备份服务器上的完全备份 scp -pr /backup/2016-08-30_21-55-01 192.168.23.32:/root/ 6:将备份服务器停止,在备份服务器上还原数据 innobackupex --copy-back /root/2016-08-30_21-55-01 7:修改数据目录的属主和属组为mysql chown -R mysql.mysql /data/
13:MySQL 高可用
主从模式
主节点 (192.168.23.10) (1)编译配置文件,启动二进制日志 ,为当前节点设置一个全局唯一的id号 编辑/etc/my.cnf,添加如下信息 log_bin=/data/binlog/master-bin (一定要让mysql用户对/data/binlog有读写权限) server_id = 1 innodb_file_per_table=on skip_name_resolve=on (2)创建一个有复制权限的用户账号 grant replication slave,replication client on *.* to repluser@'192.168.23.%' identified by '123456'; flush privileges; 从节点 (192.168.23.11) (1)编辑配置文件/etc/my.cnf启动中继日志, 设置一个全局唯一的id号 relay_log = relay-log relay_log_index=relay-log.index server_id = 2 innodb_file_per_table=on skip_name_resolve=on (2)使用有复制权限的用户账号连接至主服务器,并启动复制线程 change master to master_host = '192.168.23.10',master_user = 'repluser',master_password = '123456',master_log_file = 'master-bin.000005',master_log_pos = 245; show slave statusG : 查看slave节点的信息 start slave; :指明启动I/O线程和SQL线程
注意点
问:如果主节点已经运行了一段时间,且有大量的数据,如何启动slave节点
答:如果主服务器已近启动了一段时间了,那么这个时间点之前的数据使用完全备份到从服务器,并且记录备份的position,因此再从主节点新的二进制文件开始做主从同步
复制架构中应该注意的问题
1: 从服务器为只读模式,不能写 第一种方案:在从服务器上设置:read_only = ON,此限制对root用户无效 第二种方案:阻止所有的用户,给表加锁 flush tables with read lock; # master_info记录了主节点的信息,这就是为什么重新启动MySQL的时候会自动连接复制功能 sync_master_info = 1 2:如何保证主从复制的事务安全 (1)在master节点启用参数 sync_binlog = ON :提交之后内存中的事务立马写到磁盘上 如果用到的为InnoDB存储引擎 innodb_flush_logs_at_trx_commit = ON :将内存中的事务日志写在磁盘上 innodb_support_xa = ON : 是否支持分布式事务 (2)在slave节点 skip_slave_start = ON : 指定手动启动复制功能,不要自动启动复制功能 sync_relay_log = 1; sync_relay_log_info = 1;
MySQL 半同步复制模型
所谓的半同步复制指的是:一台主节点有多个从节点,在众多的从节点之中有一个从节点在收到主节点的二进制日志信息之后,存储在中继日志中,执行中继日志后,给主节点一个反馈信息,直接点收到这个反馈信息之后,返回给执行这句SQL的ORM语句,表示数据已经存储完毕。其他的从节点同样以异步的方式执行中继日志中的SQL语句
1: 编辑主节点的配置文件 innodb_file_per_table=on skip_name_resolve=on log_bin=master-bin # 开启二进制日志 server_id = 1 2: 编辑从节点的配置文件 relay_log = relay-log # 开启中继日志 relay_log_index=relay-log.index # 开启中继日志管理功能 server_id = 2 innodb_file_per_table=on skip_name_resolve=on 3: 登入主节点 grant replication slave,replication client on *.* to repluser@'192.168.23.%' identified by '123456'; # 授权同步用户 flush privileges; install plugin rpl_semi_sync_master soname 'semisync_master.so'; # 安装插件 show plugins; # 查看插件 set global rpl_semi_sync_master_enabled = ON; # 开启半同步功能 show global status like '%semi%'; 4:登入从节点 install plugin rpl_semi_sync_slave soname 'semisync_slave.so'; # 安装插件 show plugins; # 查看插件 set global rpl_semi_sync_slave_enabled = ON; # 开启半同步功能 # 这里注意先查看一下主节点的 show master status; change master to master_host = '192.168.23.10',master_user = 'repluser' , master_password = '123456', master_log_file = 'master-bin.000004',master_log_pos = 494; # 添加主节点的信息 show global status like '%semi%'; # 查看是否开启半同步 start slave; # 开始同步 建议:半同步复制最好就是只设置一个半同步的从服务器,其他的都是普通的从服务器
MySQL MHA模型
MHA对主节点进行监控,可实现自动故障转移至其他的从节点,提升从节点为新的主节点,实现主节点的高可用
配置环境说明
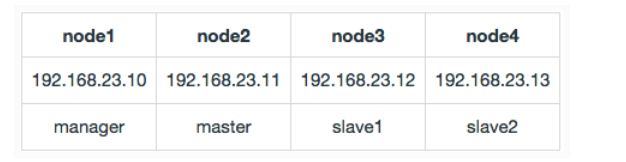
准备配置四个节点,并且通过主机名解析
这里需要特别的说明一下,ssh的密钥认证的问题。 以前我们使用ssh基于密钥认证时,通常是在不同的主机上通过ssh创建公钥和私钥,这使得我们的操作过程繁琐。那么是否在一个集群里面只使用一个公钥和私钥就实现非口令ssh连接呢? 这是可以的,通过在一台主机上生成一个RSA的密钥对,然后将公钥的信息拷贝到authorized_keys文件里,然后再将公钥文件删除。在.ssh目录中只留下私钥文件和认证文件,再通过SCP将整个的.ssh目录推送到其他的主机,这样就实现了繁琐的在不同的主机上创建密钥对的过程 其中的ssh通过密钥登入的原理是这样的:一台主机通过ssh命令连接到其他主机时,其他主机会通过.ssh目录中的authorized_keys文件对连接进来的主机的id_rsa私钥文件进行密钥配对。而authorized_keys文件中会保存连接进来的主机的id_rsa.pub公钥文件的信息,如果配对成功,那么就可以登入连接。 具体的过程如下: # 在node1 执行 ssh-keygen -t rsa -P '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys rm -f /root/.ssh/id_rsa.pub # 公钥的文件中的信息已经拷贝到authorized_keys文件中,因此可以删除公钥文件 chmod 600 /root/.ssh/authorized_keys # 将权限修改一下,认证文件必须600 scp -rp /root/.ssh node2:/root/.ssh scp -rp /root/.ssh node3:/root/.ssh scp -rp /root/.ssh node4:/root/.ssh 小结:那么在node1、node2、node3、node4文件中的所有的ssh认证将通过一个密钥对实现登入
node2, node3 , node4的配置文件/etc/my.cnf分别如下
# node2 log_bin = master-bin relay_log = relay-bin server_id = 1 skip_name_resolve = ON innodb_file_per_table = ON # node3 log_bin = master-bin relay_log = relay-bin server_id = 2 skip_name_resolve = ON innodb_file_per_table = ON read_only = ON # 从节点只读 relay_log_purge = OFF # 自动清理的功能关闭 # node4 log_bin = master-bin relay_log = relay-bin server_id = 3 skip_name_resolve = ON innodb_file_per_table = ON read_only = ON relay_log_purge = OFF
4:将node2, node3, node4 的数据库目录都设置为/data/mysql,这里选择RPM包安装的MariaDB,直接启动就是。如何是编译安装的MariaDB需要先对/data/mysql进行初始化才能启动
5:将node2, node3, node4登入mysql,在node2,先查看当前使用的是哪个二进制日志和记录到了哪个点,并且授权一个允许在主节点复制的用户, 并且,在node3和node4上设置复制的主节点,请求开启复制
# node2 show master status; grant replication slave,replication client on *.* to repluser@'192.168.23.%' identified by '123456'; flush privileges; # node3 change master to master_host='192.168.23.11',master_user='repluser',master_password='123456',master_log_file='master-bin.000003',master_log_pos=245; start slave; show slave statusG # 查看两个thread是否都是yes,如果不是说明复制有错误 # node4 change master to master_host='192.168.23.11',master_user='repluser',master_password='123456',master_log_file='master-bin.000003',master_log_pos=245; start slave; show slave statusG # 查看两个thread是否都是yes,如果不是说明复制有错误
在node2主节点上授权一个mha的管理用户,这个SQL语句会通过同步到node3和node4上,因此在node3和node4上检验一下,是否该用户存在即可
grant all on *.* to mhauser@'192.168.23.%' identified by '123456'; flush privileges;
在node1上安装mha4mysql-manager和mha4mysql-node(把RPM包下载到本地)
yum install -y mha4mysql-node-0.54-0.el6.noarch.rpm yum install -y mha4mysql-manager-0.55-0.el6.noarch.rpm
在node2、node3、node4上安装mha4mysql-node(把RPM包下载到本地)
yum install -y mha4mysql-node-0.54-0.el6.noarch.rpm
对安装的MHA的配置文件进行说明
配置文件 global配置项:为各个application提供默认配置 application配置项:各个不同的节点的专用配置 在node1(mha)上配置application信息, mkdir -pv /etc/masterha vi /etc/masterha/app1.cnf
/etc/masterha/app1.cnf 文件中的信息如下
[server default] user=mhauser # 管理所有的节点的用户 password=123456 manager_workdir=/data/masterha/app1 # 工作目录,用于放置二进制文件 manager_log=/data/masterha/app1/manager.log # 日志文件 remote_workdir=/data/masterha/app1 ssh_user=root repl_user=repluser repl_password=123456 ping_interval=1 master_binlog_dir=/data/mysql [server1] hostname=192.168.23.32 #ssh_port=22 [server2] hostname=192.168.23.33 #ssh_port=22 #candidate_master=1 [server3] hostname=192.168.23.34 #ssh_port=22 # 指明不提示为主节点 #no_master=1
在manager节点上检查ssh通信是否OK
masterha_check_ssh --conf=/etc/masterha/app1.cnf
在manager节点上检查replication是否ok
masterha_check_repl --conf=/etc/masterha/app1.cnf
前端启动一下mha-manager
masterha_manager --conf=/etc/masterha/app1.cnf
将主节点的mysqld 和mysqld_safe杀掉
killall mysqld mysqld_safe # 这时候,看看其他节点的状态,show slave status,可以查看 show global variables like 'read_only', 看看当前新的主节点是否已经关闭了只读功能 显示结果为node3为主节点,node4依然是从节点
让被杀掉的主节点重新上线,但是为从节点了
# 编辑配置文件/etc/my.cnf添加两个参数 read_only = ON 和 relay_log_purge = OFF # 删除/data/mysql/所有的数据 rm -fr /data/mysql/* systemctl start mariadb.service # 登入到mysql,在启动slave复制功能之前,需要先将新的主节点的数据全部备份下来,并且导入,记录备份完成之后,滚动到的新的二进制日志文件和position,然后再启动slave,指定从记录下的二进制文件和position位置开始复制 # 但是在这里,由于没有对主服务器插入数据,那么我们只有手动的创建复制用户和管理用户,再开启slave复制功能 grant all on *.* to mhauser@'192.168.23.%' identified by '123456'; grant replication slave,replication client on *.* to repluser@'192.168.23.%' identified by '123456'; flush privileges; change master to master_host='192.168.23.12',master_user='repluser',master_password='123456',master_log_file='master-bin.000003',master_log_pos= 882; start slave; show slave status;
在重新启动mhamanager,并且检查ssh和replication是否OK
masterha_check_ssh --conf=/etc/masterha/app1.cnf masterha_check_repl --conf=/etc/masterha/app1.cnf masterha_check_status --conf=/etc/masterha/app1.cnf
停止mhamanager
masterha_stop --conf=/etc/masterha/app1.cnf
1.SELECT语句子句
- 子句的书写顺序:where -> group by -> having -> order by -> limit ;
(1)where子句
-
指明过滤条件;
-
between较小的数and较大的数; -
in(较小的数,较大的数); -
is null或is not null; -
like模糊匹配;
(2)group by 子句
-
根据指定的查询条件将查询结构进行分组,用于做聚合运算;
-
聚合函数:
avg( )、max( )、min( )、count( )、sum( );
(3)having子句
- 将分组之后的结果再次过滤;
(4)order by子句
- 根据指定的字段对查询结果进行排序,默认为升序,降序使用关键字desc;
(5)limit 子句
- 对查询的结果进行输出行数的限制 ;
2.键的概念
-
键:数据库中的键(key)又称为关键字,是关系模型中的一个重要概念,它是逻辑结构,不是数据库的物理部分;
-
唯一键:即一个或者一组列,其中没有重复的记录,可以唯一标示一条记录;
-
主键:属于唯一键,是一个比较特殊的唯一键,区别在于主键不可为空;
-
外键:一张表外键的值一般来说是另一张表主键的值,因此,外键的存在使得表与表之间可以联系起来;
3.索引的概念
-
索引就像是一张表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据,保存索引数据的文件一般会与保存数据的目录分开;
-
索引应该构建在经常被用作查询条件的字段上;
4.索引类型
-
普通索引:加速查询;
-
唯一索引:加速查询 + 列值唯一(可以有null);
-
主键索引:加速查询 + 列值唯一 + 表中只有一个(不可以有null);
-
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并;
-
全文索引:对文本的内容进行分词,进行搜索;
-
空间索引:指依据空间对象的位置和形状或空间对象之间的某种空间关系按一定的顺序排列的一种数据结构;
5.Innodb 存储引擎
-
所有的InnoDB表的数据和索引存储于同一个表文件中,但是表数据和表结构分离;
-
Mariadb默认的存储引擎是XtraDB,但是为了与MySQL兼容,因此也取名做InnoDB,因为MySQL的默认存储引擎是InnoDB;
-
使用聚集索引(数据和索引在一起),也支持自适应hash索引,锁粒度为行级别,支持支持热备工具;
-
支持事务的存储引擎,适合处理大量的短期事务;
6.MyISAM 存储引擎
-
所有的MyISAM表的数据和索引存放在不同的文件中,表结构也分离;
-
支持全文索引(fulltext index),压缩,空间函数;
-
不支持事物,表级锁,适用于只读,读多写少;
7.MySQL的并发访问控制
-
任何的数据集只要支持并发访问模型就必须基于锁机制进行访问控制;
-
读锁:共享锁,允许给其他人读,不允许他人写;
-
写锁:独占锁, 不允许其他人读和写;
-
显示锁:用户手动请求读锁或写锁;
-
隐式锁:由存储引擎自行根据需要加的,无需我们管理;
8.MySQL事务机制
- 一组原子性的SQL查询,或多个SQL语句组成了一个独立的单元,要么这一组SQL语句全部执行,要么全部不执行;
ACID机制:
-
automicity:原子性,整个事物中的所有操作要么全部成功提交,要么全部失败回滚; -
consistency:一致性,数据库总是从一个一致性状态转化为另一个一致性状态; -
isolation: 隔离性,事物不会相互影响,一个事物所作出的操作在提交之前,是不能为其他事物所见,隔离有多种级别,主要是为了并发; -
durability:持久性,事物一旦提交,其所作的修改会保存在数据库中,不能丢失;
9.MySQL 查询缓存机制
-
缓存的是查询语句的整个查询结果,是一个完整的select语句的缓存结果;
-
哪些查询可能不会被缓存 :查询中包含UDF、存储函数、用户自定义变量、临时表、mysql库中系统表、或者包含列级别的权限表、有着不确定值的函数;
10.MySQL 日志分类
-
查询日志 :query log ,一般不启用;
-
慢查询日志:slow_query_log ,用于对执行速率较慢的SQL语句就像过滤,有利于SQL代码的优化;
-
错误日志:error log ,必须启用;
-
二进制日志:binary log,用于通过'重新执行'日志文件中的记录的事件(SQL语句)来生成数据副本,也就是用于主从复制;
-
中继日志:relay log ,在主从复制架构中,从服务器用于保存从主服务器的二进制日志中读取到的时间;
-
事务日志:transaction log ,事物日志由事物型存储引擎自行管理和使用,无需手动管理;
11.MySQL 备份策略的注意点
-
可容忍丢失多少数据;
-
恢复需要在多长时间内;
-
备份的对象: 数据、二进制日志和InnoDB的事务日志、SQL代码(存储过程和存储函数、触发器、事件调度器等)、服务器配置文件;
12.备份策略需要考虑的因素
-
持锁的时长;
-
备份过程时长;
-
备份负载;
-
恢复过程时长;
13.MySQL 半同步复制模型
- 所谓的半同步复制指的是一台主节点有多个从节点,在众多的从节点之中有一个从节点在收到主节点的二进制日志信息之后,存储在中继日志中,执行中继日志后,给主节点一个反馈信息,直接点收到这个反馈信息之后,返回给执行这句SQL的ORM语句,表示数据已经存储完毕;