同步异步-阻塞非阻塞
阻塞-非阻塞 指的是程序的运行状态
阻塞:当程序执行过程中遇到了IO操作,在执行IO操作时,程序无法继续执行其他代码,称为阻塞。
非阻塞:程序在正常运行没有遇到IO操作,或者通过某种方式使程序即使遇到了也不会停在原地,还可以执行其他操作,以提高CPU的占用率。
同步-异步 指的是提交任务的方式
同步指调用:发起任务后必须在原地等待任务执行完成功能,才能继续执行,比如进行一亿次计算,在原地等待,但没有IO操作,不是阻塞
异步指调用:发起任务后不用等待任务执行,可以立即开启执行其他操作。其实就是开启一个线程或进程
同步会有等待的效果但是这和阻塞是完全不同的,阻塞时程序会被剥夺CPU执行权,而同步调用不会
程序中的异步调用并获取结果方式1:
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time
pool = ThreadPoolExecutor(3)
def task(i):
time.sleep(0.01)
print(current_thread().name,"working..")
return i ** i
if __name__ == '__main__':
objs = []
for i in range(3):
res_obj = pool.submit(task,i) # 异步方式提交任务# 会返回一个对象用于表示任务结果
objs.append(res_obj)
# 该函数默认是阻塞的 会等待池子中所有任务执行结束后执行
pool.shutdown(wait=True)
# 从结果对象中取出执行结果
for res_obj in objs:
print(res_obj.result())
print("over")
程序中的异步调用并获取结果方式2:
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time
pool = ThreadPoolExecutor(3)
def task(i):
time.sleep(0.01)
print(current_thread().name,"working..")
return i ** i
if __name__ == '__main__':
objs = []
for i in range(3):
res_obj = pool.submit(task,i) # 会返回一个对象用于表示任务结果
print(res_obj.result()) #result是同步的一旦调用就必须等待 任务执行完成拿到结果
print("over")
异步回调
什么是异步回调
异步回调指的是:在发起一个异步任务的同时指定一个函数,在异步任务完成时会自动的调用这个函数
为什么需要异步回调
异步效率要高于同步,但是异步任务将导致一个问题就是任务的发起方不知道任务何时处理完毕
解决方案:
1. 轮询:重复的每隔一段时间就问一次,但是效率低,无法及时拿到任务结果
2. 让任务的发起方主动通知(异步回调),推荐方式,可以及时拿到任务结果
之前在使用线程池或进程池提交任务时,如果想要处理任务的执行结果则必须调用result函数或是shutdown函数,而它们都是是阻塞的,会等到任务执行完毕后才能继续执行,这样一来在这个等待过程中就无法执行其他任务,降低了效率,所以需要一种方案,即保证解析结果的线程不用等待,又能保证数据能够及时被解析,该方案就是异步回调
异步回调的使用
在线程中使用:

在线程池中使用:
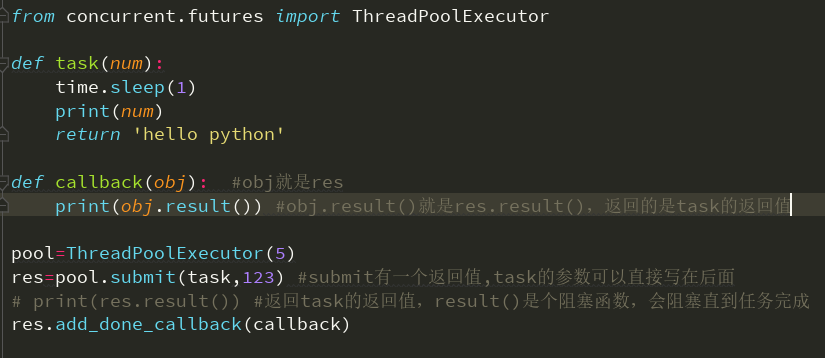
再来看一个案例:
在编写爬虫程序时,通常都是两个步骤:
1.从服务器下载一个网页文件
2.读取并且解析文件内容,提取有用的数据
按照以上流程可以编写一个简单的爬虫程序
要请求网页数据则需要使用到第三方的请求库requests可以通过pip或是pycharm来安装,在pycharm中点击settings->解释器->点击+号->搜索requests->安装
import requests,re,os,random,time
from concurrent.futures import ProcessPoolExecutor
def get_data(url):
print("%s 正在请求%s" % (os.getpid(),url))
time.sleep(random.randint(1,2))
response = requests.get(url)
print(os.getpid(),"请求成功 数据长度",len(response.content))
#parser(response) # 3.直接调用解析方法 哪个进程请求完成就那个进程解析数据 强行使两个操作耦合到一起了
return response
def parser(obj):
data = obj.result()
htm = data.content.decode("utf-8")
ls = re.findall("href=.*?com",htm)
print(os.getpid(),"解析成功",len(ls),"个链接")
if __name__ == '__main__':
pool = ProcessPoolExecutor(3)
urls = ["https://www.baidu.com",
"https://www.sina.com",
"https://www.python.org",
"https://www.tmall.com",
"https://www.mysql.com",
"https://www.apple.com.cn"]
# objs = []
for url in urls:
# res = pool.submit(get_data,url).result() # 1.同步的方式获取结果 将导致所有请求任务不能并发
# parser(res)
obj = pool.submit(get_data,url) #
obj.add_done_callback(parser) # 4.使用异步回调,保证了数据可以被及时处理,并且请求和解析解开了耦合
# objs.append(obj)
# pool.shutdown() # 2.等待所有任务执行结束在统一的解析
# for obj in objs:
# res = obj.result()
# parser(res)
# 1.请求任务可以并发 但是结果不能被及时解析 必须等所有请求完成才能解析
# 2.解析任务变成了串行,
总结:异步回调使用方法就是在提交任务后得到一个Futures对象,调用对象的add_done_callback来指定一个回调函数,
如果把任务比喻为烧水,没有回调时就只能守着水壶等待水开,有了回调相当于换了一个会响的水壶,烧水期间可用作其他的事情,等待水开了水壶会自动发出声音,这时候再回来处理。水壶自动发出声音就是回调。
注意:
- 使用进程池时,回调函数都是主进程中执行执行
- 使用线程池时,回调函数的执行线程是不确定的,哪个线程空闲就交给哪个线程
- 回调函数默认接收一个参数就是这个任务对象自己,再通过对象的result函数来获取任务的处理结果
线程队列
1.Queue先进先出队列
与多进程中的Queue使用方式完全相同,区别仅仅是不能被多进程共享。
q = Queue(3)
q.put(1)
q.put(2)
q.put(3)
print(q.get(timeout=1))
print(q.get(timeout=1))
print(q.get(timeout=1))
2.LifoQueue 后进先出队列
该队列可以模拟堆栈,实现先进后出,后进先出
lq = LifoQueue()
lq.put(1)
lq.put(2)
lq.put(3)
print(lq.get())
print(lq.get())
print(lq.get())
3.PriorityQueue 优先级队列
该队列可以为每个元素指定一个优先级,这个优先级可以是数字,字符串或其他类型,但是必须是可以比较大小的类型,取出数据时会按照从小到大的顺序取出
pq = PriorityQueue()
# 数字优先级
pq.put((10,"a"))
pq.put((11,"a"))
pq.put((-11111,"a"))
print(pq.get())
print(pq.get())
print(pq.get())
# 字符串优先级
pq.put(("b","a"))
pq.put(("c","a"))
pq.put(("a","a"))
print(pq.get())
print(pq.get())
print(pq.get())
线程时间Event
什么是事件
事件表示在某个时间发生了某个事情的通知信号,用于线程间协同工作。
因为不同线程之间是独立运行的状态不可预测,所以一个线程与另一个线程间的数据是不同步的,当一个线程需要利用另一个线程的状态来确定自己的下一步操作时,就必须保持线程间数据的同步,Event就可以实现线程间同步
Event介绍
Event象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
可用方法:
event.isSet():返回event的状态值;
event.wait():将阻塞线程;知道event的状态为True
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
使用案例:
# 在链接mysql服务器前必须保证mysql已经启动,而启动需要花费一些时间,所以客户端不能立即发起链接 需要等待msyql启动完成后立即发起链接
from threading import Event,Thread
import time
boot = False
def start():
global boot
print("正正在启动服务器.....")
time.sleep(5)
print("服务器启动完成!")
boot = True
def connect():
while True:
if boot:
print("链接成功")
break
else:
print("链接失败")
time.sleep(1)
Thread(target=start).start()
Thread(target=connect).start()
Thread(target=connect).start()
使用Event改造后:
from threading import Event,Thread
import time
e = Event()
def start():
global boot
print("正正在启动服务器.....")
time.sleep(3)
print("服务器启动完成!")
e.set()
def connect():
e.wait()
print("链接成功")
Thread(target=start).start()
Thread(target=connect).start()
Thread(target=connect).start()
增加需求,每次尝试链接等待1秒,尝试次数为3次
from threading import Event,Thread
import time
e = Event()
def start():
global boot
print("正正在启动服务器.....")
time.sleep(5)
print("服务器启动完成!")
e.set()
def connect():
for i in range(1,4):
print("第%s次尝试链接" % i)
e.wait(1)
if e.isSet():
print("链接成功")
break
else:
print("第%s次链接失败" % i)
else:
print("服务器未启动!")
Thread(target=start).start()
Thread(target=connect).start()
# Thread(target=connect).start()