编程论到极致,核心非代码,即思想。
所以,真正的编程高手同时是思想独到及富有智慧(注意与聪明区别)的人。
每一个算法都是一种智慧的凝聚或萃取,值得我们学习从而提高自己,开拓思路,更重要的是转换思维角度。
其实,我们大多数人都活在“默认状态”下。没有发觉自己的独特可设置选项-----思想。
言归正传(呵呵!恢复默认状态),以下学习基数排序。
【1】基数排序
以前研究的各种排序算法,都是通过比较数据大小的方法对欲排数据序列进行排序整理过程。
而基数排序却不再相同,那么,基数排序是采用怎样的策略进行排序的呢?
简略概述:基数排序是通过“分配”和“收集”过程来实现排序。而这个思想该如何理解呢?请看以下例子。
(1)假设有欲排数据序列如下所示:
73 22 93 43 55 14 28 65 39 81
首先根据个位数的数值,在遍历数据时将它们各自分配到编号0至9的桶(个位数值与桶号一一对应)中。
分配结果(逻辑想象)如下图所示:
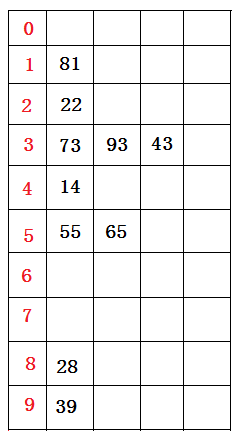
分配结束后。接下来将所有桶中所盛数据按照桶号由小到大(桶中由顶至底)依次重新收集串起来,得到如下仍然无序的数据序列:
81 22 73 93 43 14 55 65 28 39
接着,再进行一次分配,这次根据十位数值来分配(原理同上),分配结果(逻辑想象)如下图所示:
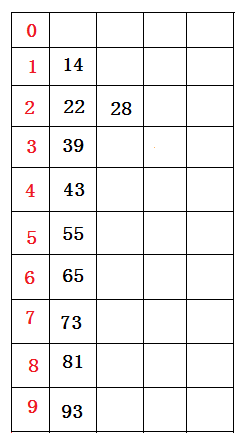
分配结束后。接下来再将所有桶中所盛的数据(原理同上)依次重新收集串接起来,得到如下的数据序列:
14 22 28 39 43 55 65 73 81 93
观察可以看到,此时原无序数据序列已经排序完毕。如果排序的数据序列有三位数以上的数据,则重复进行以上的动作直至最高位数为止。
那么,到这里为止,你觉得你是不是一个细心的人?不要不假思索的回答我。不论回答什么样的问题,都要做到心比头快,头比嘴快。
仔细看看你对整个排序的过程中还有哪些疑惑?真看不到?觉得我做得很好?抑或前面没看懂?
如果你看到这里真心没有意识到或发现这个问题,那我告诉你:悄悄去找个墙角蹲下用小拇指画圈圈(好好反省反省)。
追问:观察原无序数据序列中73 93 43 三个数据的顺序,在经过第一次(按照个位数值,它们三者应该是在同一个桶中)分配之后,
在桶中顺序由底至顶应该为73 93 43(即就是装的迟的在最上面,对应我们上面的逻辑想象应该是43 93 73),对吧?这个应该可以想明白吧?理论上应该是这样的。
但是,但是,但是分配后很明显在3号桶中三者的顺序刚好相反。这点难道你没有发现吗?或者是发现了觉得不屑谈及(算我贻笑大方)?
其实这个也正是基数排序稳定性的原因(分配时由末位向首位进行),请看下文的详细分析。
再思考一个问题:既然我们可以从最低位到最高位进行如此的分配收集,那么是否可以由最高位到最低位依次操作呢? 答案是完全可以的。
基于两种不同的排序顺序,我们将基数排序分为LSD(Least significant digital)或MSD(Most significant digital),
LSD的排序方式由数值的最右边(低位)开始,而MSD则相反,由数值的最左边(高位)开始。
注意一点:LSD的基数排序适用于位数少的数列,如果位数多的话,使用MSD的效率会比较好。
MSD的方式与LSD相反,是由高位数为基底开始进行分配,但在分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中。
在进行完最低位数的分配后再合并回单一的数组中。
(2)我们把扑克牌的排序看成由花色和面值两个数据项组成的主关键字排序。
要求如下:
花色顺序:梅花<方块<红心<黑桃
面值顺序:2<3<4<...<10<J<Q<K<A
那么,若要将一副扑克牌排成下列次序:
梅花2,...,梅花A,方块2,...,方块A,红心2,...,红心A,黑桃2,...,黑桃A。
有两种排序方法:
<1>先按花色分成四堆,把各堆收集起来;然后对每堆按面值由小到大排列,再按花色从小到大按堆收叠起来。----称为"最高位优先"(MSD)法。
<2>先按面值由小到大排列成13堆,然后从小到大收集起来;再按花色不同分成四堆,最后顺序收集起来。----称为"最低位优先"(LSD)法。
【2】代码实现
(1)MSD法实现
最高位优先法通常是一个递归的过程:
<1>先根据最高位关键码K1排序,得到若干对象组,对象组中每个对象都有相同关键码K1。
<2>再分别对每组中对象根据关键码K2进行排序,按K2值的不同,再分成若干个更小的子组,每个子组中的对象具有相同的K1和K2值。
<3>依此重复,直到对关键码Kd完成排序为止。
<4> 最后,把所有子组中的对象依次连接起来,就得到一个有序的对象序列。
示例代码如下:
1 #include<iostream>
2 #include<malloc.h>
3 using namespace std;
4
5 int getdigit(int x,int d)
6 {
7 int a[] = {1, 1, 10}; //因为待排数据最大数据也只是两位数,所以在此只需要到十位就满足
8 return ((x / a[d]) % 10); //确定桶号
9 }
10
11 void PrintArr(int ar[],int n)
12 {
13 for(int i = 0; i < n; ++i)
14 cout<<ar[i]<<" ";
15 cout<<endl;
16 }
17
18 void msdradix_sort(int arr[],int begin,int end,int d)
19 {
20 const int radix = 10;
21 int count[radix], i, j;
22 //置空
23 for(i = 0; i < radix; ++i)
24 {
25 count[i] = 0;
26 }
27 //分配桶存储空间
28 int *bucket = (int *) malloc((end-begin+1) * sizeof(int));
29 //统计各桶需要装的元素的个数
30 for(i = begin;i <= end; ++i)
31 {
32 count[getdigit(arr[i], d)]++;
33 }
34 //求出桶的边界索引,count[i]值为第i个桶的右边界索引+1
35 for(i = 1; i < radix; ++i)
36 {
37 count[i] = count[i] + count[i-1];
38 }
39 //这里要从右向左扫描,保证排序稳定性
40 for(i = end;i >= begin; --i)
41 {
42 j = getdigit(arr[i], d); //求出关键码的第d位的数字, 例如:576的第3位是5
43 bucket[count[j]-1] = arr[i]; //放入对应的桶中,count[j]-1是第j个桶的右边界索引
44 --count[j]; //第j个桶放下一个元素的位置(右边界索引+1)
45 }
46 //注意:此时count[i]为第i个桶左边界
47 //从各个桶中收集数据
48 for(i = begin, j = 0;i <= end; ++i, ++j)
49 {
50 arr[i] = bucket[j];
51 }
52 //释放存储空间
53 free(bucket);
54 //对各桶中数据进行再排序
55 for(i = 0;i < radix; i++)
56 {
57 int p1 = begin + count[i]; //第i个桶的左边界
58 int p2 = begin + count[i+1]-1; //第i个桶的右边界
59 if(p1 < p2 && d > 1)
60 {
61 msdradix_sort(arr, p1, p2, d-1); //对第i个桶递归调用,进行基数排序,数位降 1
62 }
63 }
64 }
65
66 void main()
67 {
68 int ar[] = {12, 14, 54, 5, 6, 3, 9, 8, 47, 89};
69 int len = sizeof(ar)/sizeof(int);
70 cout<<"排序前数据如下:"<<endl;
71 PrintArr(ar, len);
72 msdradix_sort(ar, 0, len-1, 2);
73 cout<<"排序后结果如下:"<<endl;
74 PrintArr(ar, len);
75 }
76 /*
77 排序前数据如下:
78 12 14 54 5 6 3 9 8 47 89
79 排序后结果如下:
80 3 5 6 8 9 12 14 47 54 89
81 */
(2)LSD法实现
最低位优先法首先依据最低位关键码Kd对所有对象进行一趟排序,
再依据次低位关键码Kd-1对上一趟排序的结果再排序,
依次重复,直到依据关键码K1最后一趟排序完成,就可以得到一个有序的序列。
使用这种排序方法对每一个关键码进行排序时,不需要再分组,而是整个对象组。
示例代码如下:
1 #include<iostream>
2 #include<malloc.h>
3 using namespace std;
4
5 #define MAXSIZE 10000
6
7 int getdigit(int x,int d)
8 {
9 int a[] = {1, 1, 10, 100}; //最大三位数,所以这里只要百位就满足了。
10 return (x/a[d]) % 10;
11 }
12 void PrintArr(int ar[],int n)
13 {
14 for(int i = 0;i < n; ++i)
15 {
16 cout<<ar[i]<<" ";
17 }
18 cout<<endl;
19 }
20 void lsdradix_sort(int arr[],int begin,int end,int d)
21 {
22 const int radix = 10;
23 int count[radix], i, j;
24
25 int *bucket = (int*)malloc((end-begin+1)*sizeof(int)); //所有桶的空间开辟
26
27 //按照分配标准依次进行排序过程
28 for(int k = 1; k <= d; ++k)
29 {
30 //置空
31 for(i = 0; i < radix; i++)
32 {
33 count[i] = 0;
34 }
35 //统计各个桶中所盛数据个数
36 for(i = begin; i <= end; i++)
37 {
38 count[getdigit(arr[i], k)]++;
39 }
40 //count[i]表示第i个桶的右边界索引
41 for(i = 1; i < radix; i++)
42 {
43 count[i] = count[i] + count[i-1];
44 }
45 //把数据依次装入桶(注意装入时候的分配技巧)
46 for(i = end;i >= begin; --i) //这里要从右向左扫描,保证排序稳定性
47 {
48 j = getdigit(arr[i], k); //求出关键码的第k位的数字, 例如:576的第3位是5
49 bucket[count[j]-1] = arr[i]; //放入对应的桶中,count[j]-1是第j个桶的右边界索引
50 --count[j]; //对应桶的装入数据索引减一
51 }
52
53 //注意:此时count[i]为第i个桶左边界
54
55 //从各个桶中收集数据
56 for(i = begin,j = 0; i <= end; ++i, ++j)
57 {
58 arr[i] = bucket[j];
59 }
60 }
61 free(bucket);
62 }
63
64 void main()
65 {
66 int br[10] = {20, 80, 90, 589, 998, 965, 852, 123, 456, 789};
67 cout<<"原数据如下:"<<endl;
68 PrintArr(br,10);
69 lsdradix_sort(br, 0, 9, 3);
70 cout<<"排序后数据如下:"<<endl;
71 PrintArr(br, 10);
72 }
73 /*
74 原数据如下:
75 20 80 90 589 998 965 852 123 456 789
76 排序后数据如下:
77 20 80 90 123 456 589 789 852 965 998
78 */
注意:以上两种方法我们均用数组模拟桶,关于数组模拟桶详细讲解请参考随笔《桶排序》
【3】基数排序稳定性分析
基数排序是稳定性排序算法,那么,到底如何理解它所谓的稳定特性呢?
比如:我们有如下欲排数据序列:

下面选择LSD逻辑演示
第一次按个位数值分配,结果如下图所示:

然后收集数据结果如下:

第二次按十位数值分配,结果如下图所示:

然后收集数据结果如下:

注意:分配时是从欲排数据序列的末位开始进行,逐次分配至首位。
好吧!排序结束。相信一定一目了然。在此不作赘述。
文章源自:http://www.cnblogs.com/Braveliu/archive/2013/01/21/2870201.html