计算所科研实践随笔
被淹没在论文海里的两个星期。
早上7:10分起床,草草洗漱,7:30出发,开始漫长的1小时通勤。从地铁站的安检口起,队便排的极长,让人看得头皮发麻。下到了轨道旁稍好,但每趟呼啸而来的地铁里都是满满当当,常常要等2,3趟我才能有幸站上去。我从不奢望座位。在等一趟不那么满的地铁的过程中,有时很满的地铁来了,门易开人墙难开,门快关时有些赶得急的人就踏上地铁背过身来拼命地往后压,最后强行挤出了个位置来,我在外面看得见那努力的表情。
虽说这行为不大雅观,素质上可能偏向于负面,但我脑子里总是闪现那句“我用尽了全力,过着平凡的一生”。
地铁门关,轻灵驰走,满载着刚开始新的一天却已有些疲惫的人们。
到了计算所后在负一楼的健康餐吧吃早饭。这是艰难的两个星期里比较安慰我的两样之一。两样一个是计算所的伙食,一个是友善的师兄。
这两周导师给我的任务是RDMA调研。初步了解RDMA技术,找出RDMA小领域里50篇好的论文并每篇写概述(写不出来就翻译摘要),最后写一篇总结与感想。
看论文的过程真的是很难受的。我才刚大一结束,很多基础知识都不知道,论文里使用的大量术语我基本都知形不知义。于是不停wiki,常常wiki里对术语的解释本身便是由术语写就的,我便只好继续wiki。如此树形展开,搜好几层我才能大致明白某个术语的含义。不过挺多时候我都直接叨扰了友善的师兄。
时间与我支付宝里的钱一同流逝着,到了后面,我开始有些浮躁,很多时候都放弃了做通读全文的努力,最后50篇的任务其实完成得挺没有质量的,没什么论文真的看懂了。哎,心不大静。
努力前行。

计算所科研实践报告
一、 RDMA基本原理
一个RDMA传输过程可分为以下几步:
1用户空间的应用使用verbs(含RDMA read (READ), RDMA write (WRITE), SEND,and RECEIVE等多种类型的操作)调用RDMA NICs(RNICs)。
2verbs被发送到RNICs里的队列Queue Pairs(QP)中,Queue Pairs由Send Queue(SQ)和Receive Queue(RQ)构成,QP会被映射到应用的虚拟地址空间,使得应用直接通过它访问RNIC网卡。另外RDMA还提供一种队列Complete Queue(CQ),作用是通知另一端消息已处理完,但会加大RNIC的PCIe bus的开销。
3RNIC之间传输虚拟地址,内存访问权限,数据。
4远端的RNIC解析消息并在无需CPU干预的情况下对远端的虚拟地址执行操作。
在最开始需要两端建立连接,创建并初始化QP。
从而RDMA是一种无需双方操作系统干预的远程内存直接访问技术,有如下优势:
1.零拷贝:应用之间通过RNICs直接进行数据传输,免去了传统方式下用户空间到内核空间的拷贝。
2.无需CPU干预:应用直接访问远程内存,无需消耗远端CPU资源。
3.基于消息的事务:数据被作为离散消息处理,而不是作为流处理,这消除了应用将流分成不同消息/事务的需要。
4.支持分散/收集条目:RDMA支持本地处理多个分散/收集条目,即读取多个内存缓冲区并将其作为一个流或获取一个流并将其写入多个内存缓冲区。
二、 使用的调研方式
- 中国知网搜索:搜到的论文质量较差,舍弃。故没有产生作用。
- RDMA技术标准制定方官网https://www.openfabrics.org/:用于了解技术原理。
- 一个有关RDMA的博客http://www.rdmamojo.com/:用于了解技术原理。
- 维基百科:使用频繁,主要用于查看术语定义。
- Google scholar搜索:主力,大部分论文由此获取。
- 查看论文作者的其他论文:查阅过程中发现Dhabaleswar K.DK Panda作者的名字常常出现,于是查了一下该作者的其他论文。
- 问师兄:非常频繁,帮助很大。
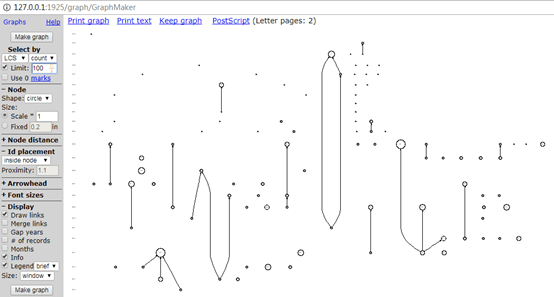
- 后来在中国科学技术大学罗昭锋老师放在科学网的一篇博文《引文分析软件histcite简介》的启发下利用histcite软件分析了Web of Science核心合集数据库中与RDMA相关的约500篇论文,并进行可视化
RDMA与TCP的比较
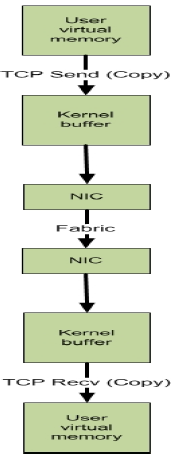
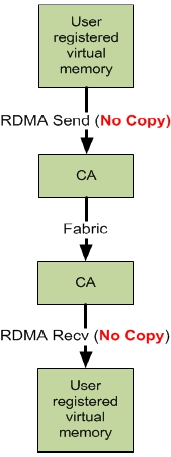
(图来自RDMA技术标准制定方官网https://www.openfabrics.org/的一个培训ppt)
成本上RDMA较贵:
10G普通网卡:Mellanox MCX341A-XCCN ConnectX-3 10Gigabit Ethernet Card
$170.00
Infiniband交换机:Mellanox MCS7510 66Tb/s, 324-port EDR Infiniband chassis switch, includes 12 fans and 6 power supplies (N+N), RoHS R6
$66,950.00
infiniband卡:Mellanox MCX456A-ECAT ConnectX VPI Infiniband Host Bus Adapter
$1,575.00
论文分类:
1.对RDMA读操作的研究
分析RDMA读操作不同情况下的利弊
Dragojevic A, Narayanan D, Castro M. RDMA Reads: To Use or Not to Use?[J]. IEEE Data Eng. Bull., 2017, 40(1): 3-14.
键值对应用中未使用读操作的方案
Kalia A, Kaminsky M, Andersen D G. Using RDMA efficiently for key-value services[C]//ACM SIGCOMM Computer Communication Review. ACM, 2014, 44(4): 295-306.
键值对应用中使用了读操作但做出改进的方案
C. Mitchell, Y. Geng, and J. Li. Using One-Sided RDMA Reads to Build a Fast,
CPU-Efficient Key-Value Store. In USENIX ATC, 2013.
分析发现在广域网上RDMA读操作性能较差
Yu W, Rao N S V, Wyckoff P, et al. Performance of RDMA-capable storage protocols on wide-area network[C]//Petascale Data Storage Workshop, 2008. PDSW'08. 3rd. IEEE, 2008: 1-5.
MPI应用中将Rendezvous Protocol的实现由写操作实现改为使用读操作实现。
Sur S, Jin H W, Chai L, et al. RDMA read based rendezvous protocol for MPI over InfiniBand: design alternatives and benefits[C]//Proceedings of the eleventh ACM SIGPLAN symposium on Principles and practice of parallel programming. ACM, 2006: 32-39.
提出的优化方案中避免RDMA单边操作(RDMA读/写)
Kalia A, Kaminsky M, Andersen D G. FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs[C]//OSDI. 2016: 185-201.
这篇研究RDMA隐藏成本的分析中也有提及:
Author(s): Frey PW (Frey, Philip W.); Alonso G (Alonso, Gustavo)
Title: Minimizing the Hidden Cost of RDMA
Source: 2009 29TH IEEE INTERNATIONAL CONFERENCE ON DISTRIBUTED COMPUTING SYSTEMS : 553-+
Date: 2009
DOI: 10.1109/ICDCS.2009.32
2.对RDMA虚拟化,软件化的研究
这个方向在2011年被提出来一次,作者们研究设计了一个软件RDMA栈,并试图应用在商业云上。
Trivedi A, Metzler B, Stuedi P. A case for RDMA in clouds: turning supercomputer networking into commodity[C]//Proceedings of the Second Asia-Pacific Workshop on Systems. ACM, 2011: 17.
最近又有两篇论文关注这方面的问题:
虚拟化RDMA(新,2017年论文)
Fan S, Chen F, Rauchfuss H, et al. Towards a Lightweight RDMA Para-Virtualization for HPC[C]//COSH/VisorHPC@ HiPEAC. 2017: 39-44.
软件化RDMA。(新,2017年论文)
Mao Miao, Fengyuan Ren, Xiaohui Luo, Jing Xie, Qingkai Meng, and Wenxue Cheng. 2017. SoftRDMA: Rekindling High Performance Software RDMA over Commodity Ethernet. In Proceedings of the First Asia-Pacific Workshop on Networking (APNet'17). ACM, New York, NY, USA, 43-49. DOI: https://doi.org/10.1145/3106989.3106995
3.对RDMA内存管理的研究
一个提高RDMA内存管理效率的方案(一个计算所老师的论文)
Ou L, He X, Han J. An efficient design for fast memory registration in RDMA[J]. Journal of Network and Computer Applications, 2009, 32(3): 642-651.
在MPI应用中一个提高RDMA内存管理效率的方案
Mamidala A, Vishnu A, Panda D. Efficient shared memory and RDMA based design for MPI_Allgather over infiniband[J]. Recent Advances in Parallel Virtual Machine and Message Passing Interface, 2006: 66-75.
设计了一个新协议来Overlap内存管理的开销,跟单边操作(读/写)也有关系
Woodall T, Shipman G, Bosilca G, et al. High performance RDMA protocols in HPC[J]. Recent Advances in Parallel Virtual Machine and Message Passing Interface, 2006: 76-85.
4.将RDMA应用于GPU的研究
以下四篇论文成如上图关系:
第一篇首先提出使用GPUDirect RDMA来实现 Inter-node MPI Communication:
Potluri S, Hamidouche K, Venkatesh A, et al. Efficient inter-node MPI communication using GPUDirect RDMA for InfiniBand clusters with NVIDIA GPUs[C]//Parallel Processing (ICPP), 2013 42nd International Conference on. IEEE, 2013: 80-89.
有3篇跟进:
Wang H, Potluri S, Bureddy D, et al. GPU-aware MPI on RDMA-enabled clusters: Design, implementation and evaluation[J]. IEEE Transactions on Parallel and Distributed Systems, 2014, 25(10): 2595-2605.
Hamidouche K, Venkatesh A, Awan A A, et al. Exploiting GPUDirect RDMA in Designing High Performance OpenSHMEM for NVIDIA GPU Clusters[C]//Cluster Computing (CLUSTER), 2015 IEEE International Conference on. IEEE, 2015: 78-87.
Banerjee D S, Hamidouche K, Panda D K. Designing high performance communication runtime for GPU managed memory: early experiences[C]//Proceedings of the 9th Annual Workshop on General Purpose Processing using Graphics Processing Unit. ACM, 2016: 82-91.
5.将RDMA应用于键值对存储的研究
这篇主要关注安全性问题:
Yang M, Yu S, Yu R, et al. InnerCache: A Tactful Cache Mechanism for RDMA-Based Key-Value Store[C]//Web Services (ICWS), 2016 IEEE International Conference on. IEEE, 2016: 646-649.
提高性能(在RDMA读操作部分中介绍过)
Kalia A, Kaminsky M, Andersen D G. Using RDMA efficiently for key-value services[C]//ACM SIGCOMM Computer Communication Review. ACM, 2014, 44(4): 295-306.
提高性能
C. Mitchell, Y. Geng, and J. Li. Using One-Sided RDMA Reads to Build a Fast,
CPU-Efficient Key-Value Store. In USENIX ATC, 2013.
这个主要是关注基于RDMA的键值对应用中固态硬盘和内存混合存储的问题
Shankar D, Lu X, Islam N, et al. High-Performance Hybrid Key-Value Store on Modern Clusters with RDMA Interconnects and SSDs: Non-blocking Extensions, Designs, and Benefits[C]//Parallel and Distributed Processing Symposium, 2016 IEEE International. IEEE, 2016: 393-402.
6.将RDMA应用于关系数据库的研究
共享内存避免读硬盘,从而提升性能
Li F, Das S, Syamala M, et al. Accelerating relational databases by leveraging remote memory and RDMA[C]//Proceedings of the 2016 International Conference on Management of Data. ACM, 2016: 355-370.
引入MySQL
Shankar D, Lu X, Jose J, et al. Can RDMA benefit online data processing workloads on memcached and MySQL?[C]//Performance Analysis of Systems and Software (ISPASS), 2015 IEEE International Symposium on. IEEE, 2015: 159-160.
加速数据库join操作
Barthels C, Loesing S, Alonso G, et al. Rack-scale in-memory join processing using RDMA[C]//Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. ACM, 2015: 1463-1475.
两篇都是利用RDMA和HTM设计新的Transactions progress system ,作者也一样
Wei X, Shi J, Chen Y, et al. Fast in-memory transaction processing using RDMA and HTM[C]//Proceedings of the 25th Symposium on Operating Systems Principles. ACM, 2015: 87-104.
Chen Y, Wei X, Shi J, et al. Fast and general distributed transactions using RDMA and HTM[C]//Proceedings of the Eleventh European Conference on Computer Systems. ACM, 2016: 26.
加速分布式Transactions时避免了RDMA单边操作
Kalia A, Kaminsky M, Andersen D G. FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs[C]//OSDI. 2016: 185-201.
7.将RDMA应用于大数据系统的研究
将RDMA引入Spark提高性能
Lu X, Rahman M W U, Islam N, et al. Accelerating spark with RDMA for big data processing: Early experiences[C]//High-performance interconnects (HOTI), 2014 IEEE 22nd annual symposium on. IEEE, 2014: 9-16.
与上篇工作类似
Yan X, Wong B, Choy S. R3S: RDMA-based RDD Remote Storage for Spark[C]//Proceedings of the 15th International Workshop on Adaptive and Reflective Middleware. ACM, 2016: 4.
用RDMA解决MapReduce,Spark和HBase的主要存储引擎HDFS的I/O瓶颈,从而提升性能
Islam N S, Rahman M W, Jose J, et al. High performance RDMA-based design of HDFS over InfiniBand[C]//Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis. IEEE Computer Society Press, 2012: 35.
这篇与上篇工作类似
Woodall T, Shipman G, Bosilca G, et al. High performance RDMA protocols in HPC[J]. Recent Advances in Parallel Virtual Machine and Message Passing Interface, 2006: 76-85.
引入Hadoop后的性能分析
Lu X, Islam N S, Wasi-Ur-Rahman M, et al. High-performance design of Hadoop RPC with RDMA over InfiniBand[C]//Parallel Processing (ICPP), 2013 42nd International Conference on. IEEE, 2013: 641-650.
设计了一个插件库帮助Hadoop使用RDMA
Wang Y, Xu C, Li X, et al. JVM-bypass for efficient Hadoop shuffling[C]//Parallel & Distributed Processing (IPDPS), 2013 IEEE 27th International Symposium on. IEEE, 2013: 569-578.
8将RDMA应用于NFS的研究
引入RDMA提高性能,并解决了一个安全性问题。
Noronha R, Chai L, Talpey T, et al. Designing NFS with RDMA for security, performance and scalability[C]//Parallel Processing, 2007. ICPP 2007. International Conference on. IEEE, 2007: 49-49.
将RDMA作为NFS的传输层提高性能
Callaghan B, Lingutla-Raj T, Chiu A, et al. Nfs over rdma[C]//Proceedings of the ACM SIGCOMM workshop on Network-I/O convergence: experience, lessons, implications. ACM, 2003: 196-208.
分析发现基于RDMA的NFS在广域网上性能较差,由于广域网上RDMA读操作性能较差
Yu W, Rao N S V, Wyckoff P, et al. Performance of RDMA-capable storage protocols on wide-area network[C]//Petascale Data Storage Workshop, 2008. PDSW'08. 3rd. IEEE, 2008: 1-5.
9. 将RDMA应用于MPI的研究
Liu J, Wu J, Panda D K. High performance RDMA-based MPI implementation over InfiniBand[J]. International Journal of Parallel Programming, 2004, 32(3): 167-198.
Sur S, Jin H W, Chai L, et al. RDMA read based rendezvous protocol for MPI over InfiniBand: design alternatives and benefits[C]//Proceedings of the eleventh ACM SIGPLAN symposium on Principles and practice of parallel programming. ACM, 2006: 32-39.
- 10. 杂
还有一些研究RDMA编程,给web协议提速,在(IBMHPS (High Performance Switch and adapter)上实现RDMA等等
