-
2.HDFS
一.分布式文件系统
1.分布式文件系统(Distributed File System)概念
-
分布式文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。
2.分布式文件系统特点
-
分布式文件系统是基于Master/Slave模式,通常提供多个供用户访问的服务器。
-
分布式文件系统一般都会提供备份和容错功能。
-
分布式文件系统一般都会基于操作系统的本地文件系统
-
多用户多应用的并行读写是分布式文件系统产生的根源
-
分布式文件系统扩充存储空间的成本低廉,提供冗余备份和分布式计算
3.分布式文件系统结构
-
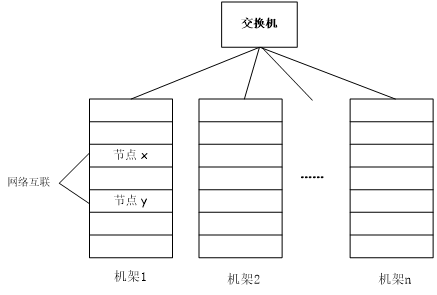
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的。
-
节点分为两类:
-
主节点(Master Node):也被称为名称节点(NameNode)
-
从节点(Slave Node):也被称为数据节点(DataNode)

二.HDFS
1.HDFS概念
-
HDFS:Hadoop Distributed File System
-
HDFS:是一个使用Java实现的、分布式的、可横向扩展的文件系统
-
HDFS:是Hadoop核心组件
2.HDFS的体系结构
-
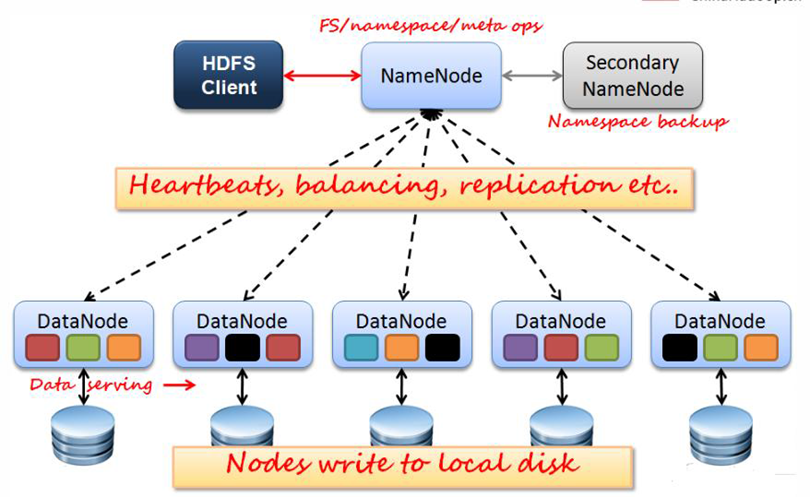
HDFS采用主从结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。
-
名称节点(NameNode):作为中心服务器,负责管理文件系统的命名空间以及客户端对文件的访问。
-
数据节点(DataNode):一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求。
-
名称节点的统一调度下进行数据块的创建、删除和复制等操作。每隔数据节点的数据实际上是保存在本地Linux文件系统中的。

3.HDFS设计目标
-
大数据集:用于存储大量文件,不适合小文件存储。
-
基于廉价的普通硬件,可以容错硬件出错。
-
简单的一致性模型:HDFS应用程序一次写入,多次读取文件的访问模式。
-
顺序的数据流访问:适用于处理批量数据,而不适合随机定位访问。
-
侧重高吞吐量的数据访问,可以容忍数据访问的高延迟。。
4.HDFS的优点
-
高容错性:数据自动备份和自动恢复
-
适合批处理
-
适合大数据处理
-
可构建在廉价机器上
5.HDFS的缺点
-
不适合低延时数据访问:寻址时间长,适合读取大文件
-
不适合小文件存取:寻道时间超过文件读取时间
-
不适合并发写入、文件随即修改:一个文件只能有一个写者,仅支持append(日志)
6.HDFS存储设计思想

7.HDFS架构
8.HDFS核心概念
-
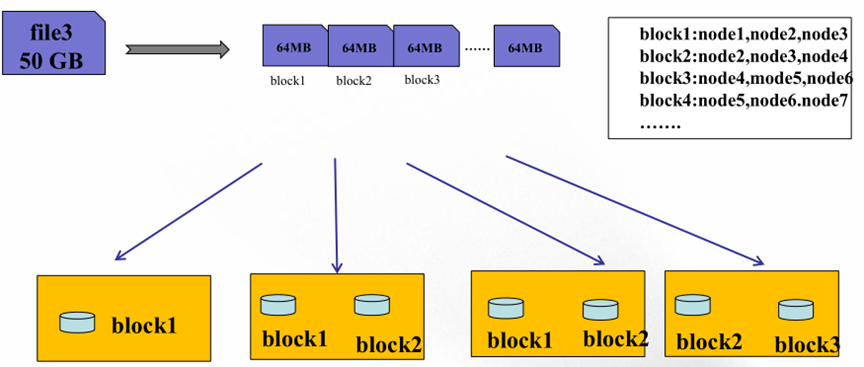
Block:文件被窃氛围固定大小的数据块
-
默认数据块大小为128MB(hadoop2.x),hadoop1.x为64MB,不到128MB单独存成一个block。
-
每个文件分成的block被存储在不同的数据节点上。
-
每个block都有三份副本,相互都是平等的。
-
NameNode(NN):名称节点
-
概念:用于管理文件系统命名空间的组件
-
特点:一个HDFS集群只有一个NameNode,一个命名空间,一个根目录,一份元数据。
-
主要功能:
-
用于接受客户端的读写服务
-
保存metadata数据
-
保存文件的拥有者(ownership)和权限(permissions)
-
保存文件包含的块信息以及块在数据节点的位置(由数据节点启动时上报)
-
DataNode(DN):数据节点,用于存储数据块block
-
启动时需要向NN汇报block信息
-
通过向NN发送心跳保持联系(3秒一次),如果NN在10分钟没有收到DN的心跳,则失去节点,将这个DataNode上存储的Block再备份到其他的节点上保证副本数量。
-
BlockSize是不可变的为128MB,但是副本数量用户可以设置,默认为3个。
-
对于不足128MB数据是不会占用128MB实际空间
-
元数据(metadata):
-
保存在NameNode中,启动后会加载到内存中,用于快速查询
-
主要包括:
-
fsimage:元数据镜像文件,用于保存文件系统的目录树
-
edits:元数据操作日志,用于对目录树的修改操作,被写入共享存储系统中
-
SecondaryNameNode(SNN):
-
功能:帮助NN合并edits,减少NN启动时间,不是NN的备份
-
SNN执行的合并时机:
-
根据配置文件设置的时间间隔fs.checkpoint.period,默认3600秒
-
根据配置文件设置edits log大小fs.checkpoint.size,规定edits文件的最大值默认是64MB
-
NameNode高可用时没有SNN
-
HA支持动态增加DataNode
9.Block的副本防止策略
-
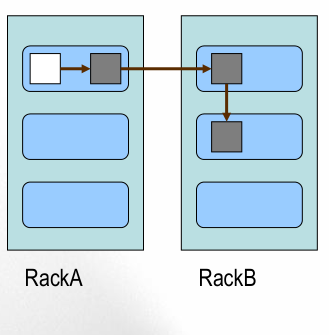
第一个副本:放置在上传文件的DN,如果是集群外提交,则随机挑选一台磁盘不太满、CPU不忙的节点。
-
第二个副本:放置在与第一个副本不同的机架的节点上。
-
第三个副本:与第二个副本相同机架的节点。
-
更多副本:随机节点。
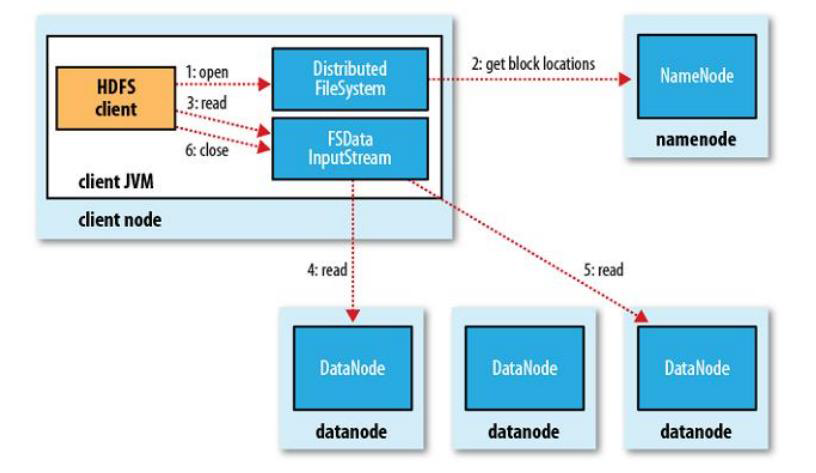
10.HDFS读文件流程
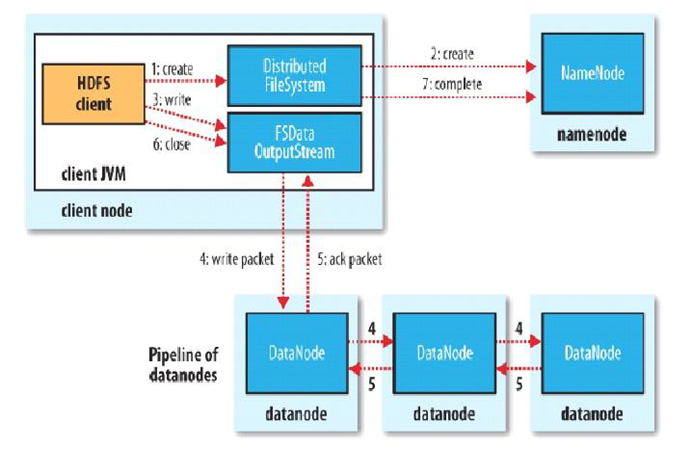
11.HDFS写文件流程
-
相关阅读:
centos安装Libzip
PHP安装
DWZ主从表界面唯一性验证(自写js)(一)
JSTL的if...else项目小试
分享:忙了一辈子,才知道什么是你的
JSTL时间格式化项目小试
eclipse中去掉validate的方法
Java初学者必学的JSTL
(转)Java程序员应该知道的10个调试技巧
为什么那些美事没有实现---生活中小事有感
-
原文地址:https://www.cnblogs.com/zhihaospace/p/12398469.html
Copyright © 2020-2023
润新知