环境:CentOS 7
JDK: 1.7.0_80
hadoop:2.8.5
hadoop(192.168.56.101)
配置基础环境
1. 测试环境可以直接关闭selinux和防火墙
2. 主机添加hosts记录
# vim /etc/hosts 192.168.56.101 hadoop
3. 创建hadoop用户
# useradd hadoop # passwd hadoop
4. 添加免密登陆(如果不添加免密登陆,后面启动服务时候会提示输入密码)
# su - hadoop $ ssh-keygen -t rsa $ ssh-copy-id hadoop@localhost
安装JDK
1. 卸载系统自带的openjdk
yum remove *openjdk*
2. 安装JDK
JDK下载地址:https://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
# tar zxvf jdk1.7.0_80.tgz -C /usr/local/ # vim /etc/profile #添加 export JAVA_HOME=/usr/local/jdk1.7.0_80 export JAVA_BIN=$JAVA_HOME/bin export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH # source /etc/profile # java -version java version "1.7.0_80" Java(TM) SE Runtime Environment (build 1.7.0_80-b15) Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
部署Hadoop
在一台机器上配置,之后拷贝到其他节点主机
1. 安装Hadoop
# su - hadooop $ wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz $ tar zxvf hadoop-2.8.5.tar.gz $ mv hadoop-2.8.5 hadoop #添加环境变量(每个节点都配置) $ vim ~/.bash_profile export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export PATH $ source ~/.bash_profile
2. 配置Hadoop
配置文件在`hadoop/etc/hadoop`目录下
$ cd hadoop/etc/hadoop
#1. 修改core-site.xml
$ vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
# 2. 修改hdfs-site.xml
$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:9001</value>
</property>
</configuration>
# 3. 修改mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# 4. 修改hadoop-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)
$ vim hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/local/jdk1.7.0_80
# 5. 修改yarn-env.sh(如果不声明JAVA_HOME,在启动时会出现找不到JAVA_HOME 错误)
$ vim yarn-env.sh
在脚本前面添加
export JAVA_HOME=/usr/local/jdk1.7.0_80
3. 格式化HDFS
$ hadoop namenode -format
4. 启动服务
$ sbin/start-dfs.sh $ sbin/start-yarn.sh
查看启动情况
$ jps 16321 NameNode 16658 ResourceManager 16511 SecondaryNameNode 16927 Jps
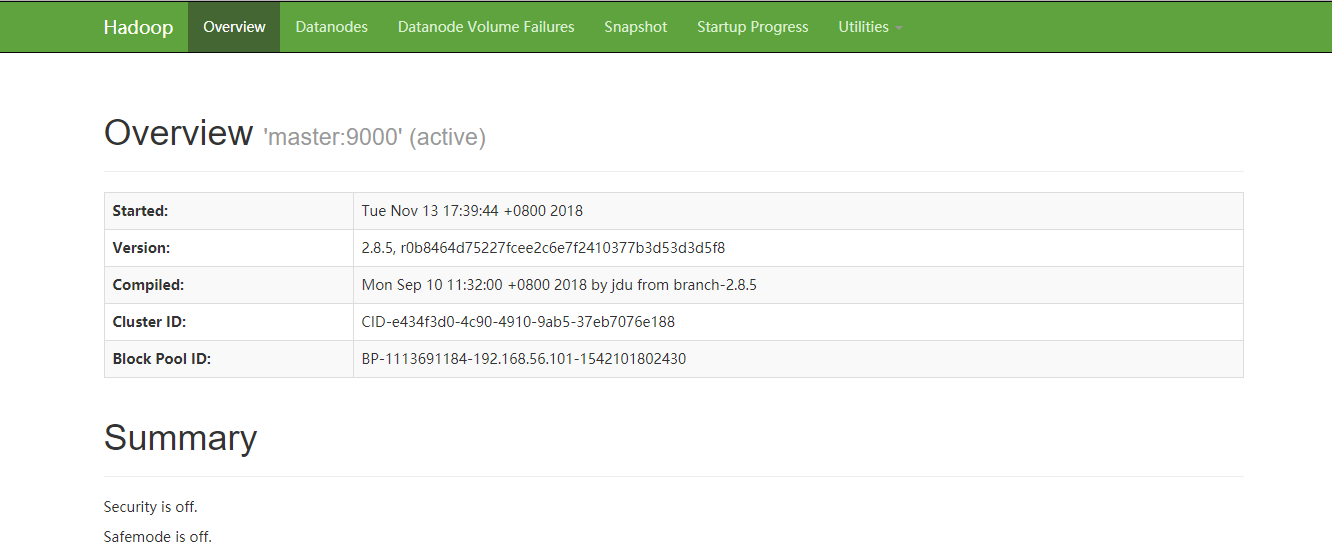
浏览器中访问http://192.168.56.101:50070 查看管理页面
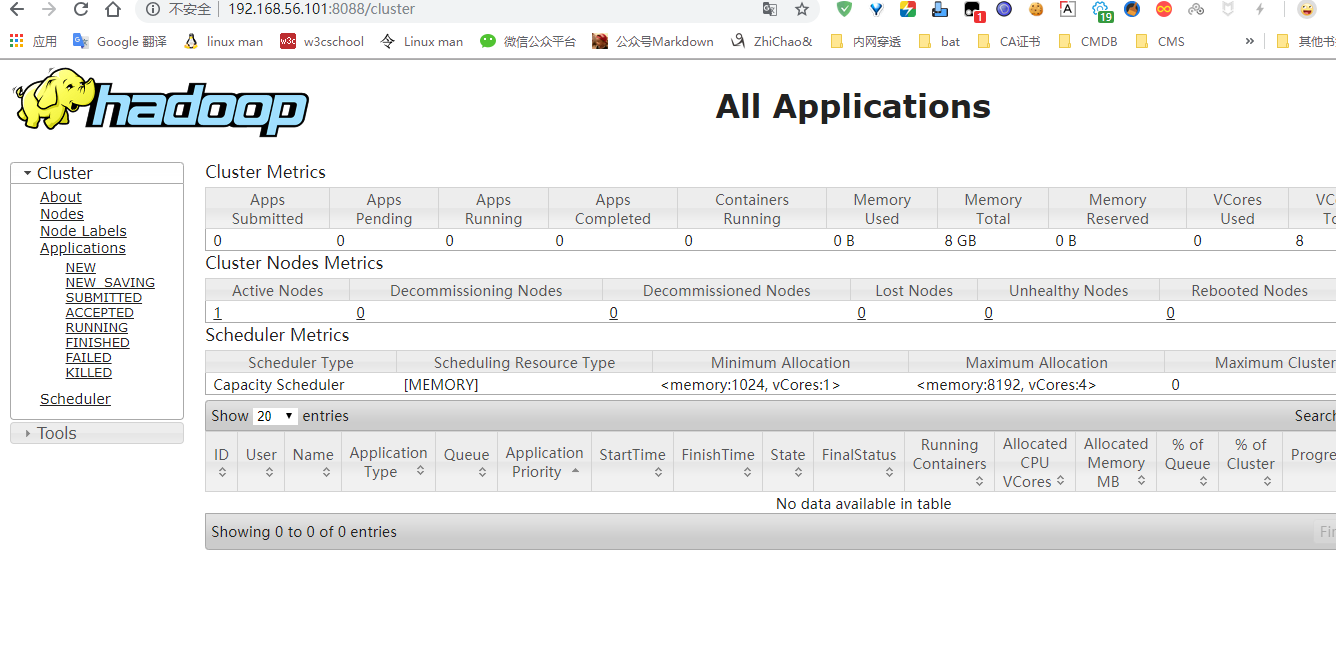
浏览器中访问http://192.168.56.101:8088
测试hadoop使用
