正则表达式用于匹配字符,内嵌在re模块中。
import re
re.match #从开始位置开始匹配,如果开头没有则无
re.search #搜索整个字符串
re.findall #搜索整个字符串,返回一个list
+ 号代表前面的字符必须至少出现一次(1次或多次);
* 号代表字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次);
? 问号代表前面的字符最多只可以出现一次(0次、或1次)。
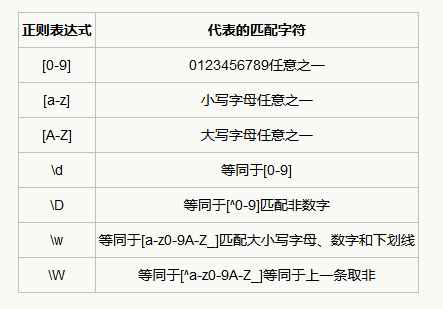
如果在 [ ]里面的开头写一个 ‘^’ 号,则表示取非,即在括号里的字符都不匹配。如 [^a-zA-Z] 表明不匹配所有英文字母。但是如果 ‘^’ 不在开头,则它就不再是表示取非,而表示其本身,如 [a-z^A-Z] 表明匹配所有的英文字母和字符 ’^’ 。
‘|’ 或规则
将两个规则并列起来,以‘ | ’连接,表示只要满足其中之一就可以匹配。比如
[a-zA-Z]|[0-9] 表示满足数字或字母就可以匹配,这个规则等价于 [a-zA-Z0-9]
注意 :关于 ‘|’ 要注意两点:
第一,它在 [ ] 之中不再表示或,而表示他本身的字符。如果要在[ ] 外面表示一个 ’|’ 字符,必须用反斜杠引导,即 ’/|’ ;
第二,它的有效范围是它两边的整条规则,比如‘ dog|cat’ 匹配的是‘ dog’ 和 ’cat’ ,而不是 ’g’ 和 ’c’ 。如果想限定它的有效范围,必需使用一个无捕获组 (?: )包起来。比如要匹配 ‘ I have a dog’ 或 ’I have a cat’ ,需要写成 r’I have a (?:dog|cat)’ ,而不能写成 r’I have a dog|cat’
--------------------- 本文来自 hurt-- 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/weixin_40907382/article/details/79654372?utm_source=copy