---恢复内容开始---
数据库范式(Normal forms):是用于规范关系型数据库设计,以减少谬误发生的一种准则。
尽管有很多概念定义性的东西,但是在实际使用数据库的过程中仍然有很多不尽人意的地方,下面我通过一些实例和图片简要分析一下范式的特点,也是我对范式的一下个人的理解。本篇随笔我们主要通过第一范式(1nf),第二范式(2nf),第三范式(3nf)和bcnf范式,其中我们重点关注的就是第一范式。
第一范式,第一范式是关系型数据库的基础条件,我将1nf的特点归纳为以下几点:
1.不允许出现重复的行;
2.没有重复的列;
3. 每列(或者每个属性)都是不可再分的最小数据单元,即符合原子性;
举例说明:列值中含有分隔符或者属性字符串意义相同。
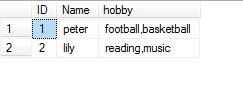
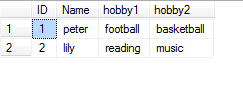
不难发现第一个图中爱好这一列可以分解为两列,如右图中所示,但是这样就不符合1nf要求的列不可再分的要求,右图也不符合没有重复列的要求,不符合1nf。
符合第一范式应该如下图所示(同时去掉第一个表的爱好字段):
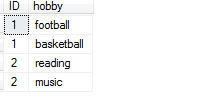
那么符合第一范式带来的好处:减少了代码的繁琐(比如Substring等的频繁使用),提高了查询的效率,方便使用关键字搜索,提高了数据库的性能。
第二范式,2nf依赖1nf,所以2nf必须符合1nf,然后第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
举例说明: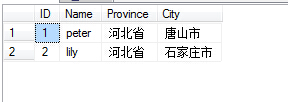
如图所示,我们将Name和City两个属性作为主键,省份这个字段依赖于城市这个字段,同时不依赖于Name这个字段,根据城市可以确定省份。省份跟Name没有关系不符合第二范式。
应该将省市单独拿出来独立成表(AddressID,Province,City),主表则变成(ID,Name,AddressID),通过AddressID关联。解决了可能存在的数据冗余、插入、删除和更新异常。
第三范式,消除对主键的传递依赖,简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
下面我直接给大家看一个正确的第三范式的例子:
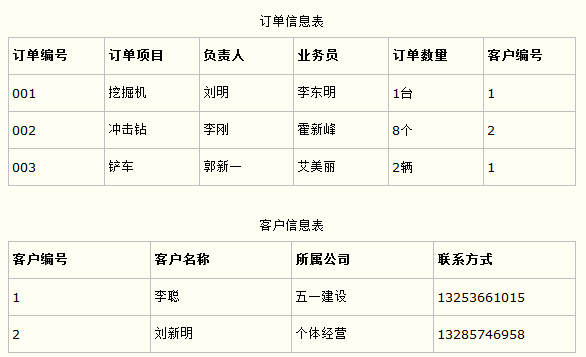
所谓传递依赖就是这样的逻辑:订单编号-》客户编号-》客户名称...这样的依赖不应该在一个表里面(主键是订单编号),如图,客户名称、所属公司、联系方式,依赖于客户编号,分解成两个表以后消除了非主键的传递依赖。
BCNF(Boyce-Codd normal form),在3NF的基础上,表中任何字段对任一候选关键字段的传递函数依赖都不存在。
定义:任何F可推导出的函数依赖X->A都在T中,这里A是不在X中的单一属性,X必须是T的一个超键。当一个数据库模式包含的所有表都符合BCNF时,这个数据库被称为符合BCNF.---这东西实在是太晦涩了。
我的理解:它要求关系模型中所有的属性(包括主属性和非主属性)都不传递依赖于任何候选关键字。也就是说,当关系型表中功能上互相依赖的那些列的每一列都是一个候选关键字时候。
UserID Name ProductID UserEmail ProducName
1 tom 1 ttt@sina.com box
首先拆分成两个表
UserID Name UserEmail
1 tom ttt@sina.com
ProductID ProducName
1 box
这样没有任何主属性和非主属性的传递依赖了,但是缺少的是UserID 和ProductID的关系,我们还要加入关系表
UserID ProductID
1 1
总结:就关系数据库而言,从其他元素中消除数据冗余问题,去除重复往往以减少冗余, 从特定的表中最小化冗余意味着摆脱不必要的数据。 在商业环境中,绝大多数超越第3范式的设计都是不切实际的。 由范式的进阶来看,越高等级的范式所产生的表越多,而在应用程序使用的过程中越多的表Join和查询造成的性能损耗的问题,甚至很多情况下为了兼顾性能和开发我们甚至要做一下反范式的操作,这个我准备接下来单独说一下。
一般认为超过第三范式都是多余的,所以再实际工作中不能太过教条,这里讨论更多是理解概念的一些讨论,通过总结以上这些概念帮助我们更好的设计,但是只有按照实际需求来设计才是王道。哈哈