Ng的机器学习课,课程资源: cs229-课件 网易公开课-视频
问题数学模型:
马尔科夫过程五元组{S、a、Psa、γ、R},分别对应 {状态、行为、状态s下做出a行为的概率、常数、回报}。
一个简化的例子如下,假设移动机器人可以有如下位置,中间画×处不能走,目标是左上角,不希望走左上第二个格子:
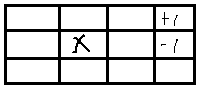
那么机器人可以有11个状态S;在每个状态上都可以往四个方向走,因此a={N,S,W,E};
为了给机器人正确的奖励惩罚政策,给定左上角位置的回报为+1,左上第二个格子回报为-1,其他格子-0.01(为了让机器人尽快走到目标点)。
γ是常数,这里给0.99。
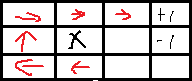
红色箭头表示一个策略。
优化目标:
选择一个策略π(policy)以获得最佳报酬:E[R(s0)+γR(s1)+γ2R(s2)+......],常数γ的存在可以保证尽量快地获得收益。
为此定义value function:给定初始状态s0,选择一个策略π使得收益最大。
优化函数:
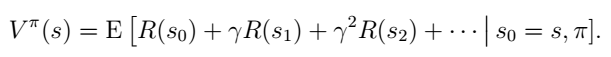
根据贝尔曼方程,
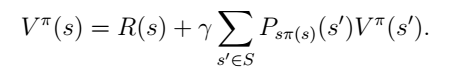
R(s)表示执行此策略获得的直接收益,后面那一堆是执行了此策略以后在后面的行为获得的收益。
最优策略满足:
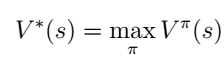
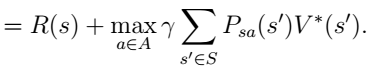
那么在s状态下的最优策略是满足以下等式的行为:
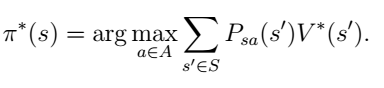
这样,就可以迭代计算了。
求解方法:
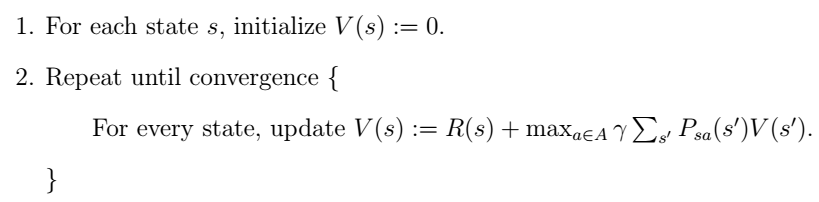
但实际操作中Psa是未知的,所以需要先统计次数,针对课上举的机器人移动的例子,Ng解释说可以先让机器人随便走,统计到达每个状态的次数。
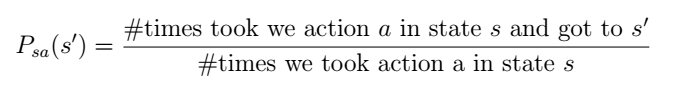
所以强化学习的完整实现过程是这样:

之前的课件到这里就结束了,但现实世界中的问题极其复杂,是无法简化成上述格子的,看今年更新的课件又加了好几页,讲离散化和维度灾难and so on.
扩展:
以自动驾驶汽车为例,车子的状态是连续变化的,离散化以后维度也是大大的,解决方案是给定一个状态转换模型:
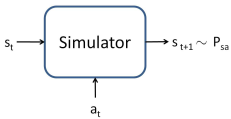
未完待续,不知道什么时候续。
2017.12.02
最近在看图像处理相关的东西,想了一下机器学习、机器视觉之间的关系,机器学习更接近于提供一个原理性的东西,机器视觉选用各种工具来解决这个问题,进而想到,搞机器学习其实还是人在学习,你去学习这个世界的表达方法、演化规则,然后让机器帮你实现。