学习参考:Python3网络爬虫开发实战
lxml、 Beautiful Soup、 pyquery
4.1 使用 XPath

//title[@lang='eng'] :它代表选择所有名称为 title,同时属性 lang 的值为 eng 的节点
from lxml import etree
html = etree.HTML() # 调用HTML类进行初始化
result = etree.tostring(html) # 输出修正后的HTML代码,结果为bytes类型
print(result.decode('utf-8')) # 转bytes类型为str类型
text()可以获取节点内部文本 ,用@符号获取节点属性
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="li"]/a/text()')
print(result)
li 节点的 class 属性有两个值 li 和 li-first,此时如果还想用之前的属性民 配获取,就无法匹配了。
result =html.xpath(’//li[l]/a/text()’) print(result) result = html.xpath(’//li[last()]/a/text()’) print(result) result = html.xpath(’//li[position()<3]Ia/text()’) print (result) result = html.xpath(’//li[last()-2]/a/text()’) print(result)
第一次选择时,我们选取了第一个 li 节点,中括号中传入数字 l 即可 。 注意,这里和代码中不 同,序号是以 1开头的,不是以 0开头。
第二次选择时,我们选取了最后一个 li 节点,中括号中传入 last()即可,返回的便是最后一个 li节点。
第 三 次选择时,我们选取了位置小于 3 的 li 节点,也就是位置序号为 l 和 2 的节点,得到的结果 就是前两个 li节点。
第四次选择时,我们选取了倒数第三个 li 节点,中括号中传入 last()-2 即可 。 后一个,所以 last()-2就是倒数第三个
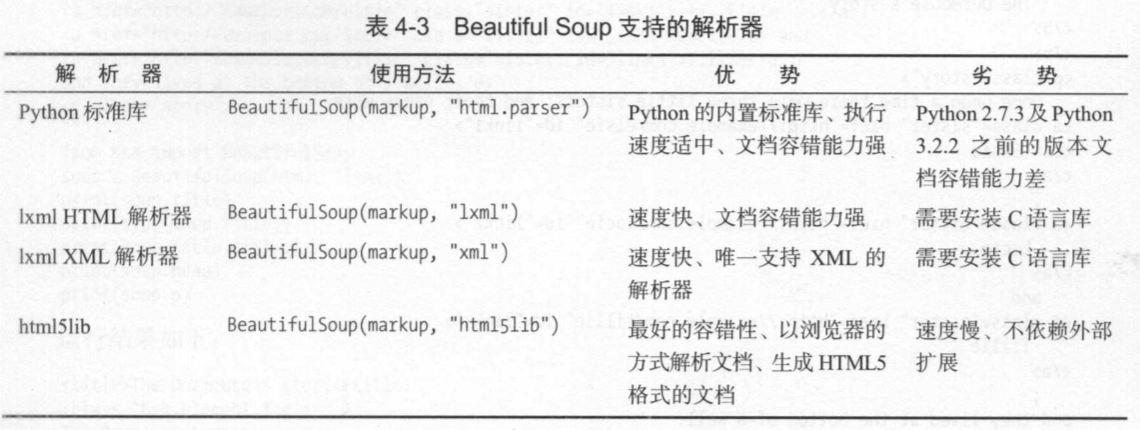
4.2 使用 Beautiful Soup
Beaut1也lSoup 自动将输入文档转换为 Unicode编码,输出文档转换为 UTF-8编码。 你不 需妥考虑、编码方式 ,除非文档没有指 定一个编码方式,这时你仅仅需妥说明一下原始编码方 式就可以了。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>hello</p>','lxml') #BeaufulSoup对象的初始化 如果使用lxml为解析器,那么第二参数用‘lxml’,同理其他一样
print(soup.p.string) # 读取p节点,调用string得到里面的文本
调用 prettify()方法。 这个方法可以把要解析的字符串以标准的缩进格式输出 。 这里需要 注意的是,输出结果里面包含 body和 html节点,也就是说对于不标准的 HTML字符串 BeautifolSoup, 可以自动更正格式 。 这一步不是由 prettify()方法做的,而是在初始化 Beautifol Soup 时就完成了 。
调用soup.title.string,这实际上是输出 HTML 中 title 节点的文本内容,所以,soup.title 可以选出 HTML 中的 title 节点,再调用 string 属性就可以得到里面的文本了。
调用 string 属性来获取文本的值
调用 name属性就可以得到节点名称
调用 attrs 获取所有属性 ,或者直接在节点元素后面加中括号,传入属性名就可以获取属性值。
parent属性,获取某个节点的父节点
parents 获取某个节点所有祖先节点,返回结果是生成器类型
next_sibling和previous_sibling分别获取下一个和上一个兄弟节点
next_siblings 和 previous_siblings 则分别返回所有前面和后面 的兄弟节点的生 成器
find all,顾名思义,就是查询所有符合条件的元素 。
attrs 除了根据节点名查询,我们也可以传入一些属性来查询 attrs 参数,参数的类型是字典类型
text参数可用来匹配节点的文本 ,传入的形式可以是字符串,可以是正则表达式对象
find()方法,只不过后者返回的是单个元素 ,也就是第一个匹配的元 素
find_parents()和find_parent(): 前者返回所有祖先节点, 后者返回直接父节点。
find_next_siblings()和find_next_sibling(): 前者返回后面所有的兄弟节点 , 后者返回后面
第一个兄弟节点
find_previous_siblings()和find_previous_sibling(): 前者返回前面所有的兄弟节点, 后者
返回前面第一个兄弟节点 。
find_all_next()和 find_next(): 前者返回节点后所有符合条件的节点,后者返回第一个符合 条件的节点
find_all_previous()和 find_previous():前者返回节点后所有符合条件的节点,后者返回第 一个符合条件的节点
7. css 选择器
使用 css选择器时,只需要调用 select()方法,传人相应的 css选择器即可 .
print(soup.select(’ul li’))
select(’ul li')则是选择所有 ul节点下面的所有 li节点,结果便是所有的 li节点组成的列表
for ul in soup.select('ul'):
print(ul. select(' li'))
select()方法同样支持嵌套选择。 例如,先选择所有 ul节点,再遍历每个 ul节点,选择其 li节
4.3 使用 pyquery
2. 初始化
·字符 串初始化
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('li'))
•URL 初始化
from pyquery import PyQuery as pq
doc = pq(url='http://cuiqingcai.com')
print(doc('title'))
·文件初始化
除了传递 URL,还可以传递本地的文件名, 此时将参数指定为 干ilename 即可
3. 基本 css 选择器
from pyquery import PyQuery as pq
doc = pq(html)
print(doc(’#container .list li’))
传入了一个 css选择器#container .list li,它的意思是先 选取 id 为 container 的节点,然后再选取其内部的 class 为 list 的节点内部的所有 li 节点 。
4. 查找节点
·子节点
find()方法会将符合条件的所有节点选择出来,结果的类型是 PyQuery 类型 。
其实干 ind()的查找范围是节点的所有子孙节点,而如果我们只想查找子节点,那么可以用 children()方法
·获取属性
提取到节点之后,我们的最终目的当然是提取节点所包含的信息了 。 比较重要的信息有两类, 一 是获取属’性,二是获取文本
调用 attr()方法来获取属性