Oracle 在进行dmp备份和还原的时候,服务器端字符集和客户端字符集会对这个过程有较大影响,特别是数据表中存储了中文、存储过程中使用了中文编码(注释)的时候,如果没有处理好字符集的问题,在进行还原的时候就会遇到问题,我所遇到过的问题有一下几种:
1:导入后数据表中存储的中文字符成了乱码;
2:导入后存储过程中的中文字符成了乱码;
3:导入时,提示某些存储过程不存在,报IMP-00098 INTERNAL ERROR:impccr2错误:

其中问题1出现的原因是源数据库使用的字符集和你现在导入的目标数据库字符集不一致,且目标数据库字符集不是源数据库字符集的超集。解决办法是修改目标数据库的字符集(这个字符集是在创建数据库实例的时候设置的),改成和源数据库一致,再执行导入操作,可以解决数据表中中文字符乱码问题。
问题2和问题3的解决办法,修改客户端字符集,检查你的系统环境变量NLS_LANG的值或者注册表HKEY_LOCAL_MACHINE-->SOFTWARE-->ORACLE 在这个分支下面找NLS_LANG键,修改这个键值再重新导入数据即可。
最后我们需要知道字符集应该改成什么?
方法一:去源数据库上查询
需要用到的视图: nls_database_parameters、props$、v$nls_parameters
方法二:查看导入的时候sqlplus中的提示信息:
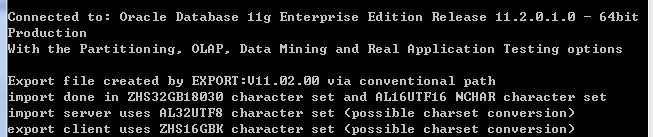
最后一行可以看到,export client uses ....也就是说导出客户端使用的字符集是ZHS16GBK,而且根据当前的设置,是有可能进行字符集的转换(也就意味着有可能出现乱码,如果现在用的字符集不是导出字符集的超集)。所以这里就用该把导入数据库客户端字符集设置成ZHS16GBK,再执行导入可以解决问题。
网上有些办法是修改dmp文件,个人认为,如果是目标数据库端字符集不满足要求,可以采用这种方法修改dmp文件,毕竟server端字符集不能随便更改(生产server一个实例下可能有多个应用系统的用户数据)。如果是客户端字符集问题,建议还是修改一下客户端字符集配置,等导入完成之后再把客户端字符集修改回来。