原文出处:
https://cloud.tencent.com/developer/article/1666445
大作——找灵感,用大作,一个比较知名的素材类网站,里面涵盖多行业图片素材,类似于花瓣网,发现这种类型的素材网站还是比较多的,Python大作网图片采集下载,多线程图片爬虫,多线程的方式是以前最早玩的线程池的方式实现的,但是发现好像容易出错。

同样的抓包分析图片数据
发现数据还是比较多,我们耐心查找入口

对应的json数据,一目了然
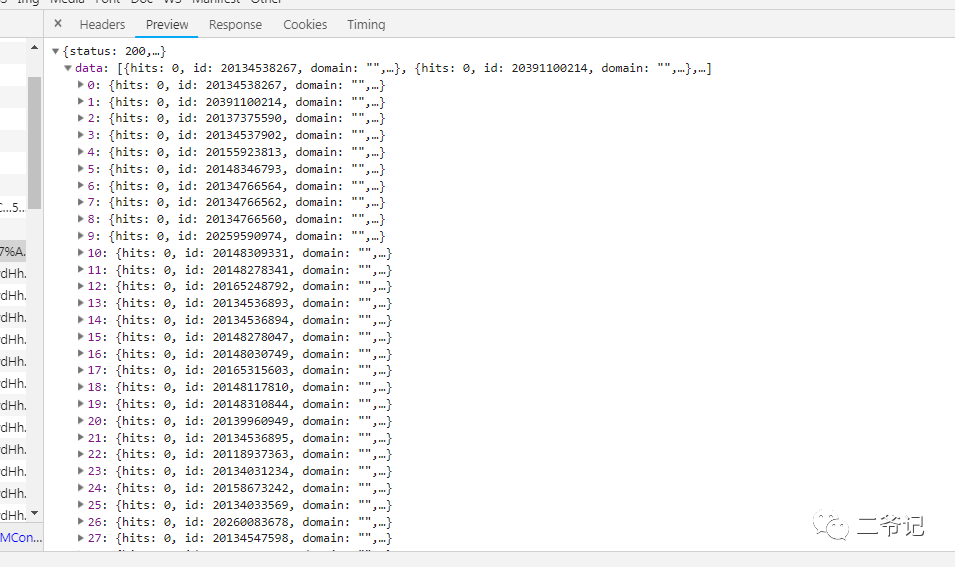
大作网图片地址还做了反爬处理,其实一般都是加一个refer地址就能搞定!
关于图片数据,我们也可以通过浏览器抓包,清晰的看到
'referer': 'https://www.bigbigwork.com/tupian/image/20148309331.html',
一般添加上这个字段就能顺利爬取下载图片
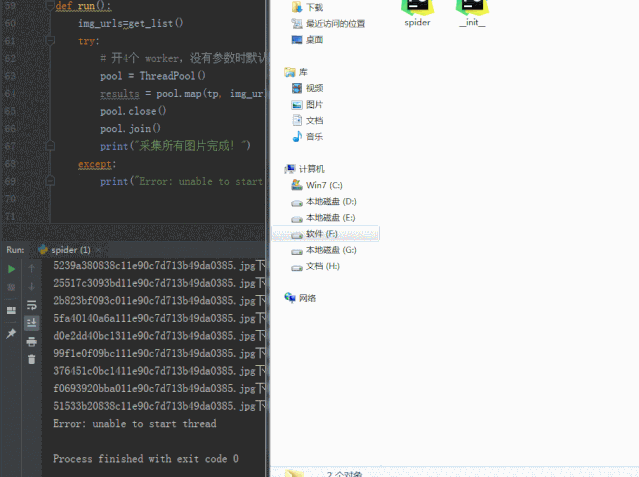
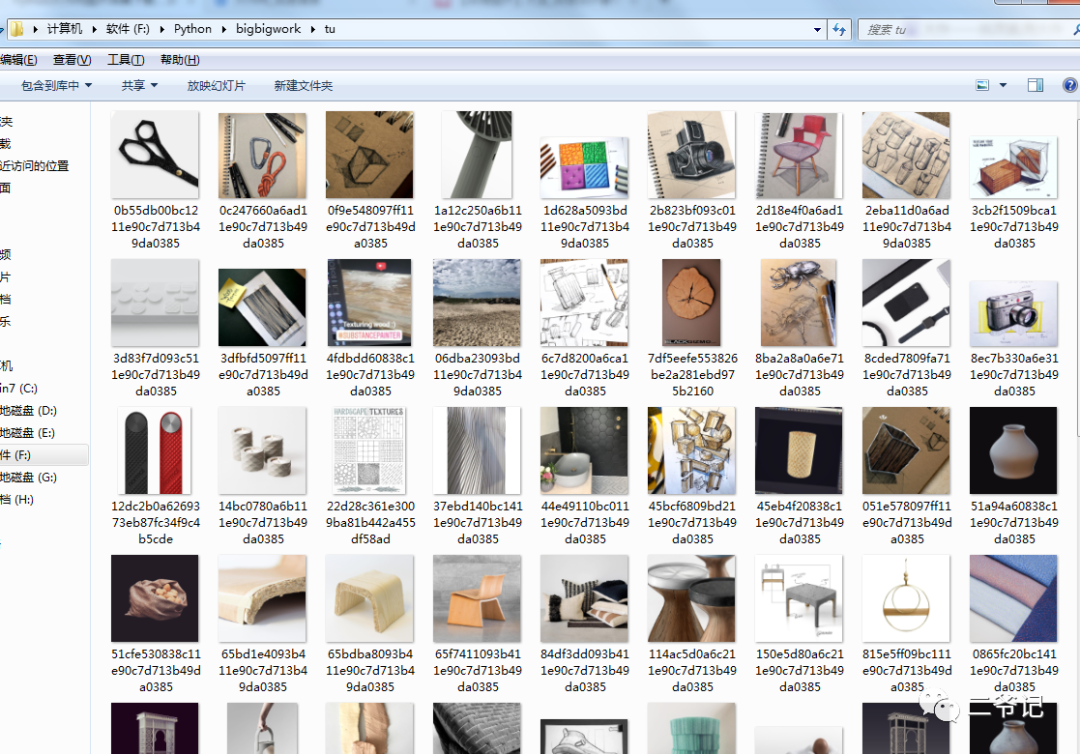
运行效果:
附源码:
#大作网采集 # -*- coding: UTF-8 -*- import requests,time,json from fake_useragent import UserAgent from multiprocessing.dummy import Pool as ThreadPool def ua(): ua=UserAgent() headers={"User-Agent":ua.random} return headers def get_list(): img_urls=[] url="https://www.bigbigwork.com/q?w=texture%20patterns&c=%E7%BA%B9%E7%90%86&h=%E5%B7%A5%E4%B8%9A%E8%AE%BE%E8%AE%A1" response=requests.get(url,headers=ua(),timeout=6).content.decode('utf-8') time.sleep(1) response_dict=json.loads(response) print(len(response_dict['data'])) datas=response_dict['data'] for data in datas: img_urls.append(data['bUrl']) return img_urls #单线程 def tps(img_urls): ua = UserAgent() headers = { 'referer': 'https://www.bigbigwork.com/tupian/image/20148309331.html', 'User-Agent': ua.random, } i=1 for img_url in img_urls: r = requests.get(img_url,headers=headers,timeout=6) time.sleep(1) with open(f'{i}.jpg','wb')as f: f.write(r.content) print("下载图片成功") i=i+1 #多线程调用版本 def tp(img_url): ua = UserAgent() headers = { 'referer': 'https://www.bigbigwork.com/tupian/image/20148309331.html', 'User-Agent': ua.random, } img_name=img_url.split('/')[-1] r = requests.get(img_url,headers=headers,timeout=6) time.sleep(1) with open(img_name,'wb')as f: f.write(r.content) print(f"{img_name}下载图片成功") def run(): img_urls=get_list() try: # 开4个 worker,没有参数时默认是 cpu 的核心数 pool = ThreadPool() results = pool.map(tp, img_urls) pool.close() pool.join() print("采集所有图片完成!") except: print("Error: unable to start thread") if __name__=='__main__': run()